

NEXIs Marktposition im Finanzwesen
Als Teil der NEXI-Gruppe ist NEXI Croatia eines der führenden PayTech-Unternehmen in Europa und bietet schnelle und sichere Zahlungslösungen für Menschen, Unternehmen und Finanzinstitute in mehr als 25 Ländern. Das Unternehmen nimmt auch den ersten Platz in Bezug auf die Anzahl der verwalteten Zahlungskarten und den gesamten bearbeiteten Transaktionswert ein. Bei fast 3 Milliarden aktiven Kreditkarten weltweit wächst die Zahl der Betrugsversuche kontinuierlich.
Modernisierung der Fraud Detection Abläufe
CROZ wurde beauftragt, die Fraud Detection-Funktionen von NEXI Kroatien durch den Einsatz von maschinellem Lernen und Technologien zur Prozessautomatisierung zu optimieren. Das bestehende System stieß auf vier wesentliche Herausforderungen:
- Schwer zu bewältigende Datenmengen
- Veraltete technische Infrastruktur
- Sinkende Genauigkeit der Erkennungsmodelle
- Fehlende Capabilities bzgl. Real-Time Machine Learning
Die großen Datenmengen führten dazu, dass die Berechnung der wichtigen Datenparameter sehr lange dauerte und die Qualität dieser Daten begrenzt war. Auch die technische Umgebung war nicht leistungsfähig genug, was den Berechnungsprozess verlangsamte.
NEXIs System verwendete veraltete Modelle, die Schwierigkeiten hatten, komplexe Betrugsmuster zu erkennen. Es konnte nur auf einen kleinen Datensatz zugreifen, was zu einer Verschlechterung der Genauigkeit führte. Ohne automatisierte Prozesse war die Pflege und Aktualisierung der Modelle sehr zeitaufwändig.
Außerdem konnte das System nur kurzfristige Daten nutzen und keine langfristigen Muster im Verhalten von Nutzern und Händlern erkennen. Obwohl es nahezu in Echtzeit Betrug erkannte, war die Technik nicht in der Lage, die fortschrittlicheren Modelle zu unterstützen, die für eine moderne Betrugserkennung nötig sind.
CROZ half NEXI Kroatien, diese Probleme zu lösen und mehrere Verbesserungen umzusetzen.
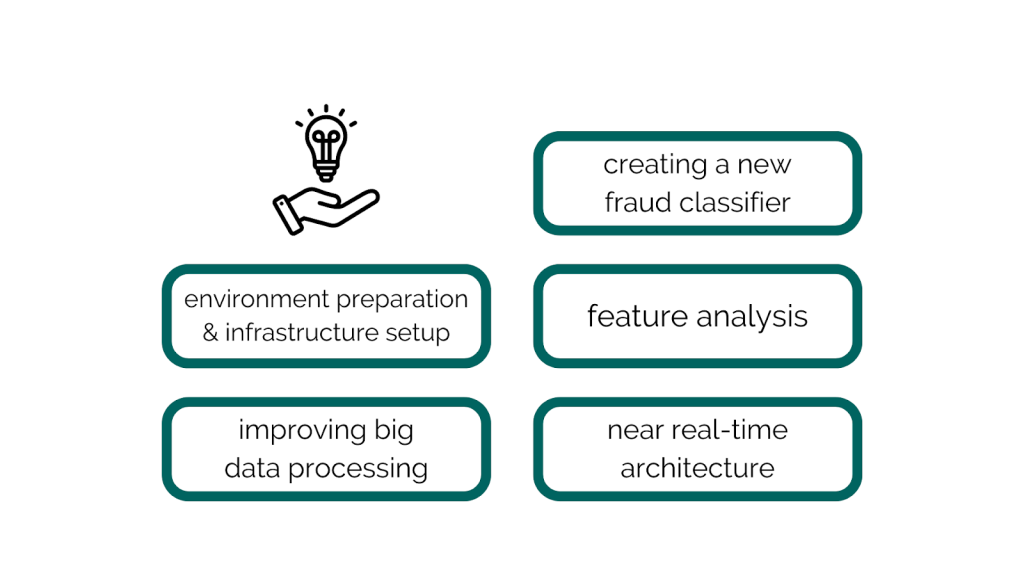
- Vorbereitung der Umgebung und Einrichtung der Infrastruktur: Installation aller benötigten Werkzeuge zur Entwicklung der Lösung, Verarbeitung großer Datensätze, Berechnung langfristiger Zusammenfassungen und Training der ersten Modelle.
- Verbesserung der Big-Data-Verarbeitung: Vorbereitung des finalen Datensatzes, indem große Rohdaten verarbeitet und komplexe Merkmale wie kurzfristige und langfristige Datenaggregationen integriert werden. Diese Zusammenfassungen decken Zeiträume von 5 Minuten bis 9 Monate ab. Der Datensatz wird in Trainings- und Testsets unterteilt und verarbeitet, um Ungleichgewichte im Datensatz zu verringern.
- Erstellung eines neuen Betrugs-Klassifikators: Experimentieren mit modernen Modellen und Anpassen ihrer Parameter. Training der Klassifikatoren mit den vorbereiteten Trainingssets. Evaluierung der Modelle anhand von Standardmetriken wie Genauigkeit, Präzision und F1-Score sowie business-spezifischen Metriken (z. B. Anzahl und Wert der entdeckten Betrugsfälle).
- Merkmalsanalyse: Analyse aller berechneten Merkmale, Bestimmung ihrer Wichtigkeit und Relevanz. Kategorisierung der Merkmale in geschäftsrelevante Kategorien und deren Ranking.
- Nahezu Echtzeit-Architektur: Entwurf und Planung der Architektur, die zur Berechnung von Merkmalen und Klassifizierung von Transaktionen in nahezu Echtzeit verwendet werden soll.
Anpassung an zukünftige Bedürfnisse mit OpenShift AI
In Phase 2 des Projekts wurden OpenShift und OpenShift AI strategisch in die Architektur des Kunden integriert, um die Nutzung fortschrittlicher Technologien zu ermöglichen.
Durch diese Implementierung können die Data Scientists des Kunden nun eigenständig ihre Arbeitsumgebungen einrichten und nahtlos mit verschiedenen Modellen und Parametern experimentieren. Mit dieser Infrastruktur ist es möglich, Pipelines für wiederkehrende Aufgaben wie das automatische Modell-Training und das Logging im Modell-Register effizient zu erstellen, was eine konstante Leistung und Skalierbarkeit sicherstellt.
Die Integration von OpenShift in die Architektur der Fraud Detection hat den Kunden auf die weitere Modernisierung und den Übergang zu einer Microservices-basierten Architektur vorbereitet. Dies ermöglicht den Einsatz einer skalierbaren, fehlertoleranten Infrastruktur, die die Komplexität moderner Anwendungen effizient bewältigen kann. Durch die Einführung von GitOps-Prinzipien wurden zahlreiche operative Aufgaben automatisiert, was den manuellen Aufwand erheblich reduzierte und die Zuverlässigkeit der Bereitstellungen verbesserte.
Zusätzlich wurde eine nächtliche Neuberechnung langfristiger Merkmale eingeführt, um die Genauigkeit und Relevanz der Modelle langfristig zu gewährleisten. Zur weiteren Optimierung der Lösung wurden moderne Streaming- und KI-Technologien wie Kafka und Flink integriert, um ein robustes, skalierbares und Echtzeit-Datenverarbeitungsframework zu schaffen.
Dieser Ansatz unterstützt nicht nur die aktuellen Anforderungen des Kunden, sondern positioniert ihn auch optimal für zukünftige Innovationen im Bereich KI und Daten. Mit diesen Technologien wurde eine leistungsstarke, flexible und zukunftssichere Lösung entwickelt, die perfekt mit der digitalen Transformationsstrategie des Kunden harmoniert.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.



