Die Feinabstimmung dieser Modelle erfordert den Zugriff auf umfangreiche, aussagekräftige und qualitativ hochwertige Datensätze. Falls solche Datensätze jedoch nicht verfügbar sind, ist es am besten, sie mithilfe von KI zu synthetisieren. Bei der Generierung von Programmiercode oder streng formatierten Texten ist es besonders wichtig, dass das finale Modell sowohl syntaktisch als auch semantisch korrekte Ergebnisse liefert. Schon kleine Abweichungen in der Syntax können erhebliche Probleme verursachen: Ein einziger Fehler kann das Vertrauen der Nutzer in den KI-Assistenten untergraben, schwer auffindbare Bugs verursachen oder im schlimmsten Fall die gesamte Lösung unbrauchbar machen. Daher ist ein präziser, methodischer Ansatz sowohl bei der Problemdefinition als auch bei der Erzeugung exakter Lösungen unerlässlich.
Kombinierter Ansatz zur synthetischen Datensatzgenerierung mit LLMs und automatisierter Code-Generierung
To address the challenge of generating correct and reliable code using LLMs, we developed a structured apUm die Herausforderung zu bewältigen, mithilfe von LLMs korrekten und zuverlässigen Code zu generieren, haben wir einen strukturierten Ansatz entwickelt, der sowohl die Problemstellungen als auch die Lösungen synthetisch erstellt. Unser Vorgehen umfasst folgende Schritte:
- Definition des Problemraums: Zuerst legen wir die Regeln fest, die den Problemraum umreißen, den wir adressieren möchten. Diese Regeln umfassen sowohl die Einschränkungen als auch die Bausteine, die zur Lösung jedes Problems verwendet werden können.
- Erstellung einer Prompt-Sammlung zur Abbildung von Kernaufgaben: Innerhalb dieses Problemraums entwickeln wir eine sorgfältig ausgewählte Sammlung von Prompts, die dazu dient, die häufigsten Aufgabenstellungen und zentralen Herausforderungen abzubilden.
- Erweiterung des Problemdatensatzes mithilfe eines LLMs: Anschließend verwenden wir ein leistungsstarkes cloud-basiertes LLM, das anhand der Kern-Prompts eine größere Anzahl verwandter, aber neuartiger Problemstellungen generiert.
Für jede dieser Problemstellungen wenden wir dann den im folgenden Diagramm dargestellten Prozess an:
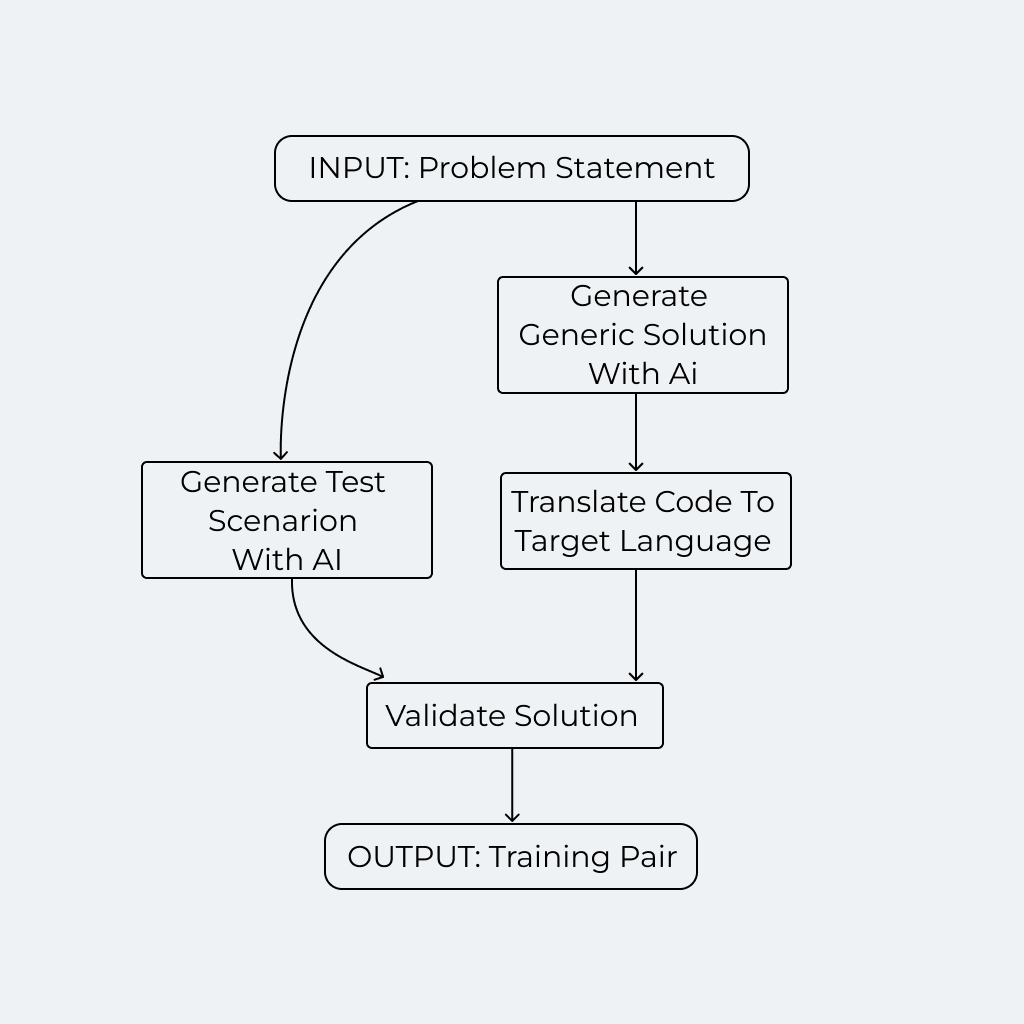
Schauen wir uns nun jeden Schritt genauer an:
- Generierung generischer Lösungen mit KI: Zunächst verwenden wir ein leistungsfähiges cloud-basiertes LLM, um eine generische Lösung zu erstellen. Diese Lösung wird in Form eines abstrakten Baums strukturiert, der mithilfe eines JSON-Schemas die wichtigsten Komponenten und die Logik zur Lösung des Problems beschreibt.
- Übersetzung des generischen Codes in die Zielsprache: Die generische Lösung wird anschließend mithilfe eines maßgeschneiderten Codeübersetzers in den Code der jeweiligen Zielsprache übertragen. Dieser Schritt stellt sicher, dass die abstrakten Lösungen, die das LLM bereitstellt, in ausführbaren Code umgewandelt werden.
- Generierung von Testszenarien mit KI: Das LLM wird genutzt, um Testszenarien für das jeweilige Problem zu erstellen. Diese Szenarien sind entscheidend, um die Korrektheit des generierten Codes zu überprüfen.
- Validierung der Lösung: Schließlich wird der Lösungscode anhand der generierten Testszenarien auf seine Korrektheit geprüft. Nur Problem-Lösungs-Paare, die alle Testszenarien erfolgreich bestehen, werden im Datensatz behalten. So wird ein hoher Grad an Genauigkeit und Zuverlässigkeit gewährleistet.
Dieses generische LösungsmodeIl dient als Brücke zwischen verschiedenen Domänen. Es ist so strukturiert, dass es dem LLM vertraut ist und dadurch zuverlässig abstrakte Lösungen generieren kann, die anschließend problemlos in die Zielsprache übertragen werden können.
Anwendungsbeispiel: Unterstützung für eine Nischenprogrammiersprache
Kürzlich trat ein Kunde mit der Herausforderung an uns heran, ein LLM so anzupassen, dass es Fragen zu einer spezifischen, weniger bekannten Programmiersprache beantworten kann. Dieses LLM sollte auf einem offenen Modell basieren und vor Ort (on-premises) implementiert werden. Das Problem war zweigeteilt: Bestehende LLMs boten nur eine schwache Unterstützung für diese Programmiersprache, und es gab keinen verfügbaren Trainingsdatensatz dafür.
Um unsere Vorgehensweise in diesem Artikel zu veranschaulichen, ohne die Vertraulichkeit des Kunden zu verletzen, verwenden wir in diesem Beispiel eine fiktive Programmiersprache, LOLCODE, als Ersatz. Obwohl die Sprache LOLCODE bewusst nur ein fiktives Beispiel darstellt, eignet sie sich hervorragend, um die Effektivität unserer Methode zu demonstrieren.
Vergleich mit ChatGPT als Zero-Shot-Lösung
Die Vorzeichenfunktion (Signum-Funktion) ist ein mathematisches Konzept, das jede reelle Zahl ihrem Vorzeichen zuordnet:
Signum = Vorzeichen der Differenz zwischen zwei Zahlen
Wenn der Wert der Zahl positiv ist, ergibt die Funktion +1; ist der Wert negativ, ergibt sie -1; und bei einer Null gibt sie 0 zurück.
Weder Python noch LOLCODE haben diese Funktion als Standardfunktion eingebaut. Daher muss das LLM das Problem so verstehen, dass es die Vorzeichenbestimmung für die gegebene Zahl korrekt umsetzen kann, und gleichzeitig die Einschränkungen des von uns verwendeten prozeduralen Programmiermodells berücksichtigen.
Wenn wir GPT-4o nutzen, um eine Lösung in LOLCODE zu generieren, mag der erzeugte Code auf den ersten Blick vielversprechend aussehen. Bei genauerer Überprüfung treten jedoch mehrere kritische Fehler auf.

Tatsächlich enthält das Programm drei wesentliche Fehler, die verhindern, dass es korrekt ausgeführt wird (in der Auflistung sind die Fehler rot markiert):
- DIFF ist ein reserviertes Schlüsselwort in LOLCODE, daher kann eine Variable nicht „DIFF“ genannt werden.
- Die Syntax für die Subtraktion ist falsch. Sie sollte „DIFF OF NUM1 AN NUM2“ lauten.
- Der Ausdruck für den Vergleich der Zahlen ist ebenfalls fehlerhaft.
Diese Fehler sind auf konzeptioneller Ebene zwar nicht schwerwiegend, aber schwer zu erkennen, wenn nicht auf eine Vielzahl von Trainingsbeispielen zurückgegriffen wird. Bei komplexeren Problemstellungen häufen sich solche Fehler sogar noch.
Einsatz des kombinierten Ansatzes zur Generierung synthetischer Datensätze
Einsatz des kombinierten Ansatzes zur Generierung synthetischer Datensätze
Anstatt das LLM direkt zu nutzen, um den vollständigen Code zu generieren, testen wir seine Fähigkeiten, nur eine generische Lösung zu liefern. Ein solches Beispiel, das im JSON-Format durch das Modell GPT-4o erzeugt wurde (mit einem vordefinierten JSON-Schema), sieht folgendermaßen aus:
{
"steps": [
{
"type": "input",
"description": "Prompt the user for the first number",
"prompt": "Enter the first number:",
"variableName": "a"
},
{
"type": "cast variable",
"description": "Cast the first input to a float",
"variableName": "a",
"datatype": "float"
},
{
"type": "input",
"description": "Prompt the user for the second number",
"prompt": "Enter the second number:",
"variableName": "b"
},
{
"type": "cast variable",
"description": "Cast the second input to a float",
"variableName": "b",
"datatype": "float"
},
{
"type": "variable assignment",
"description": "Calculate the difference between the two numbers",
"variableName": "difference",
"assignedValueExpression": "a - b"
},
{
"type": "if-else",
"description": "Determine the signum of the difference",
"conditionExpression": "difference > 0",
"thenSteps": [
{
"type": "variable assignment",
"description": "Assign 1 to signum if difference is positive",
"variableName": "signum",
"assignedValueExpression": "1"
}
],
"elseSteps": [
{
"type": "if-else",
"description": "Check if the difference is zero",
"conditionExpression": "difference == 0",
"thenSteps": [
{
"type": "variable assignment",
"description": "Assign 0 to signum if difference is zero",
"variableName": "signum",
"assignedValueExpression": "0"
}
],
"elseSteps": [
{
"type": "variable assignment",
"description": "Assign -1 to signum if difference is negative",
"variableName": "signum",
"assignedValueExpression": "-1"
}
]
}
]
},
{
"type": "print",
"description": "Print the signum of the difference",
"stringExpression": "signum"
}
]
}
Diese Struktur stellt eine generische prozedurale Lösung dar, die in nahezu jeder modernen Programmiersprache angewendet werden kann. Zum besseren Verständnis ist derselbe Algorithmus in Form eines Flussdiagramms dargestellt:
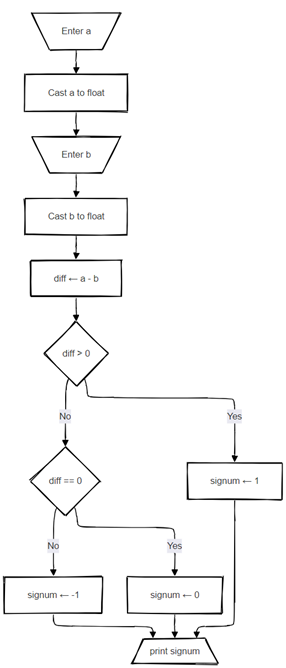
Übersetzung / Generierung von Code
Um ein funktionsfähiges Programm in der gewünschten Zielsprache zu erzeugen, haben wir eine Übersetzungskomponente entwickelt, die die vom LLM generierten generischen Lösungen in LOLCODE überträgt. Dieser Prozess umfasst die Entwicklung eines Meta-Modells, das aus zwei wesentlichen Teilen besteht:
- Anweisungen in einer generischen prozeduralen Sprache: Dieses generische Algorithmusmodell enthält die grundlegenden Bausteine einer Programmiersprache, wie Variablenzuweisungen, Eingaben/Ausgaben und Kontrollstrukturen wie IF-ELSE-Anweisungen. Während des Übersetzungsprozesses wird auf semantische Konsistenz geachtet, etwa darauf, dass alle Variablen deklariert werden, bevor sie verwendet werden.
- Ausdrücke in Python: Dieser Teil verarbeitet einfache Ausdrücke wie arithmetische und logische Operationen, Vergleiche und String-Verkettungen, die in Python formuliert sind. Da moderne LLMs besonders gut in Python ausgebildet sind, eignet sich diese Sprache ideal, um generische prozedurale Sprachen mit LOLCODE zu verbinden.
Die erzeugte hierarchische JSON-Struktur wird in LOLCODE-Anweisungen serialisiert, während Python-Ausdrücke in einen abstrakten Syntaxbaum (AST) umgewandelt und anschließend in LOLCODE-Ausdrücke übersetzt werden. Dieser Übersetzungsprozess stellt sicher, dass der finale Code syntaktisch fehlerfrei ist:
HAI 1.2
I HAS A a
I HAS A b
I HAS A diff
I HAS A signum
VISIBLE "Enter the first number:"
GIMMEH a
a IS NOW A NUMBAR
VISIBLE "Enter the second number:"
GIMMEH b
b IS NOW A NUMBAR
diff R DIFF OF a AN b
DIFFRINT diff AN SMALLR OF diff AN 0, O RLY?
YA RLY
signum R 1
NO WAI
BOTH SAEM diff AN 0, O RLY?
YA RLY
signum R 0
NO WAI
signum R -1
OIC
OIC
VISIBLE signum
KTHXBYE
Qualitätssicherung
Der letzte Schritt besteht darin, die generierten LOLCODE-Lösungen in den zuvor vom LLM erstellten Testszenarien auszuführen. Für unser Beispielproblem hat GPT-4o folgende Testszenarien generiert:
| Beschreibung des Testszenarios | Eingaben | Erwartetes Ergebnis |
| Die Differenz ist positiv, daher ist das Vorzeichen 1. | [5, 3] | 1 |
| Die Differenz ist negativ, daher ist das Vorzeichen -1. | [3, 5] | -1 |
| Die Zahlen sind gleich, daher ist die Differenz null und das Vorzeichen 0. | [5, 5] | 0 |
| Die Differenz (0 – 100) ist negativ, daher ist das Vorzeichen -1. | [0, 100] | -1 |
| Die Differenz (-10 – 10) ist negativ, daher ist das Vorzeichen -1. | [-10, 10] | -1 |
| Die Differenz (10 – (-10)) ist positiv, daher ist das Vorzeichen 1. | [10, -10] | 1 |
| Beide Zahlen sind gleich und negativ, daher ist die Differenz null und das Vorzeichen 0. | [-5, -5] | 0 |
| Beide Zahlen sind null, daher ist ihre Differenz null und das Vorzeichen 0. | [0, 0] | 0 |
| Beide Zahlen sind gleich und als Gleitkommazahlen angegeben, daher ist die Differenz null und das Vorzeichen 0. | [3.5, 3.5] | 0 |
Each solution needs to run correctly and pass all test scenarios to be included in the final training set, wJede generierte Lösung muss korrekt ausgeführt werden und alle Testszenarien bestehen, um in den finalen Trainingsdatensatz aufgenommen zu werden, der die Lösung validiert. In unserem Beispiel haben alle Tests bestanden.
Im Allgemeinen gibt es fünf mögliche Fehlerquellen in unserem Workflow:
- Das LLM generiert keinen korrekt aufgebauten generischen Algorithmus.
- Ein korrekt aufgebauter Algorithmus enthält einen semantischen Fehler, der während der Serialisierung entdeckt wird.
- Der generische Algorithmus hat einen logischen Fehler, der während der Testphase entdeckt wird.
- Einige Szenarien enthalten einen Fehler, der dazu führt, dass ein ansonsten korrekter Algorithmus in einem Testszenario fehlschlägt.
- Testfälle und der Testprozess decken nicht alle Fehler im generierten Code ab.
Nur der letzte Punkt könnte dazu führen, dass eine ungültige Lösung in den finalen Datensatz aufgenommen wird. Selbst dies kann jedoch durch die Generierung einer größeren Anzahl von Testszenarien verbessert werden.
Natürlich führt jede Maßnahme zur Erhöhung der Strenge des Qualitätssicherungsprozesses dazu, dass die Anzahl der akzeptierten Lösungen im Vergleich zur Anzahl der generierten Lösungen sinkt. Allerdings kann dieses Problem durch die Möglichkeit, eine beliebig große Anzahl von Problemen unterschiedlicher Komplexität synthetisch zu erzeugen, ausgeglichen werden.
Mögliche Folgeschritte
Obwohl wir gezeigt haben, wie man einen synthetischen Datensatz mit Prompts in Form von Aufgabenstellungen und deren Lösungen erstellt, ist der formale Output nicht nur auf Programmiercode beschränkt. Andere Anwendungsfälle könnten beispielsweise XML-Dokumente sein, die einem bestimmten Schema entsprechen, strukturierte Texte für Altsysteme oder symbolische Konstrukte, die als Eingabe für formale Systeme dienen.
Solange eine automatische Übersetzung von der generischen Lösung in ein spezifisches Format möglich ist, lässt sich dieser Ansatz vielseitig einsetzen. Das Potenzial, diese Methode auf verschiedene Programmiersprachen und formale Systeme zu skalieren, eröffnet neue Möglichkeiten für die Weiterentwicklung von LLMs. Durch das Fein-Tuning offener Modelle mit synthetischen Datensätzen ebnen wir den Weg für spezialisierte und zuverlässige KI-Lösungen, die den einzigartigen Anforderungen jeder Organisation oder Domäne gerecht werden und kostengünstig vor Ort betrieben werden können.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.