

Datenanonymisierung spielt hier eine wichtige Rolle. Sie wandelt personenbezogene Daten so um, dass diese nicht mehr auf einzelne Personen zurückgeführt werden können. Dadurch können Unternehmen wertvolle Erkenntnisse aus den Daten gewinnen, ohne die Privatsphäre zu verletzen.
Warum ist Datenanonymisierung wichtig?
- Schutz der Privatsphäre: Anonymisierung schützt persönliche Daten und stellt sicher, dass sensible Informationen vertraulich und sicher bleiben.
- Einhaltung gesetzlicher Vorschriften: Mit strengen Vorschriften wie der Datenschutz-Grundverordnung (DSGVO) hilft die Anonymisierung dabei, rechtliche Vorgaben zu erfüllen und hohe Geldstrafen zu vermeiden.
- Ethisch korrekte Datennutzung: Anonymisierte Daten ermöglichen eine ethische korrekte Nutzung im Rahmen der Weiterverarbeitung, ohne die Privatsphäre einzelner Personen zu verletzen.
In diesem Beitrag schauen wir uns an, wie Large Language Models (LLMs) zur Anonymisierung von freiformatierten Texten genutzt werden können. Wir erklären den Prozess der Datensatzgenerierung und die Feinabstimmung kleinerer Modelle wie Llama 3.1, die durch eine Quantisierung noch effizienter gemacht werden können. Außerdem besprechen wir, warum LLMs für diese Aufgabe interessant sind, obwohl auch kleinere Modelle für die Token-Klassifikation bereits gut für die Anonymisierung geeignet sind.
Warum LLMs für die Datenanonymisierung nutzen?
Im Bereich der Datenanonymisierung haben sich traditionelle Modelle wie BERT und neuere transformerbasierte Modelle als effektiv erwiesen, insbesondere für die Erkennung benannter Entitäten (Named Entity Recognition, NER). Diese Modelle sind sehr gut darin, bestimmte Informationen im Text zu identifizieren und zu klassifizieren, die anonymisiert werden müssen. Mit dem Aufkommen von LLMs ergeben sich jedoch neue Möglichkeiten und Vorteile.
Kein aufwändiges Training notwendig
Ein großer Vorteil von LLMs ist, dass sie ohne umfangreiches Training genutzt werden können. Dank ihrer breit gefächerten Fähigkeiten können sie Anonymisierungsaufgaben direkt ausführen, ohne dass dafür große Vorbereitungen nötig sind.
Diese sogenannte „Zero-Shot“-Fähigkeit ist ein Game-Changer für Unternehmen, die schnell und effizient Lösungen umsetzen müssen. Dadurch entfallen zeitaufwändige Trainingsprozesse, und die Modelle können sofort angewendet werden.
Personenbezogene Informationen ersetzen
Ein wichtiger Vorteil der LLMs bei der Datenanonymisierung ist, dass sie Texte verändern können, ohne die ursprüngliche Bedeutung zu verfälschen. Anders als Token-Klassifikationsmodelle, die nur sensible Informationen erkennen und ausblenden, können LLMs neue Texte generieren, die zwar personenbezogene Daten weglassen, aber den restlichen Kontext beibehalten. Zum Beispiel kann ein LLM einen Satz wie „John Doe, ein 45-jähriger aus New York, sagte…“ in „Eine 45-jährige Person aus einer Großstadt sagte…“ umwandeln. Auf diese Weise bleibt der Text verständlich und nützlich, was besonders wichtig ist, um die Daten weiterhin sinnvoll verwenden zu können.
Hier ein Beispiel zur Verwendung des Llama-3.1-405B-Instruct-Modells mit Zero-Shot-Prompting in zwei Szenarien: Das erste zeigt ähnliche Ergebnisse wie traditionelle Token-Klassifikationsmodelle. Das zweite zeigt, wie der Text umgeschrieben wird, um personenbezogene Informationen zu entfernen und trotzdem alle wichtigen Inhalte beizubehalten – eine Fähigkeit. die traditionelle Modelle nicht leisten können.
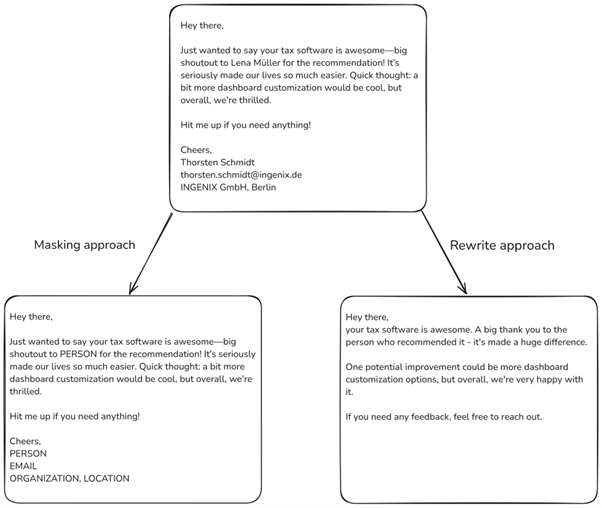
Neue Entitäten erkennen? Kein Problem!
Ein weiterer Vorteil von LLMs ist ihre Fähigkeit, neue Entitäten (= klar identifizierbare und bedeutungstragende Informationseinheiten innerhalb eines Textes) zu erkennen, auch wenn diese nicht explizit im Trainingsdatensatz enthalten waren. Das ist besonders wichtig in Bereichen, in denen neue Begriffe oder Identifikatoren ständig dazukommen. LLMs können dank ihres umfangreichen vortrainierten Wissens diese neuen Entitäten erkennen und anonymisieren, ohne dass ein zusätzliches Training nötig ist. Diese Flexibilität macht LLMs besonders nützlich in dynamischen Umgebungen und fachlich vielseitigen Branchen.
Herausforderungen bei der Nutzung von LLMs und der Vorteil kleinerer Modelle
Obwohl LLMs beeindruckende Fähigkeiten zur Datenanonymisierung bieten, gibt es Herausforderungen bei ihrer effektiven Nutzung, insbesondere bei der Wahl zwischen internen (On-Premises) und Cloud-basierten Lösungen. Der Einsatz von LLMs vor Ort bietet wichtige Vorteile, wie z.B. mehr Kontrolle über Datenschutz und Sicherheit – ein kritischer Punkt für viele Unternehmen. Wenn LLMs intern betrieben werden, verringert sich das Risiko, dass Daten bei der Nutzung von Cloud-Diensten oder APIs wie denen von OpenAI nach außen gelangen.
Der Betrieb von LLMs am eigenen Standort bringt jedoch auch Herausforderungen mit sich. Diese Modelle sind i.d.R. groß und bestehen oft aus Milliarden von Parametern. Sie benötigen erhebliche Rechenressourcen für das Training und die Inferenz. Viele Unternehmen müssen in leistungsstarke Hardware wie GPUs investieren, was hohe Kosten und Wartungsaufwände bedeutet. Im Gegensatz dazu lässt sich Cloud-Infrastruktur leichter skalieren, was einige Unternehmen vor die Frage stellt, ob sich die Investition in eigene Hardware lohnt.
Feinabstimmung von LLMs für die Anonymisierung
Durch die Feinabstimmung können wir vortrainierte LLMs an spezielle Aufgaben wie die Anonymisierung anpassen, ohne das Modell komplett neu trainieren zu müssen. Große Modelle wie GPT-4o oder Llama 3.1-405B benötigen keine Feinabstimmung, da ihre Leistungsfähigkeit bereits sehr hoch ist. Kleinere Modelle wie Llama 3.1-8B hingegen können Fehler machen. Sie liefern nicht immer ein konsistentes Ergebnis, und die Leistung wird schlechter, wenn sie nicht in englischer Sprache arbeiten. Hier wird ein Finetuning benötigt.
Der Feinabstimmungsprozess besteht aus:
- Evaluation: Die Leistung des Modells wird regelmäßig mit einem separaten Validierungsdatensatz überprüft, um sicherzustellen, dass es die Aufgabe korrekt erlernt.
- Wahl eines Basismodells: Ein kleineres vortrainiertes Modell wie Llama 3.1-8B wird ausgewählt.
- Definition der Aufgabe: Die Anonymisierung wird als konkrete Aufgabe definiert, z. B. „Schreiben Sie den Text um, um alle personenbezogenen Informationen zu entfernen, während der Kontext erhalten bleibt.“
- Erstellung von Trainingsdaten: Es wird ein Datensatz erstellt, der Originaltexte und deren anonymisierte Versionen enthält.
- Feinabstimmungsprozess: Techniken wie PEFT (Parameter-Efficient Fine-Tuning) oder LoRA (Low-Rank Adaptation) werden verwendet, um das Modell effizient an die Anonymisierungsaufgabe anzupassen. QLoRA kann zusätzlich zur Feinabstimmung quantisierter Modelle eingesetzt werden.
Datasets für die Feinabstimmung von LLMs
Die Qualität und Vielfalt des Trainingsdatensatzes sind entscheidend, um effektive Anonymisierungsmodelle zu entwickeln. Hier sind drei Ansätze, die sich in der Praxis bewährt haben:
- Umwandlung bestehender Datensätze
- Etablierte Datensätze wie CONLL (Conference on Natural Language Learning) können verwendet werden.
- Diese Datensätze lassen sich in Frage-Antwort-Paare umwandeln, indem leistungsfähige Modelle genutzt werden.
- Solche Paare dienen dann dazu, kleinere, spezialisierte Modelle für Anonymisierungsaufgaben zu trainieren.
- Erhebung und Kennzeichnung umfangreicher realer Daten
- Es kann eine große Menge an vielfältigen, realen Daten gesammelt werden.
- Ein leistungsfähiges Modell kann diese Daten für Anonymisierungsaufgaben kennzeichnen.
- Dieser Ansatz deckt eine Vielzahl von realen Szenarien und Randfällen ab.
- Generierung synthetischer Datensätze
- Leistungsstarke LLMs können in Kombination mit Bibliotheken wie Mimesis und Faker genutzt werden.
- Damit lassen sich vollständig synthetische Datensätze erstellen, die ein breites Spektrum an Anonymisierungsszenarien abdecken.
- Dieser Ansatz ermöglicht die Generierung großer, vielfältiger Datensätze ohne Datenschutzbedenken.
Alle genannten Ansätze basieren auf der Nutzung großer, leistungsfähiger Modelle zur Datensatzgenerierung. Dadurch wird das Wissen und die Kapazität der großen Modelle gewissermaßen „destilliert“ und in kleinere Modelle übertragen, indem spezifische Trainingsdaten bereitgestellt werden.
Leistungsbewertung von LLMs – keine einfache Aufgabe
Die Leistung eines LLMs zu bewerten, unabhängig von der Feinabstimmung, kann eine komplizierte Aufgabe darstellen. Im Gegensatz zu traditionellen Modellen für die Token-Klassifikation, die automatisiert durch Kennzahlen (wie Genauigkeit oder den F1-Score) bewertet werden können, muss die Leistung von LLMs durch eine Kombination aus automatisierten und manuellen (menschlichen) Bewertungen überprüft werden.
Entscheidet man sich für den Ansatz hinsichtlich Ersetzung / Austausch, kann eine automatisierte Bewertung durch ein weiteres leistungsfähiges LLM erfolgen, das darauf ausgelegt ist eine Bewertung oder einen Score zu erstellen. Ein weiterer, aber aufwendigerer Ansatz ist die Human-in-the-Loop (HITL) Bewertung, bei der Experten die anonymisierten Texte manuell prüfen und mit dem Originaltext vergleichen. Mit diesen beiden Verfahren wird sichergestellt, dass keine personenbezogenen Daten mehr enthalten sind, der Text jedoch weiterhin alle relevanten Informationen enthält.
Ein weiterer wichtiger Punkt ist die Konsistenz der Ergebnisse. LLMs neigen dazu, für sehr ähnliche Eingaben unterschiedliche Resultate zu liefern, besonders bei kleineren Modellen. Randfälle wie ungewöhnliche Namen, Fremdwörter oder unerwartete Datenformate sind oft die Aufgabenstellungen, in denen die Modelle am wahrscheinlichsten Fehler begehen. Daher ist es entscheidend, dass die Bewertungsdatensätze möglichst viele Randfälle enthalten, um sicherzustellen, dass das Modell auch in diesen Situationen zuverlässig funktioniert.
Fazit
Mit der Weiterentwicklung von LLMs werden wir zweifellos mehr Anwendungsfälle sehen, in denen diese Modelle traditionelle Methoden in verschiedenen Prozessen ersetzen und in manchen Fällen sogar ganze Arbeitsabläufe übernehmen. Obwohl LLMs beeindruckende Fähigkeiten bieten, ist es wichtig, auch andere geschäftliche Faktoren zu berücksichtigen, die über das bloße Lösen eines spezifischen Problems hinausgehen. Skalierbarkeit, Kosten und Leistung sind entscheidende Aspekte, die sorgfältig abgewogen werden müssen.
| LLM’s | Token-classification models | |
|---|---|---|
| Versatility | Can handle a wide range of tasks with minimal adjustments | Reliable, stable performance but may not match the latest advances |
| State-of-the-art performance | Can achieve cutting-edge results in many NLP tasks | Token-classification models |
| Cost | High computational and financial costs for training and inference | Generally, more cost-effective, especially at scale |
| Scalability and speed | Slower inference times, requiring large infrastructure | Faster inference, much smaller infrastructure requirements |
| Specialization | Can be overkill for simple tasks | Highly efficient and effective for specific, well-defined tasks |
In unseren Experimenten zur Anonymisierung haben wir festgestellt, dass LLMs sehr leistungsfähig für diese Aufgabe sind, traditionelle Methoden jedoch nach wie vor einen hohen Wert haben. Diese Methoden liefern oft schnellere Ergebnisse und sind im Vergleich zu LLMs kosteneffizienter. Es ist wichtig, über neue Trends informiert zu bleiben und neue Technologien auszuprobieren, aber es ist ebenso wichtig, zu erkennen, dass „neuer“ nicht immer „besser“ bedeutet. Eine Balance zwischen Innovation und Praktikabilität hilft dabei, das richtige Werkzeug für die jeweilige Aufgabe zu wählen.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.



