If you’re interested in receiving interviews with thought leaders and a digest of exciting ideas from the world of DevOps straight to your inbox, subscribe to our 0800-DEVOPS newsletter!
###
When it comes to infrastructure, striking the right balance between self-service and control is never an easy task.
Being a professional services company, we have used (or at least piloted) almost every technology stack in Java ecosystem. For these projects, we had to create both the development and test environments. This usually came down to creating a couple of VMs and granting developers an admin account to install their stuff there.
In 2016. we have started using Red Hat OpenShift container platform. What has started as an experiment, ended up being a standard runtime platform. Nowadays, when looking for a runtime environment, nobody asks for a VM anymore. People now ask for a project/namespace on OpenShift platform. Our colleagues who used to administer VMs are now administrating OpenShift platform. Apart from taking care of the OpenShift instance this also includes creating OpenShift projects and namespaces. In times when there are many such requests, people have to wait and then they start asking why can’t we have more of a self-service approach…
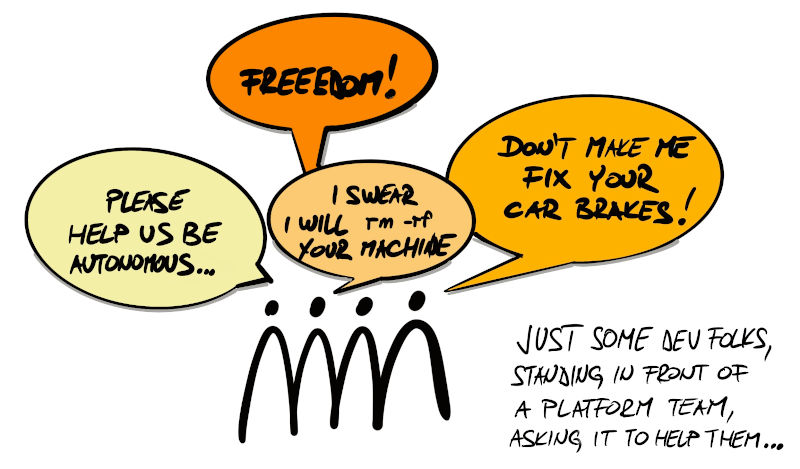
This puts our platform administrators in a tough position. How to provide self-service while retaining some level of control?
Just by looking at the requests for OpenShift resources, it is visible that people tend to ask for much more than they need: 2 CPUs, 8 GB for something that is a mere Spring Boot app in a test environment! Left to their own devices, they would allocate the whole cluster in less than a week. Furthermore, nobody ever releases unused resources. We found our OpenShift instance to be full of zombie containers that nobody uses… just running in the background wasting CPU and memory. A clear example of The Tragedy of the Commons.
To cut people some slack and at the same time lift some burden from our administrators’ back, we’re now doing the following:
Education, awareness… and then some more
Please people, think twice before you ask for hefty infrastructure resources. Do you really need that many cores and that much memory? Did you do everything you could to optimize the app? Did you try to resolve bare minimum resources that fit your startup time requirements?
We are emphasizing the need for developers to understand that they are running in a shared-resources environment and responsibility of providing the optimum resource requirements. Developers are instructed to run their apps in a local Docker environment and limit apps resources to get startup time that is within an acceptable range. That means tweaking, for eq., Java memory parameters in the case of JRE 1.8. After applying newly received resource requirements, we have gained about 40% more memory and àbout 20% more milicores that have instantly become available for accommodating even more apps.
Database self-provisioning
To speed up database provisioning, we have developed a small app called “Give me a Database!” which does precisely what the name suggests – it enables developers to self-provision a PostgreSQL database. One just needs to enter a database name and… Voila!… database is created and connection details are shown.
OpenShift self-provisioning
There are ways in which you can enable self-provisioning of OpenShift resources, but we would like to have more control over how these resources are allocated. Therefore we’re currently in a process of developing a self-service portal that would (inspired by AWS instances) offer 3 classes of OpenShift resources: Dev.Small, Dev.Medium and Dev.Large.
Dev.Small package is something like 0.5 CPU (*) and 512MB RAM with a TTL (Time To Live) of 2 months. Developer can self-provision a small package any time, no questions asked. As TTL is approaching, developers are notified that they should either request a prolongation or make peace with their package going down.
Dev.Medium package is something like 1 CPU and 1GB RAM but with a smaller TTL of 1 month. Just like a small package, developer can also automatically self-provision a medium package.
Dev.Large package is something like 2 CPUs and 2+GB RAM and it cannot be automatically provisioned. A developer can make a request which needs to be approved by platform administrators before provisioning. With this, we would like to motivate our developers to think about the resources and also to give a layer of control to our administrators over the platform’s health.
(*) Packages are sized based on Spring Boot application
We’re also considering introducing a parallel set of runtime packages (Run.Small, Run.Medium and Run.Large). Runtime packages need fewer resources than their Dev counterparts since they don’t have that “build” phase.
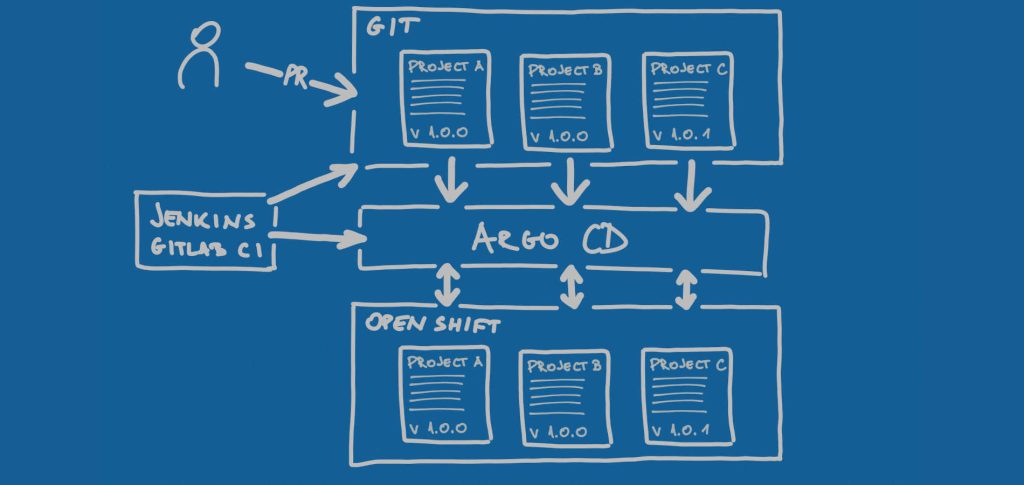
Under the hood, all of this is implemented using a custom self-service portal, custom-developed OpenShift Operator and Argo CD. Portal generates necessary configuration and pushes it to Git repo. Argo CD takes the configuration and provisions resources in OpenShift. In the case of large instances, the portal generates MR. Once the platform administrator approves MR, Argo CD processes it.
With these 3 measures, we’re hoping to strike that balance between anarchy and totalitarianism. If you’re in a similar situation, you can also try this, but YMMW because what works in one organization doesn’t necessarily work in another. When in a doubt, take a Gemba walk. Go and see.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.