

AI coding tools have evolved from basic autocomplete and syntax prompts to tools that support real software development. Teams use them to generate code, explain existing logic, write tests, refactor modules, and review changes. As these tools take on larger parts of the development process, the main question is no longer whether AI can write code. The more important question is how to evaluate its impact on software delivery.
At CROZ, this topic is high on our agenda, both in our internal engineering work and in conversations with clients. We are not looking at AI coding tools only through the question of which tool to choose. We are looking at the methodology behind the evaluation: how to measure value, quality, risk, cost, developer experience, and adoption in a real engineering environment.
That shift matters because AI-assisted development is quickly moving from individual experimentation into team-level and organization-level decisions. Once a tool becomes part of delivery, its value cannot be judged only by a demo, a benchmark score, or the number of lines of code it can generate. It needs to be evaluated based on how it performs in real project work.
Why AI coding tools need organized evaluation
The field of AI coding tools is changing quickly. New tools appear regularly, existing platforms add larger context windows and agentic features, vendors update pricing models, and teams are still testing what works in practice. Public benchmarks are improving, but they still show only part of the picture.
A tool may perform well in a benchmark and still fail in a specific enterprise environment. It can generate code quickly, but still leaves developers with more review and rework than expected. It can also be popular among individual developers while still being difficult to govern across teams, projects, and clients.
That is why the evaluation should not focus only on selecting a tool. The more useful question is how to create a repeatable way to evaluate AI coding tools within the engineering process. The decision should come down to actual delivery work, including quality, cost, rework, developer trust, workflow fit, and long-term maintainability.
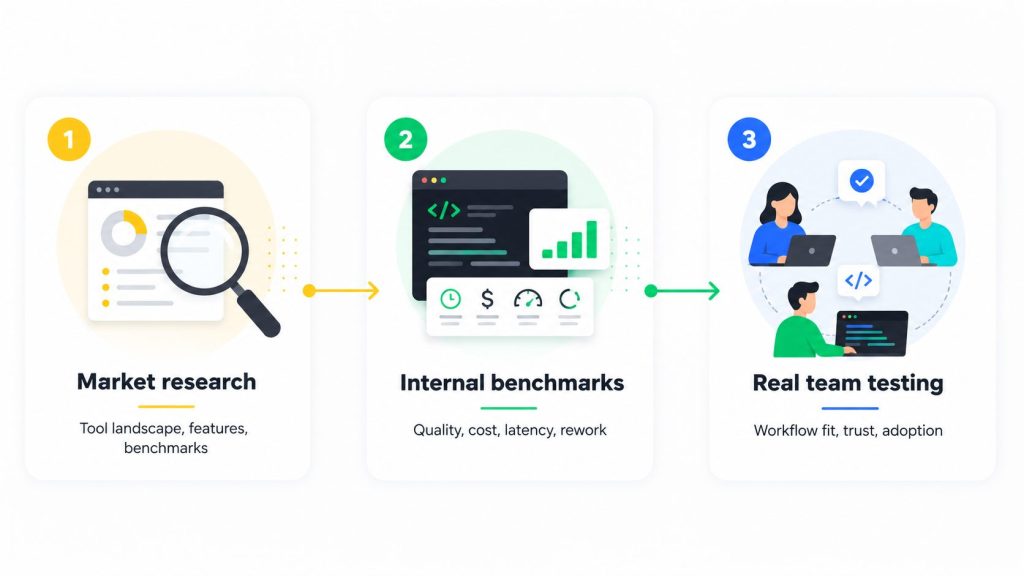
Step 1: Understanding the market
Before running internal tests, we first need to understand what tools are available and how they compare. This includes feature sets, supported IDEs, context handling, agentic capabilities, model quality, licensing options, and enterprise readiness.
Public benchmarks provide an initial view of how different tools perform on standardized programming tasks. They help us understand the landscape, but they do not represent the complexity of a real enterprise codebase or a production environment built over years of business logic and internal coding standards.
This step is useful because it narrows the field and gives structure to the evaluation. But it does not decide the outcome. Market research and public benchmarks are inputs. The real answer comes only after AI coding tools are tested in conditions closer to actual delivery work.
Step 2: Testing in realistic engineering scenarios
After the market scan, the evaluation moves closer to real engineering work. Instead of depending only on external results, we test tools on tasks that resemble what developers actually do: bug fixes, feature additions, refactoring, test generation, and code understanding.
In this phase, we look at five key dimensions:
- Pass rate: Did the tool solve the task fully or only partially?
- Quality of solution: Is the result correct, robust, maintainable, secure, and consistent with coding style?
- Cost: How many tokens and license resources does the tool consume?
- Latency: How long does it take to reach a usable result?
- Rework: How much human correction is needed after the tool produces its output?
This is where the evaluation goes beyond a tool comparison. We do not only ask whether the tool produced code. We ask whether the output solves the right problem, follows quality standards, remains secure and maintainable, and is reasonable for the team to own afterward.
This also gives us a more realistic view of productivity. If generated code requires major review, rewriting, or debugging, the initial time saving can quickly disappear. That is why we compare tool efficiency with a human baseline and look at how much time is actually saved, how much rework is required, and whether the final result reduces risk.
Step 3: Testing with real teams
Benchmarks are necessary, but they do not capture everything. They cannot measure how natural a tool feels in a developer’s workflow, whether it interrupts more than it helps, or whether developers trust it enough to use it every day.
These questions only become visible when real teams use the tools in day-to-day project work. After internal benchmarks, developers test selected tools in regular workflows to understand how they behave outside controlled scenarios.
This phase shows whether the tool fits the team’s workflow, supports common tasks, reduces mental workload, and provides suggestions developers can trust. Feedback from teams is collected in an organized format, enabling us to compare tools across use cases and developer experience.
This matters because adoption is also a metric. A tool can have strong benchmark results and still fail if developers do not see enough practical value in it. In that sense, evaluation is not only about technical performance. It is also about whether the tool can become a useful part of how a team actually works.
From experimentation to engineering discipline
Many organizations are now asking how to introduce AI coding tools responsibly. The first question is often which tool to buy, but a better starting point is to define what the organization wants to improve: faster feature delivery, better test coverage, easier onboarding, better understanding of legacy code, or reduced repetitive work.
At CROZ, this is the approach we are developing in our own work and discussing with clients who want to move from AI experimentation to practical, governed, and measurable adoption. The focus is not only on tools but also on building an evaluation method that supports better engineering decisions.
AI coding tools will continue to evolve quickly, so evaluation cannot be a one-time activity. The market should be reviewed regularly, benchmarks updated, internal usage monitored, and team feedback used to guide future decisions.
AI coding tools will keep changing, and so will the ways teams use them. That is exactly why evaluation needs to become a regular part of AI-assisted development, not something done once before a tool is introduced.
For us, the goal is not to predict one winning tool. It is to build a way of working that helps teams understand where AI creates real value, where human judgment remains essential, and how both can fit into reliable software delivery.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.



