

Im ersten Blogartikel dieser Serie haben wir die strategische Roadmap der ETL-Modernisierung erläutert: weg von Legacy Data Warehouses wie Informatica und Oracle, hin zu modernen Lakehouse-Architekturen mit Hilfe von Databricks.
Im zweiten Blogartikel haben wir Databricks Lakebridge technisch genauer betrachtet und gezeigt, wie sich große Teile des ETL-Migrationsprozesses automatisieren lassen. Diese Automatisierung beschleunigt den ersten Konvertierungsschritt erheblich. Der erzeugte Code ist danach jedoch noch nicht produktionsreif und benötigt weiterhin manuelle Validierung, Tests, Optimierung und fachliche Verfeinerung, damit Korrektheit und Konsistenz mit dem Legacy-Verhalten gewährleistet sind.
In diesem abschließenden Beitrag der Serie betrachten wir den Schritt nach der Konvertierung: die Validierung des generierten Codes und den Weg hin zu produktionsreifen Pipelines. Wir zeigen, wie wir unseren internen LLM-Agenten Jarvis genutzt haben, um diese letzte Migrationsphase zu beschleunigen und zu verbessern. Jarvis analysiert transpilierten PySpark- und Spark-SQL-Code, identifiziert Syntax- und Logikprobleme, schlägt Verbesserungen vor und hilft Engineering-Teams, die Lücke zwischen generiertem Output und produktionsreifen Pipelines effizienter zu schließen.
Schlanker Single-Agent-Ansatz
Wir haben uns auf einen schlanken Ansatz konzentriert, der wenig Aufwand erfordert und zugleich die finale Validierungsphase deutlich verbessert. Der Ansatz nutzt ein Single-Agent-Setup mit vier aufeinanderfolgenden Schritten, wie in der folgenden Abbildung dargestellt.
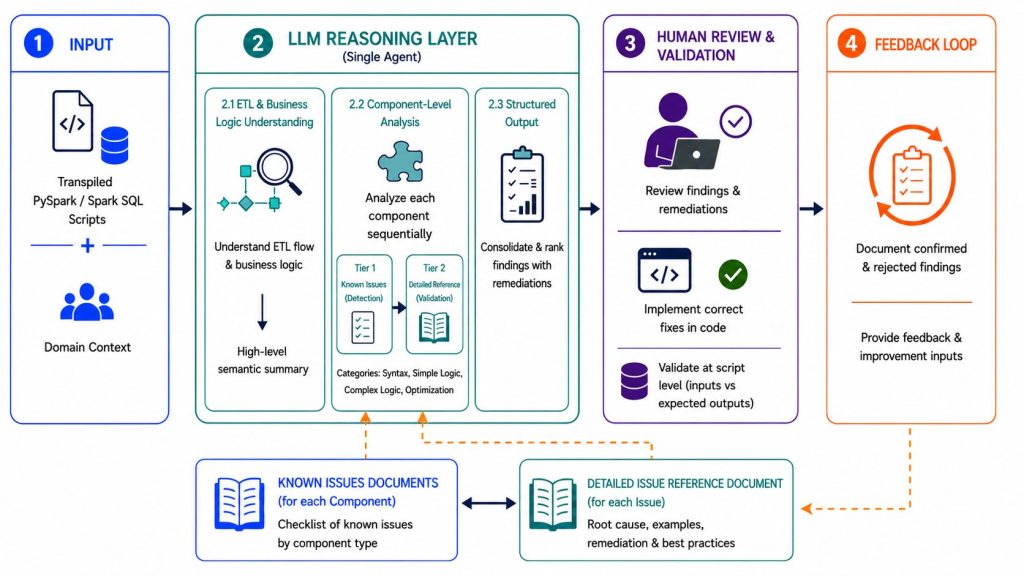
Der Ansatz kombiniert leichtgewichtiges Tooling, prompt-gesteuertes LLM-Reasoning und menschliche Validierung. Ziel ist es, Automatisierung dort zu maximieren, wo sie sinnvoll ist, und gleichzeitig Kontrolle und Genauigkeit durch gezielte menschliche Überprüfung sicherzustellen. In einem vereinfachten End-to-End-Muster verarbeitet das System transpilierten PySpark- oder Spark-SQL-Code zusammen mit Domänenkontext, führt ihn durch eine geführte Reasoning-Schicht und erzeugt einen strukturierten Validierungsbericht. Dieser Bericht wird anschließend von Engineers geprüft und als Grundlage für die finale Validierung und Verfeinerung genutzt.
LLM-Reasoning-Schicht
Im Zentrum des Systems steht die LLM-Reasoning-Schicht, in der der Agent sequenzielle Analyseschritte ausführt. Der LLM-Agent verarbeitet die transpilierten Python-Skripte nacheinander und nutzt dabei den bereitgestellten allgemeinen Domänenkontext.
ETL- und Business-Logik verstehen
Zuerst führt der Agent eine High-Level-Analyse des gesamten Skripts durch. Er betrachtet die ETL-Flow-Struktur, Objektnamen und Transformationsmuster und fasst die Bedeutung der ETL- und Business-Logik in einer strukturierten, für Menschen lesbaren semantischen Darstellung zusammen. Dadurch entsteht ein besseres Verständnis für nachfolgende LLM-Reasoning-Schritte und für die manuelle Überprüfung.
Analyse auf Komponentenebene
Anschließend wird das Skript Komponente für Komponente verarbeitet, basierend auf den von Lakebridge markierten Komponenten-Codeblöcken. Für jede Komponente nutzt der Agent einen deterministischen, komponentenbasierten Lookup-Mechanismus, um Validierungswissen zum jeweiligen Informatica-Komponententyp abzurufen. Dieses Design folgt einer mehrstufigen Retrieval-Struktur: leichte Problemerkennung und tieferer Remediation-Kontext werden voneinander getrennt.
In der ersten Stufe ruft der Agent auf Basis des Informatica-Komponententyps (z.B. Joiner, Lookup, Source Qualifier oder Target) über eine deterministische Lookup-Funktion ein vordefiniertes Known Issues Document ab. Dieses Dokument enthält eine kompakte, kuratierte Checkliste bekannter Probleme, also Validierungsregeln und typische Fehlermuster für diesen Komponententyp. Die Muster sind in vier Hauptkategorien gegliedert:
- Syntax Issues – Fehler, die Kompilierung oder Laufzeit brechen können, etwa ungültige Ausdrücke, fehlerhafte Klammern oder nicht unterstützter Informatica-spezifischer Code.
- Simple Logic Issues – einfache Transformationsfehler, etwa konkrete falsche Mappings oder Filtermuster.
- Complex Logic Issues – semantische oder datenfachliche Korrektheitsprobleme, etwa falsche Joins oder inkonsistente Transformationsmuster.
- Optimization Issues – Performance-Ineffizienzen oder suboptimale Transformationsmuster, etwa Python-Funktionen, obwohl PySpark-Logik verfügbar wäre.
Jedes Problemmuster enthält eine kurze Beschreibung als Referenzprompt, anhand dessen der Agent mögliche Probleme identifizieren kann, ohne zu viel Kontextfenster zu verbrauchen.
Beispiel:
# Joiner_Known_Issues.md
## Syntax Issues
- replace invalid reference {{('param_name')}} with '{param_name}' -> JOINER-SYN-003
- mark Informatica/Oracle specific variable reference like @TableName for manual validation -> JOINER-SYN-006
- ensure every opening bracket has a matching closing bracket -> JOINER-SYN-002
- remember that dbutils library is also available on Serverless compute -> JOINER-SYN-001
## Simple Logic Issues
- look out for joins on not expected table columns -> JOINER-LOG-002
- do not join on hash columns derived from mismatched sources -> JOINER-LOG-004
## Complex Logic Issues
- prevent cartesian joins by ensuring proper join conditions exist -> JOINER-CMP-003
## Optimization Issues
- use broadcast joins for small reference datasets -> JOINER-OPT-001
- avoid Python UDFs in join conditions -> JOINER-OPT-004
- remove unnecessary repartition before joins -> JOINER-OPT-003
In der zweiten Stufe wird jedes Problem, das der Agent in der ersten Stufe identifiziert hat, mit einem Detailed Issue Reference Document verknüpft. Dieses enthält alle Probleme für einen bestimmten Komponententyp, gruppiert nach Problemtyp und sortiert nach Referenznummer.
Die Referenz-ID JOINER-CMP-003 bedeutet beispielsweise, dass im Detailed Issue Reference Document nach einem Problem mit folgenden Eigenschaften gesucht werden kann:
- Komponententyp: Joiner
- Problemtyp: Complex Logic Issue
- Referenznummer: 003
Dieses erweiterte Dokument liefert tieferen Kontext zu den verknüpften Problemen: konkrete Codebeispiele, Erklärungen zu Ursache und Verhalten, strukturierte Remediation-Hinweise und Best-Practice-Muster für die Lösung.
Die Trennung in zwei Stufen ermöglicht es dem System, potenzielle Probleme zunächst mit kompakten Beschreibungen zu erkennen und anschließend für jedes Problem tieferen Kontext aus der zweiten Stufe zu nutzen. So kann der Agent präzisere und kontextbewusstere Lösungsvorschläge erzeugen.
Strukturierter Output
Nachdem alle bekannten Probleme einer Komponente verarbeitet wurden, setzt der Agent die Analyse mit seinem allgemeinen PySpark- und Spark-SQL-Wissen sowie seinem Verständnis der Transformationslogik fort. Dabei identifiziert er potenzielle unbekannte Probleme, die nicht in den Known Issues Documents enthalten sind. Solche Findings werden ebenfalls beschrieben, nach derselben Problem-Taxonomie kategorisiert und mit einem Lösungsvorschlag auf Basis bewährter Spark- und PySpark-Muster versehen.
Am Ende erzeugt der Agent für jedes Skript einen strukturierten Findings Report. Dieser konsolidiert alle Probleme, ordnet sie nach Komponententyp und Kategorie und enthält Problembeschreibungen, Codeausschnitte und empfohlene Lösungen in einem konsistenten, review-fähigen Format.
Menschliche Überprüfung und Validierung
Der vom LLM erzeugte Findings Report dient als zentrales Artefakt für die Validierung und Überprüfung auf Skriptebene. Für den aktuellen Migrationsumfang und eine repräsentative Skriptmenge liegen Eingabe- und erwartete Ausgabedaten nur auf Skriptebene vor, nicht auf Ebene einzelner Komponenten. Daher kann die Validierung nur für das gesamte Skript durchgeführt werden.
Engineers nutzen den Bericht als primäre Validierungsreferenz und prüfen gleichzeitig jedes identifizierte Problem sowie die vorgeschlagene Remediation. Dabei bewerten sie, ob Findings korrekt, relevant und richtig gelöst sind. Dazu gehört der Vergleich von Eingaben und erwarteten Ausgaben auf Skriptebene ebenso wie die Bewertung der logischen Korrektheit der vorgeschlagenen Änderungen.
Feedback Loop
Alle bestätigten und abgelehnten Findings werden während des Prozesses dokumentiert. Für jedes Problem halten menschliche Reviewer fest:
- Accuracy Assessment: ob das Problem korrekt identifiziert wurde, also True Positive, oder fälschlich markiert wurde, also False Positive.
- Relevance & Importance: welche Bedeutung das Problem für Codequalität, Sicherheit, Performance oder Wartbarkeit hat.
- Remediation Validation: ob der vorgeschlagene Lösungsansatz passend und wirksam war.
- Final Resolution: welche tatsächliche Lösung für bestätigte Probleme umgesetzt wurde, einschließlich Anpassungen gegenüber dem ursprünglichen Vorschlag.
Mit LLM-Unterstützung werden die Feedback-Informationen anschließend besser strukturiert. Gültige und ungültige Probleme werden in die Known Issues Documents und Detailed Issue Reference Documents übernommen, nach Komponententyp gruppiert und zusammen mit der Überarbeitung bestehender Probleme anhand der genannten Bewertungen gepflegt. Dadurch erhält der Agent tieferen Kontext dazu, worauf er achten und was er ignorieren soll. So entsteht ein kontinuierlicher Feedback Loop, der Erkennungsgenauigkeit, Problemabdeckung und Qualität der Remediation-Hinweise schrittweise verbessert.
Bewertung
Nachdem der LLM-gestützte Validierungsworkflow definiert ist, geht es im nächsten Schritt darum zu bewerten, wie gut er in der Praxis funktioniert, wenn er auf transpilierten PySpark- und Spark-SQL-Code angewendet wird. Wir wollen unter anderem folgende Fragen beantworten:
- Erkennt der Workflow Syntaxprobleme, einfache Logikfehler und komplexe Logikprobleme zuverlässig?
- Wie verlässlich und relevant sind die vorgeschlagenen Remediations?
- In welchem Umfang bestätigt oder hinterfragt die Human-in-the-Loop-Validierung die Findings des Agenten?
- Wo funktioniert der Ansatz gut, und wo muss er weiter verfeinert werden?
Dieses Kapitel stellt eine strukturierte Bewertung des vorgeschlagenen Ansatzes vor und betrachtet seine Stärken, Grenzen und praktischen Auswirkungen auf die Validierung und Modernisierung von Datenpipelines in Databricks-Umgebungen.
Verbesserungen: Eine Stärke von LLMs
In unserer Evaluation erwies sich der LLM-Agent vor allem in vier Bereichen als besonders hilfreich: konsistentere Problemerkennung, schnelleres Verständnis komplexer ETL-Logik, bessere Remediation-Vorschläge und Erkennen von Optimierungspotenzialen.
Verbesserte Problemerkennung und Konsistenz
Code manuell Zeile für Zeile zu prüfen, ist anstrengend und langsam. Irgendwann lässt die Konzentration nach, Details werden übersehen und dieselben Codebereiche müssen mehrfach erneut betrachtet werden. Das erhöht die Review-Zeit und lässt dennoch das Risiko bestehen, dass subtile Probleme erst in späteren Validierungsphasen oder sogar in der Produktion auffallen. Unser Agent wird nicht müde und übersieht Details nicht auf dieselbe Weise. Jede Zeile wird konsistent geprüft, mit Fokus auf den jeweiligen Komponententyp. Das erleichtert das Erkennen von Problemen, insbesondere in großen und komplexeren Skripten.
Das führt zu einer schnelleren und verlässlicheren Problemerkennung früh im Review-Prozess und reduziert wiederholte Re-Analysen und Folge-Reviews. Zusätzlich erhöhen wir durch ein klar definiertes Set bekannter Muster und Standardprobleme für jeden transpilierten Informatica-Komponententyp die Erkennungsgenauigkeit und Konsistenz weiter und verbessern den gesamten Review-Prozess.
Schnelleres Verständnis von ETL- und Business-Logik
Bei der manuellen Prüfung komplexer Logik kann es zunächst beträchtliche Zeit kosten, die zugrunde liegenden fachlichen Anforderungen zu verstehen. In unserem Ansatz nutzen wir den Agenten, um zu erklären, was der transpilierte Code tut, und PySpark-Operationen zurück in die ursprüngliche Business-Logik zu übersetzen. Dadurch lässt sich schneller und einfacher validieren, ob die Transformation die fachlichen Anforderungen erfüllt. Das verbessert Geschwindigkeit und Vollständigkeit der manuellen Validierung, weil Engineers die zugrunde liegende Logik schneller und besser verstehen.
Bessere Remediation-Vorschläge
Wenn Probleme identifiziert werden, kann die Lösung manchmal sehr einfach sein, etwa eine kleine Syntaxänderung. Sie kann aber auch komplex sein und viel Zeit erfordern, bis die richtige Logik gefunden ist. Unser interner Agent lieferte Best-Practice-Remediation-Vorschläge, die aus abgeleiteter Business-Logik, allgemeinem PySpark- und Python-Wissen sowie zuvor validierten Lösungen generiert werden. Was sonst eine längere Debugging-Session wäre, kann dadurch häufig zu einer schnellen Codeänderung werden.
Gleichzeitig dürfen diese Vorschläge nicht als vollständig autoritativ behandelt werden. Aufgrund der nichtdeterministischen Natur von LLM-Agenten und der Komplexität von ETL-Transformationen muss jeder vorgeschlagene Fix von Engineers validiert werden, damit er zu erwarteten Business-Ergebnissen und Datenverhalten passt. Durch den strukturierten Feedback Loop, in dem bestätigte und abgelehnte Vorschläge zurück ins System fließen, beobachteten wir jedoch eine spürbare Verbesserung von Qualität und Relevanz der Empfehlungen über die Zeit, insbesondere in späteren Migrationsiterationen.
Optimierungsempfehlungen
Über die Problemerkennung hinaus kann der Agent PySpark- und Spark-SQL-Code aus Performance-Perspektive analysieren und potenzielle Optimierungsmöglichkeiten hervorheben. Dazu gehören effizientere Join-Strategien, das Erkennen unnötiger oder teurer Transformationen sowie Empfehlungen zum Caching, wenn Zwischenergebnisse mehrfach verwendet werden.ple steps.
Diese Empfehlungen sind im Kontext der ETL-Modernisierung besonders wertvoll, weil Legacy-Logik oft direkt, aber nicht unbedingt optimal übersetzt wird. Der Agent hilft, diese Lücke zu schließen, indem er Spark-spezifisches Optimierungswissen einbringt, das bei automatischer Transpilation nicht immer offensichtlich ist. Diese Optimierungsvorschläge sind jedoch nur Empfehlungen und müssen vor der Umsetzung durch Engineers validiert werden.
Limitierungen: Worauf zu achten ist
Auch wenn der LLM-gestützte Workflow klare Vorteile bringt, führt er zugleich Einschränkungen ein, die aktiv gemanagt werden müssen, insbesondere bei False Positives, Kontextverarbeitung und Skalierbarkeit.
False Positives
Auch wenn unser interner Agent Fehler im Code in den meisten Fällen korrekt markierte, sind seine Outputs nicht vollständig deterministisch. In manchen Fällen kennzeichnete er Muster als Problem, die tatsächlich keine Probleme waren, oder interpretierte kontextspezifische Logik falsch. Das trat besonders bei größeren Skripten mit komplexen ETL-Transformationen auf. Hauptgründe sind ein ausgereiztes Kontextfenster und Geschäftsregeln, die implizit bleiben oder nicht ausdrücklich im Code oder in begleitender Dokumentation hinterlegt sind.
Dadurch wird menschliche Validierung zu einem kritischen Bestandteil des Workflows. Jedes Finding muss gegen tatsächliche Anforderungen und erwartetes Verhalten geprüft werden, bevor ein Fix umgesetzt wird. Der Agent sollte daher als Entscheidungsunterstützung verstanden werden, nicht als vollständig verlässlicher Validator. Seine Vorschläge dürfen nie ohne Überprüfung übernommen werden.
Informationsüberlastung, unentdeckte Probleme und Scope-Trade-offs
In manchen Fällen erzeugt der Agent in einer Analyse sehr viele Findings, von denen nicht alle relevant oder korrekt sind. Gleichzeitig kann er relevante Probleme übersehen, die später in menschlichen Review- und Validierungsschritten auffallen. Dieses Verhalten wird typischerweise durch Prompt-Design, die Menge des verarbeiteten Codes und die Strategie für das Kontextmanagement beeinflusst.
In unserem Ansatz haben wir dieses Verhalten reduziert, indem wir Skripte in komponentenbasierte Einheiten aufgeteilt haben. So kann sich der Agent auf kleinere, klar definierte Teile der Pipeline konzentrieren, während gleichzeitig ETL- und Business-Kontext auf Skriptebene erhalten bleibt. Zusätzlich haben wir Prompt-Einschränkungen und Antwortlimits eingeführt, um übermäßige oder unklare Outputs zu verringern.
Dieses Design verbessert Fokus, Zuverlässigkeit und Konsistenz der Analyse. Wie die meisten Designentscheidungen bringt es jedoch Trade-offs mit sich. Wir gewinnen stabilere und präzisere Ergebnisse, reduzieren aber möglicherweise die Sichtbarkeit breiterer, komponentenübergreifender Beziehungen und übergeordneter Logik über die gesamte Pipeline hinweg.
Processing Speed and Scalability
Aus Skalierungsperspektive ist unser Single-Agent-Ansatz auf Komponentenebene einfach und funktioniert gut für repräsentative Skripte, weil er präzise Analyse ermöglicht und zugleich Business-Kontext bewahrt. Die Verarbeitung ist weiterhin deutlich schneller als ein manueller Review, wird aber durch das Single-Agent-Design und Kontextgrenzen stärker limitiert als ein Multi-Agent-Setup. Dadurch ist die Skalierung auf eine große Anzahl von ETL-Jobs anspruchsvoller.
Ein Schritt in Richtung Multi-Agent-Architektur könnte Skalierbarkeit und Durchsatz deutlich verbessern. Er würde jedoch auch erhebliche Architekturkomplexität einführen, was nicht Teil dieser Evaluation ist und im Abschnitt zu den nächsten Schritten weiter betrachtet wird.
Ergebnisse
In unserer Evaluation half der LLM-gestützte Workflow, die initiale Review- und Analysephase zu entlasten. Relevante Probleme wurden sichtbar gemacht und mögliche Fixes vorgeschlagen, sodass Engineers stärker auf die Validierung der Logik fokussieren konnten, statt Code Zeile für Zeile zu analysieren.
Der Ansatz verbesserte die gesamte Validierung, weil Problemerkennung schneller und detaillierter wurde und Konsistenz sowie Zuverlässigkeit durch Feedback über die Zeit zunahmen. Außerdem lieferte er Lösungsvorschläge, die häufig zu bereits erfolgreich eingesetzten Mustern passten und uns schneller zu korrekten Lösungen führten. Insgesamt entstand ein strukturierterer Review-Prozess mit weniger früh übersehenen Problemen und einer klaren Audit-Spur von Findings und Entscheidungen, die technische Entscheidungen besser absicherte.
Gleichzeitig bleibt der Ansatz durch Herausforderungen bei Determinismus, Kontextverarbeitung und Skalierbarkeit begrenzt. Menschliche Aufsicht sowie abschließende Tests und Validierung bleiben daher unverzichtbar, um Genauigkeit und Übereinstimmung mit fachlichen Erwartungen sicherzustellen.
Der nächste Abschnitt baut auf diesen Erkenntnissen auf und zeigt, wie diese Grundlage zu einer skalierbareren und stärker automatisierten Architektur erweitert werden kann.
Nächste Schritte: Automatisierung und Skalierung mit einem Multi-Agent-Ansatz
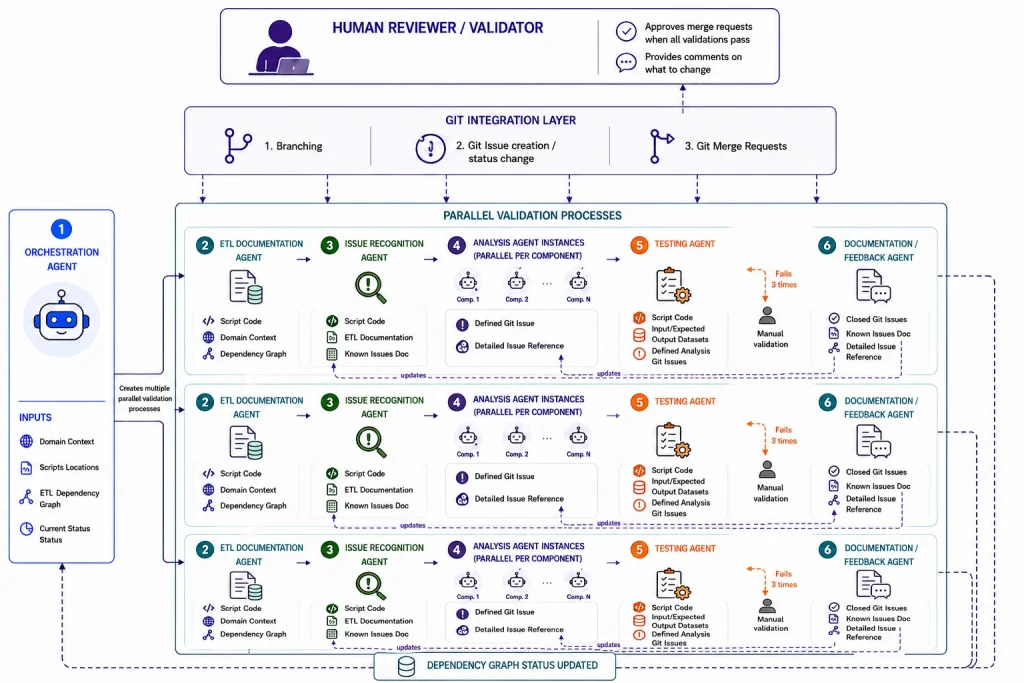
Obwohl sich unser Ansatz für den betrachteten Migrationsumfang als tragfähige Lösung erwiesen hat, sehen wir auf Basis unserer breiteren Erfahrung mit KI klare Möglichkeiten, ihn weiter zu verbessern. Das gilt insbesondere für stärkere Automatisierung und die Skalierung zu einem Multi-Agent-Setup.
Im Kern bedeutet das, über einen einzelnen sequenziellen LLM-Validierungsworkflow hinauszugehen und ein dependency-driven Multi-Agent-System aufzubauen, in dem Verantwortlichkeiten auf spezialisierte Agenten verteilt sind. Das ermöglicht parallele Validierung in größerem Maßstab, reduziert Kontextüberlastung und macht den gesamten Workflow effizienter, wenn die Komplexität steigt.
Bevor dieses System arbeiten kann, muss jedoch zunächst die vollständige Assessment-Phase der Migration abgeschlossen sein. Diese Phase ist Voraussetzung für das Multi-Agent-Setup, weil sie Dependency Graph, Ausführungsreihenfolge und Orchestrierungsgrenzen der ETL-Workflows festlegt und den essenziellen Domänenkontext bereitstellt, der für präzise Validierung, Analyse und Koordination erforderlich ist.
Unser erweiterter Ansatz ist in der folgenden Abbildung dargestellt:
Die Grundlage bildet ein dependency-aware Orchestration Agent, der den ETL-Dependency-Graph kontinuierlich bewertet und bestimmt, welche Skripte für die Validierung bereit sind. Seine Verantwortung ist bewusst darauf begrenzt, Validierungsbranches, also Validierungsprozesse, nur für Skripte zu erstellen, deren Abhängigkeiten bereits abgeschlossen sind. Sobald ein validation-Branch erstellt wurde, läuft der verbleibende Workflow autonom über Git-getriebene Events weiter: Branch-Erstellung, Issue-Erstellung, Merge Requests und Statusänderungen von Issues lösen automatisch die jeweils nächsten Agenten in der Pipeline aus.
Innerhalb jedes Validierungsprozesses konzentrieren sich spezialisierte Agenten auf klar definierte Verantwortlichkeiten. Der ETL Documentation Agent erstellt einen eigenen ETL_documentation-Branch und analysiert das einzelne Skript, das gerade validiert wird, gemeinsam mit seinem Business- und Dependency-Kontext. Daraus erzeugt er standardisierte ETL-Dokumentation und merged sie anschließend in den validation-Branch, optional mit menschlichem Review und zusätzlichen Änderungsanforderungen.
Danach liest der Issue Recognition Agent das Skript Komponente für Komponente und bewertet jede Komponente einzeln. Für jede Komponente erstellt er ein separates Git Issue, wenn sie entweder zu einem Eintrag im Known Issues Document passt oder wenn der Issue Recognition Agent auf Basis seines allgemeinen Python- und Spark-Wissens ein potenzielles Problem oder eine Fehlimplementierung erkennt. In der Git-Issue-Beschreibung referenziert der Agent den Komponenten-Codeblock, alle passenden Problemmuster und Kategorien, die ETL-Dokumentation sowie fachlichen Kontext.
Dieses Design erlaubt es Analysis Agents, unabhängig und parallel zu arbeiten, wobei jeder Agent ein einzelnes Git Issue des Issue Recognition Agent verarbeitet. Jeder Analysis Agent verschiebt das Git Issue in den Status “In Analysis” und prüft den gesamten zugehörigen Beschreibungskontext, einschließlich Code, Detailed Issue Reference Document und relevantem ETL- beziehungsweise Domänenkontext.
Auf Basis dieser Informationen plus allgemeinem Python- und Spark-Wissen klassifiziert der Agent jedes Problem als gültig oder ungültig. Gültige Probleme werden mit einer empfohlenen Remediation verknüpft, die auf bereits verifizierten Lösungen aus dem Detailed Issue Reference Document sowie allgemeinen Best-Practice-Mustern für Spark und PySpark basiert. Ungültige Probleme werden ausdrücklich abgelehnt und begründet. Am Ende wird jedes Git Issue in den Status “Ready for Testing” verschoben und enthält einen strukturierten Bericht, der alle Probleme konsolidiert, nach Gültigkeit, Komponente und Kategorie ordnet und sie mit relevantem Kontext und empfohlener Lösung in einem konsistenten, review-fähigen Format darstellt.
Sobald alle Git Issues den Status “Ready for Testing” erreicht haben, validiert ein dedizierter Testing Agent das Skript gegen vordefinierte Eingabe- und erwartete Ausgabedaten. Der Agent führt die Pipeline iterativ aus und erstellt für jeden fehlgeschlagenen Versuch einen separaten testing-Branch, auf dem er Remediation-Strategien aus den Git Issues anwendet, die zum jeweiligen Komponententyp passen. Anschließend führt er die Pipeline erneut aus, bis die generierten Ausgaben vollständig den erwarteten Ergebnissen entsprechen.
Danach erstellt er einen Git Merge Request zum validation-Branch. Deterministische und bereits validierte Fixes können automatisch freigegeben werden, während komplexere oder unsichere Codeänderungen sowie wiederholt fehlschlagende Szenarien nach definierten Retry-Schwellen an menschliche Reviewer eskalieren.
Nach erfolgreichem Testing konsolidiert der Documentation/Feedback Agent das Wissen aus dem gesamten Validierungsprozess. Seine Hauptaufgabe besteht nicht darin, das Skript selbst zu validieren, sondern die zukünftige Entscheidungsfähigkeit des Systems kontinuierlich zu verbessern. Er prüft alle gelösten komponentenbezogenen Git Issues, Remediation-Ergebnisse, Testing-Erkenntnisse und menschliches Feedback, um Known Issues Documents und Detailed Issue Reference Documents zu aktualisieren. Dazu gehört, neu validierte Remediation-Muster aufzunehmen, ungenaue Empfehlungen zu verfeinern, veraltete Issue-Mappings zu entfernen und Kontextreferenzen für zukünftige Migrationen zu verbessern. So stärkt jedes erfolgreich validierte Skript schrittweise Qualität und Genauigkeit künftiger automatisierter Validierungen.
Zur Unterstützung von Koordination und Traceability setzt das Framework stark auf Git-basierte Workflows. Branch-Erstellung, Issue-Management, Merge Requests, Kommentare und Freigaben werden zum Kommunikationsmechanismus zwischen Agenten und stellen zugleich die vollständige Nachvollziehbarkeit des Validierungsprozesses sicher.
In diesem Modell entwickelt sich die Rolle der Engineers weg von wiederholenden Validierungsaufgaben hin zur Aufsicht und Governance der Abläufe. Menschliche Reviewer konzentrieren sich vor allem auf Architekturaufsicht, Eskalationsfälle und Freigabe finaler Remediation-Ergebnisse, während Agenten den Großteil operativer Dokumentation, Problemanalyse, Tests und Remediation über den gesamten Migrationsworkflow hinweg automatisieren.
Outro
Über diese Serie hinweg haben wir betrachtet, wie Organisationen ETL-Systeme modernisieren können, indem sie sich von Legacy-Warehouse-Plattformen lösen und zu Lakehouse-Architekturen wie Databricks wechseln. Anschließend haben wir gezeigt, wie sich ein großer Teil der ETL-Migrationsphase mit Databricks Lakebridge automatisieren lässt. Lakebridge konvertiert bestehende ETL-Logik schnell in PySpark und Spark SQL, erfordert aber weiterhin einen dedizierten Validierungsschritt, damit der generierte Code logisch korrekt ist, dem erwarteten Business-Verhalten entspricht und bereit für den produktiven Einsatz wird.
Darauf aufbauend haben wir den Validierungsschritt gestärkt, indem wir unseren internen LLM-Agenten Jarvis eingeführt haben. Er wurde genutzt, um transpilierten PySpark- und Spark-SQL-Code zu analysieren, Syntax- und Logikprobleme zu erkennen, Verbesserungen vorzuschlagen und Engineers dabei zu unterstützen, die Lücke zwischen automatisch generiertem Code und produktionsreifen Pipelines systematisch zu schließen. Außerdem haben wir nächste Entwicklungsschritte skizziert, in denen sich der Ansatz zu einem dependency-driven Multi-Agent-System weiterentwickelt, das parallele Validierung ermöglicht, Kontextüberlastung reduziert und das End-to-End-Reasoning über Pipelines verbessert.
Zusammen zeigt diese Blogserie, dass moderne Ansätze der ETL-Modernisierung den Fokus zunehmend darauf legen, ETL-Migration zu beschleunigen und gleichzeitig die sorgfältige Balance zwischen Automatisierung und menschlicher Validierung zu wahren. Nur so lassen sich Korrektheit, Zuverlässigkeit und Produktionsreife der finalen Datenpipelines sicherstellen.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.



