Imagine moving your data into a solid, well-built place, the kind that’s been designed brick by brick to last, just like those classic apartments in New York. And once you’re settled in, you can finally open a beer, sit back, chat with your AI buddy, and enjoy some well-earned peace, while your data flows effortlessly in the background.
Sounds like something you’d enjoy, doesn’t it? Well, good news then, you’re in the right place.
Chances are, you’re working with a data warehouse that has been growing for years, supporting critical reporting and analytics. Over time, however, it has also become more expensive, slower, and increasingly complex to maintain. And at some point, the question inevitably comes up: what now?
Do you keep optimizing what you already have, or is it time to rethink the foundation entirely?
One of the answers many organizations are exploring today is the Lakehouse approach, a more flexible and scalable way to unify data engineering, analytics, and AI workloads on a single platform as part of broader ETL modernization efforts.
However, migrating a traditional Data Warehouse system to a Lakehouse is far from a lift-and-shift exercise. It is a complex and time-consuming effort that involves much more than simply moving data from one platform to another, which we explore through a three-part series on modernizing legacy ETL workloads with Databricks, based on our migration from Informatica and Oracle to a Lakehouse.
In the first part, we cover the migration context, phases, and key challenges, with a focus on ETL transformation. In the second part, we dive into ETL migration in practice using Databricks Lakebridge, and in the third part, we explore how AI can further enhance ETL modernization.
So stay tuned, don’t run away just yet.
The challenge(s)
Moving into a new place seems simple until you find that not everything fits as expected. Plumbing may require adjustments, and wiring might be incompatible, or the layout doesn’t quite support how you want to live.
The same applies when migrating from a traditional data warehouse to a lakehouse platform.
The challenge begins with understanding the current landscape and not just at a high level, but in detail. This includes gathering metadata, governance information, and mapping out how data assets, pipelines, and dependencies are interconnected across the entire platform. In many organizations, this knowledge is fragmented, partially documented, or embedded in legacy systems and individual expertise. Don’t ask me how I know that.
Only once this foundation is established can organizations begin translating existing logic into the ETL pipelines and schema definitions required by the target platform. However, this is rarely a straightforward translation as differences in architecture, processing paradigms, and data handling approaches often require redesign rather than direct migration.
When approached manually, this process quickly becomes time-consuming, error-prone, and difficult to scale. Hidden dependencies, undocumented transformations, and tightly coupled workflows introduce additional complexity, increasing both the risk and the effort required for a successful migration.
When it comes to choosing the right platform for this kind of transition, the decision becomes critical. In our case, we chose Databricks as the target platform based on the client’s specific requirements and future needs. Beyond its Lakehouse architecture, it provided a solid foundation that could support both current workloads and expected growth.
The platform aligned well with requirements for scalability, flexibility, and support for traditional analytics, while also being ready to accommodate more advanced AI/ML use cases in the future. It also addressed needs related to governance, data management, and integration within a unified environment, helping reduce the complexity typically found in such ecosystems. Brick by brick, our journey towards a Lakehouse began.
After the platform is decided on, the real challenge begins: migrating existing workloads, especially complex ETL logic that is at the heart of ETL modernization. When moving into a new place, this is the moment you discover that the pipes need replacing and you have to do it carefully, without flooding the entire apartment.
So how do we tackle these challenges and turn the Databricks Lakehouse into a place where your data flows freely? The answer lies in approaching the migration through a series of structured steps.
Migration steps
Just like moving into a new place, there is a logical order to follow. You wouldn’t start by laying down new flooring, only to tear it out later because the plumbing needs fixing. Instead, you begin with inspection, plan the layout, take care of the underlying infrastructure, and only then move on to finishing touches.
The same applies to migration, where each step builds on the previous one, and getting the order right is key.
In our experience, a migration from a traditional data warehouse to a Lakehouse platform is most effectively approached as a series of structured phases executed in the right order, as illustrated in the diagram below.
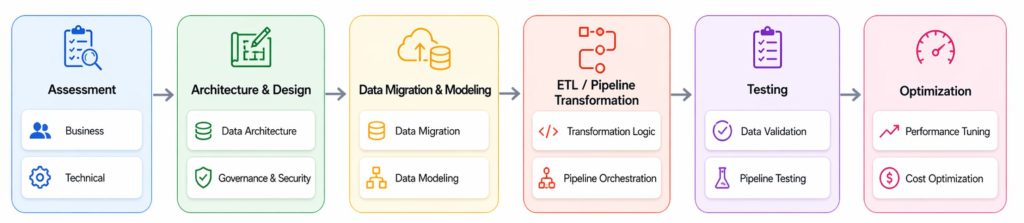
Let’s take a closer look at each of these phases and what they typically involve.
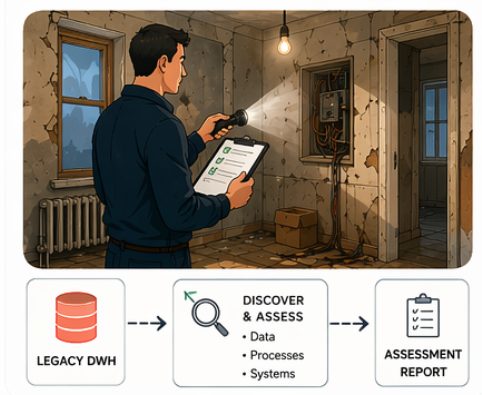
Assessment
This phase focuses on building a complete picture of the current landscape, from both a business and architectural perspective. In practice, this is often where hidden complexity starts to surface. Dependencies between systems, undocumented data sources and workflows, lack of governance, and inconsistencies in how data is defined and used across the organization.
From a business perspective, this phase often raises questions such as:
- Which use cases are critical?
- What data is actually being used and by whom?
- And which capabilities need to be preserved or improved in the new platform?
From a technical perspective, the focus shifts to understanding how things really work under the hood:
- How are data pipelines structured?
- Where are the dependencies?
- Which transformations are reusable, and which require redesign?
These insights need to be clearly documented. This typically includes mapping data flows, capturing dependencies, and identifying key transformation logic that will need to be migrated or reimplemented.
In our case, this meant extracting information directly from existing repositories to understand which workflows were running, how they were scheduled, and how they were connected. We organized this into structured formats, such as spreadsheets, and complemented it with high-level diagrams to visualize data flows and dependencies across the system.
We also documented access patterns, who has access to which data, which reports are actively used, and which ones are no longer relevant.
While this was specific to our use case, similar patterns tend to appear in many organizations. A significant portion of this knowledge is often scattered across tools, systems, and individual expertise.
As a result of this phase, organizations gain a clear understanding of both business and technical requirements, as well as the current system’s limitations and opportunities for improvement.
These insights form the foundation for key decisions, including the selection of the target platform, the definition of the future architecture, and the identification of migration priorities and approaches.
Databricks naturally emerged as the platform of choice for our use case, aligning with the technical requirements identified during the assessment and the need for a scalable, unified platform to support analytics, data engineering, and AI workloads.
Like moving into a new apartment, you start by walking through the space, deciding which walls stay and which need to be torn down, uncovering hidden issues like wiring and pipes, and assessing what can be reused without causing problems later. You then decide which contractors to bring in and plan the work to avoid unexpected problems.
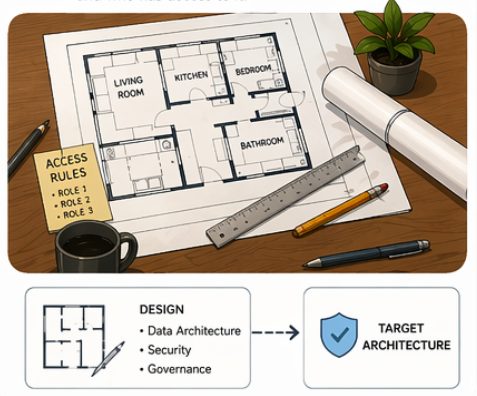
Architecture and Design
After completing the assessment phase, the focus shifts to defining the target architecture and governance approach. This phase builds on the insights gathered earlier and translates them into a structured design for the future platform.
From a data architecture perspective, this includes defining how data will be organized, stored, and accessed, e.g., designing data layers and defining access patterns. It also involves decisions around how different workloads will be supported, including reporting and BI use cases, and how these will integrate with the overall data platform.
In addition to defining the overall structure, this phase also establishes how data will be governed and secured across the platform, including access control, data ownership, and compliance considerations.
In practice, this phase is rarely straightforward and often raises questions such as:
- Where should data reside across different layers?
- How should access be managed across teams and use cases?
- How should governance policies be applied and enforced consistently?
- How will data be consumed by downstream systems, such as BI and analytics tools?
- How can the architecture support both current and future requirements?
In our experience, this is also where close collaboration with business stakeholders becomes essential, as decisions made at this stage directly impact how data will be used.
We found that this often requires a significant amount of explanation and alignment with business users, when it comes to both architecture and governance. Concepts such as data layers, access patterns, data ownership, and responsibility are not always immediately intuitive, and need to be clearly defined and agreed upon early in the process.
This stage is like planning how your apartment will actually be lived in, where things go and how the space will function in everyday use. Once everything is set up, you don’t want to keep changing things randomly or using the space in ways it wasn’t designed for, e.g., turning the living room into a bedroom.
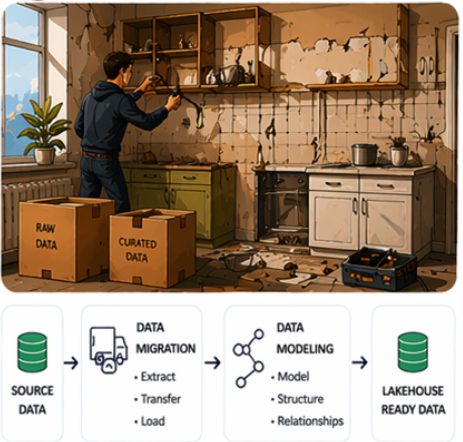
Data migration and Modeling
At first glance, data migration might seem like a straightforward step but in reality, it is rarely that simple. Data volumes can be significant, data quality may vary, and differences in formats, structures, and storage models often require additional handling. At the same time, existing data models need to be adapted to fit the target platform, making this phase both a technical and design challenge.
From a data migration perspective, ensuring consistency, completeness, and minimal disruption during the transfer becomes a key concern. This often involves dealing with large data volumes, varying data quality, and maintaining alignment between source and target systems during the transition period.
From a data modeling perspective, the challenge lies in deciding how data should be organized in the new platform, as traditional data warehouse layers cannot be directly translated to a lakehouse architecture.
This typically involves rethinking existing schemas rather than simply replicating them and organizing data across logical layers such as bronze (raw data), silver (cleaned and enriched), and gold (business-ready datasets), ensuring that each layer serves a clear purpose and supports downstream use cases.
This phase often raises questions such as:
- What data should be migrated first?
- How do we handle historical data?
- How do we ensure that the migrated data remains consistent with the source during the transition period?
- Does the bronze layer contains only raw data?
- What storage formats and table structures should be used?
In our case, working with an Oracle-based data warehouse, this meant understanding how existing data structures translate to Databricks and making decisions around storage formats and table structures, as well as how to organize data across layers.
For example, choosing between Delta and Iceberg table formats depended on requirements such as incremental updates, data consistency, and performance optimization.
Like moving into a new apartment and walking into the kitchen, you might find the current setup inadequate, especially if you plan to bake and cook more than usual in the future. The old kitchen is being taken apart, cabinets are removed, appliances disconnected, and you start deciding what needs to go and what can be reused, and planning the new layout.
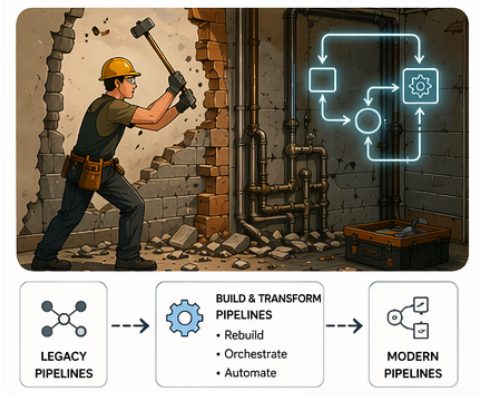
ETL/Pipeline Transformation
While all phases are important, in practice, this step often represents the most complex and resource-intensive part of the overall migration, and is typically at the core of any ETL modernization effort , especially when dealing with legacy ETL tools and deeply embedded business logic.
Unlike data migration, which focuses on moving data, this phase requires rethinking how data is processed, often translating or redesigning existing logic to fit a completely different execution model.
This phase often raises questions such as:
- How can existing transformation logic be translated or redesigned for the target platform?
- Which parts of the logic can be reused, and which require a complete rewrite?
- How do we handle complex dependencies between pipelines and workflows?
- How should workflows be orchestrated to ensure reliability and scalability?
- And how can we validate that the transformed pipelines produce consistent and accurate results?
In our case, working with Informatica PowerCenter and Oracle required unpacking years of accumulated logic to transition it effectively to the Databricks Lakehouse. For example, certain Informatica-specific concepts, such as session-based execution, could not be directly translated and required redesign.
We also rethought pipeline orchestration: scheduling workflows, managing dependencies, and ensuring reliable, scalable data flow across the system.
In practice, many organizations encounter similar challenges. Legacy ETL environments often contain tightly coupled workflows, implicit dependencies, and execution patterns that only become visible during transformation.
Addressing this challenge also goes beyond manual effort. It requires a more structured and, increasingly, automated approach supported by AI to handle the scale and complexity involved.
One approach that worked well for us was selecting a representative workflow and using it as a pilot to better understand the challenges, test different approaches, and validate assumptions before scaling further.
Much like renovating an apartment, this is the stage where you’re breaking down walls, reworking the plumbing, and making sure everything fits together in a completely new layout. And don’t forget about the kitchen, this is where everything behind the scenes gets connected, and you finally turn on the water to see if it actually flows as expected.
We’ll explore this approach in more detail in the next part of this blog series, where we dive deeper into ETL transformation challenges and how tools like Databricks Lakebridge can help address them in practice. In the final part, we’ll also take a closer look at how AI can further support and enhance this transformation.
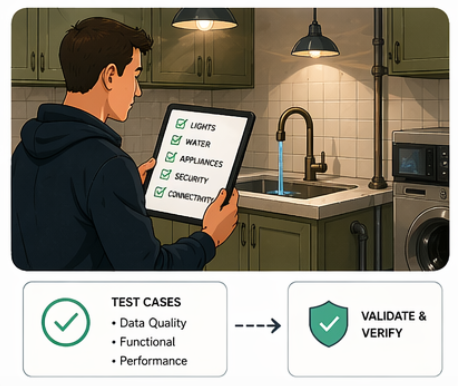
Testing
Once the data and transformations are in place, we need to to ensure that pipelines execute as expected and that the resulting data is accurate, consistent, and complete across the new platform.
From a data validation perspective, this means ensuring that the migrated data aligns with the source systems in terms of structure, volume, and business meaning.
In our case, we quickly realized that manual validation is not scalable. To address this, we developed a lightweight testing framework within Databricks, enabling automated validation of key data pipelines and transformation logic. This included checks for data quality, schema consistency, and reconciliation with source systems, helping us catch issues early and ensure confidence in the migrated workloads.
We leveraged native Databricks capabilities to integrate testing into our pipelines, reusing some validation patterns from Informatica and adapting others for a more automated, distributed environment.
Beyond data validation, we have done pipeline testing to ensure workflows execute reliably, dependencies are handled correctly, and failures are detected and managed. In a Databricks environment, that also means monitoring performance and cost to ensure pipelines are correct and efficient in resource use.
In practice, having automated tests in place is not just a nice-to-have, it is essential for maintaining reliability as the migration progresses. As pipelines evolve and new components emerge, automated testing ensures changes do not break existing functionality, enabling faster iteration and controlled scaling of the solution.
Like moving into a new apartment, this stage involves testing everything before settling in, checking lights, water flow, and appliance function to avoid problems during daily use.
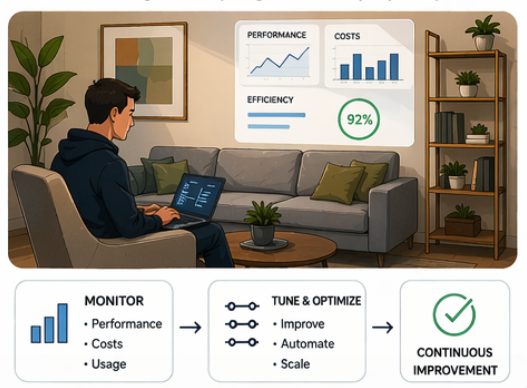
Optimization
The final phase is optimization, focusing on improving performance and ensuring the platform can scale effectively with increasing demands. This includes tuning data pipelines, optimizing storage and query performance, and managing resource utilization to balance performance and cost.
From a performance perspective, this may involve optimizing transformations, partitioning strategies, and query execution while from a cost perspective, it means ensuring that compute resources are used efficiently and that workloads are appropriately sized for their purpose.
In a Databricks environment, this means actively monitoring resource usage and costs by understanding how jobs consume compute, identifying inefficient workloads, and adjusting configurations. We used system tables to extract cost and usage data and built a custom dashboard to track job execution, cluster utilization, and workload behavior, improving visibility and enabling informed optimization.
Although we used Databricks, the principle applies broadly: cost visibility and control become essential as modern data architectures scale.
In our experience, this phase is often iterative. Initial implementations may work functionally, but require refinement to fully leverage the capabilities of the target platform. As usage grows and new requirements emerge, continuous monitoring and adjustments become essential.
Like settling into a new place, this is where you start fine-tuning things, adjusting heating, rearranging furniture, fixing small issues, and making sure everything runs efficiently over time.
Outro
Just like settling into a new place, a successful migration is about understanding what needs to be fixed, what can be improved, and how everything fits together in the long run.
Migrating from a traditional data warehouse to a Lakehouse is not just a technical transition, but a structured journey that requires the right decisions at each step, from understanding the current landscape to redesigning and transforming how data is processed.
While every phase plays a role, the real complexity often lies in ETL/Pipeline transformation, which sits at the core of any ETL modernization effort , where existing logic needs to be rethought and adapted to a new execution model.
In the next part, we take a closer look at this phase in practice, focusing on ETL transformation using Databricks Lakebridge, followed by a final part where we will talk how AI can further support and evolve ETL modernization.
And just like with any new place, once everything is in place, optimized, and running smoothly, you can finally sit back, relax, and enjoy that well deserved beer.




