

Speaking of modern data streaming systems, it’s almost impossible not to mention Apache Kafka. We at CROZ have been using Kafka for many years now, so we gathered our experience in a course you can read more about in this article.
Apache Kafka is an open-source distributed event streaming platform. Kafka is used for high-performance data pipelines, streaming analytics, data integration and mission-critical applications. Many companies use Kafka through Kafka Producers, Kafka Consumers, Kafka Streams, Flink applications and Spark applications.
Event streaming is applied to a wide variety of use cases across a plethora of industries and organizations. Some examples of use cases would be:
- to process payments and financial transactions in real-time (stock exchanges, banks and insurances)
- to track and monitor cars, trucks, fleets, and shipments in real-time (logistics and the automotive industry)
- to continuously capture and analyze sensor data from IoT devices or other equipment (factories, wind parks, etc.)
- to collect and immediately react to customer interactions and orders (retail, the hotel and travel industry, and mobile applications)
In our Kafka course, attendees will go through the process of building the entire system on Apache Kafka, the system that will collect and process sensor data from weather stations. We use this topic because it’s a great example showing interesting data and different measurement stations. The idea of this example is processing the data and calculating sensitive measures (e.g. average) in some particular time window.
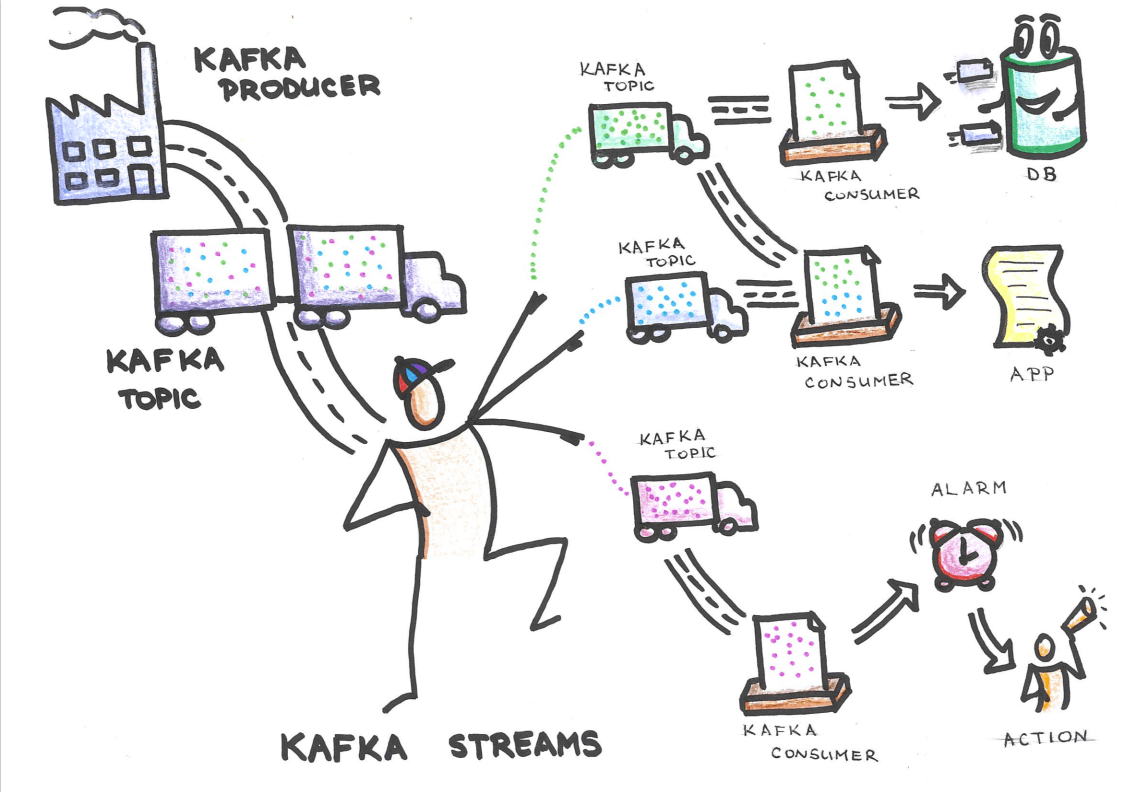
System architecture
The Kafka producer in the upper left corner is the factory producer. The factory producer will send measurements to Kafka topic. The project has many factories because every factory is actually a measurement station. Kafka is connected to the Kafka Streams application that groups measures and reduces the amount of data. After that, consumers are subscribed to Kafka topic and they process data from the topics. Consumers can save data into a database or activate alarms when measurements have a value higher than the defined bound.
Measurement station and Kafka Streams applications are implemented in the Java programming language. We developed examples with consumer applications so you can see consumers in the pure Java and the Java framework Spring Boot.
Besides, there is Elasticsearch which saves measurements and allows us to search and visualize measurements with Kibana.
The Apache Kafka Course
We offer the five days Kafka course covering all important aspects and components of Apache Kafka. If you find some topics more interesting than others, you can choose to participate only in a part of the course, not necessarily in all five days. For example, if you want to learn more about the basics of Kafka and then jump into sysadmin stuff and how to secure Kafka cluster, we would be more than happy to welcome you on the first, fourth, and fifth day of the course.
The first three days of the course are mostly focused on:
- introduction to Kafka
- working with Kafka Connect
- developing Kafka consumers, producers, and Kafka Streams applications in Java
The last two days of the course might be more interesting to system administrators looking to learn more on
- how to deploy, secure and monitor Apache Kafka
If you find this course interesting, feel free to look into more details on the following link and let’s get in touch.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.


