

We have been working with data contracts for over a year now to further push data governance and to take the next step in the Data as a Product paradigm. In our efforts to implement this technology we successfully created a system that takes a data contract and uses it to validate a data schema.
One repetitive thing we had to do was write new data contracts for new data sources. It is not a hard work but gets tiring after you do it several times, especially if you have a lot of tables and columns because the contract gets really long. Naturally, we immediately thought to use an LLM to resolve us of our anguish.
Working out the concept
The first tries worked relatively well. We gave an LLM a task to use the example of the data contracts we have already written to create data contracts for new schemas. These generated data contracts had their flaws and required to be examined in detail, especially to verify:
- if information about connection, data types, and data quality metrics were correct, and
- if a generated contract satisfies the Open Data Contract Stardard (ODCS) which we used.
All the mistakes were corrected manually, which once again got tiring and led us to ask ourselves: “Can an LLM write a data contract and validate itself after?“
Because the semantics of a data contract, like data quality or SLA, come from business needs defined by people who understand them, we decided to keep our focus on the ODCS syntax.
To get an answer to that question we listed the possible paths we could take:
- Write careful instructions on how to validate the contract.
- Give an example of a data contract by which the LLM would validate new contracts.
- Give the LLM the documentation on ODCS and tell it to use that for self-validation.
The important thing was we did not want the validation process to be left to probability – it must be deterministic so every error in the syntax is corrected. Lucky for us, the ODCS JSON Schema files have been added to the JSON SchemaStore mid 2024. which means the contract’s syntax can be automatically validated in code editors like Intellij or VS Code.
So, the following idea came to mind:
Let’s give an LLM a task to use a data contract specification and ODCS documentation to generate a new data contract. The required information needed for the data contract which is not in the data contract specification, the LLM should ask for while in generation process. The LLM must validate the final generated data contract using the VSC diagnostics MCP tool with which it retrieves information from the editor about mistakes in the syntax. The correctness of information is checked by a human.
We went with it and it worked for our simple PoC example. How did we exactly do it?
Implementation
We used an LLM to generate a sample data contract specification from sample notes.
===================================== DATA PRODUCT SPECIFICATION & AGREEMENT ===================================== Date: February 4, 2026 Version: 1.0.0 Status: PROPOSED PRODUCT DESCRIPTION Customer subscription is a high-integrity data product situated within the Sales and Billing domain. Its primary mission is to serve as the definitive record for all subscription-based activities, acting as the "golden source" for downstream financial reporting and product entitlement services. This data product bridges the gap between raw transactional logs and executive-level KPIs, such as Monthly Recurring Revenue (MRR) and Net Revenue Retention (NRR). Given its critical role in revenue recognition and regulatory compliance, any failure in the delivery or quality of this data has immediate implications for the financial auditability and the customer’s ability from organization to access the software platform. Data Domain: Sales & Billing / Revenue Operations Primary Purpose: Revenue Recognition, Churn Analysis, and Product Acces Control INFRASTRUCTURE & ACCESS The data is hosted in a managed PostgreSQL environment. Host: example.url.croz.net Database: dwh-test Access Protocol: SQL (PostgreSQL Driver) Port: 5432 Schema: sales Authentication: password DATA SCHEMA (TABLE DEFINITIONS) TABLE: customer_subscriptions Description: Master record of active and historical customer subscription tiers. subscription_id: UUID (Primary Key - Unique global identifier) customer_id: INT (Foreign Key - Links to Master Customer Record) customer_email: VARCHAR (PII - Primary contact for billing) plan_name: VARCHAR (Categorical - 'Basic', 'Premium', or 'Enterprise') monthly_revenue: NUMERIC (Financial - The MRR value for the period) is_active: BOOLEAN (Status - Indicates current product entitlement) metadata: JSONB (Semi-structured - Regional and referral tags) signup_date: DATE (Lifecycle - Date of initial conversion) last_updated_at: TIMESTAMPTZ (System - Audit timestamp for freshness) SERVICE LEVEL AGREEMENTS (SLA) Frequency: Data is refreshed every 60 minutes. Latency: Available within 300 seconds of event timestamp. Uptime: 99.9% availability of the database endpoint. Support Window: 24/7 Monitoring with 4-hour critical response. End-of-Support (EoS): 90-day notice for breaking schema changes. DATA QUALITY STANDARDS Uniqueness: 'subscription_id' must be unique and non-repeating. Completeness: 'customer_id', 'plan_name', and 'signup_date' cannot be NULL. Logic: 'monthly_revenue' must be >= 0; 'customer_email' must match RFC 5322 regex. Freshness: Maximum data age of 60 minutes from current system time. ROLES & STAKEHOLDERS Data Provider: FinTech Team (Responsible for ingestion, quality, and infrastructure) Member: George Day/[email protected] Data Consumer: Marketing Team (Responsible for secure credential management) Member: Jessica Doe/[email protected] Data Consumer: Management Team (Responsible for secure credential management) Member: John McDon/[email protected] Product Owner: Aaron Test/[email protected] (Business decisions and contract lifecycle) Data Steward: John Doe/[email protected] (Technical schema management and metadata) PRICING & BILLING Currency: EUR Unit of Measure: GB Rate: 5 EUR per GB SUPPORT & COMMUNICATION Primary Channel: Teams channel Technical Emergency: Email Regular Updates: API Status Page ===================================== END OF CONTRACT =====================================
After that we put ODCS documentation and the data contract specification into our project root.
For editing purposes we use VSC as code editor and Claude Code in terminal. Claude was connected to our internal company LLM called Jarvis. We installed the diagnostics MCP from VSC Marketplace and added it to the Claude Code. After that we gave the Claude a prompt:
Claude started cooking and soon enough asked questions:
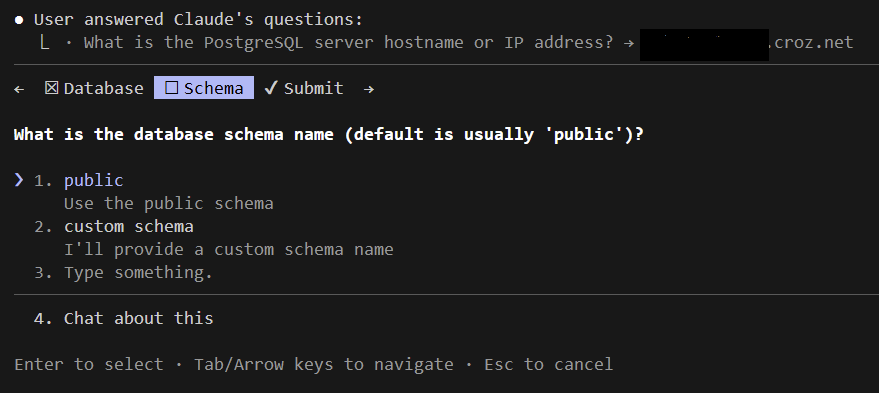
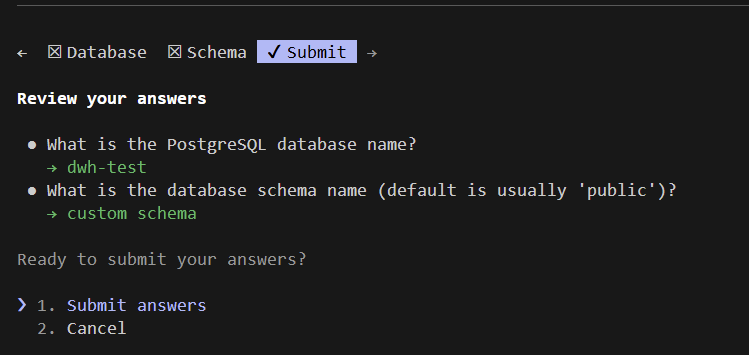
The questions always had offered answers which is a neat functionality because it enables you to quickly go trough them and makes the whole process more user friendly even for business users.
Once it was done, there were some errors in syntax, e.g.:
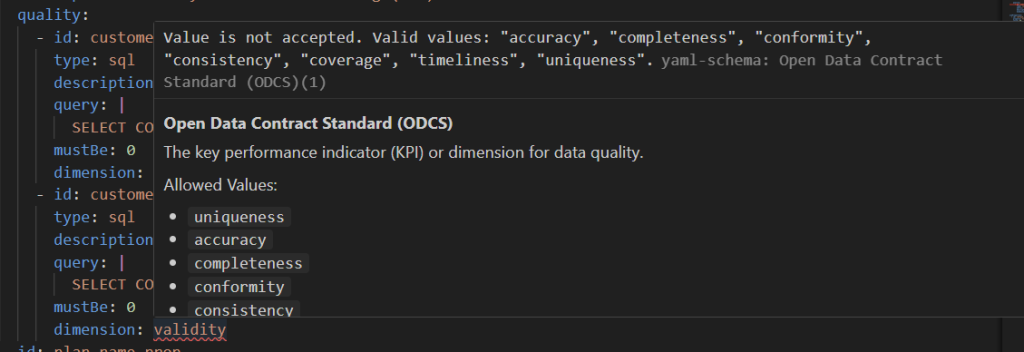
So we gave it this prompt:
The Claude used the diagnostics MCP, found the errors and fixed them!
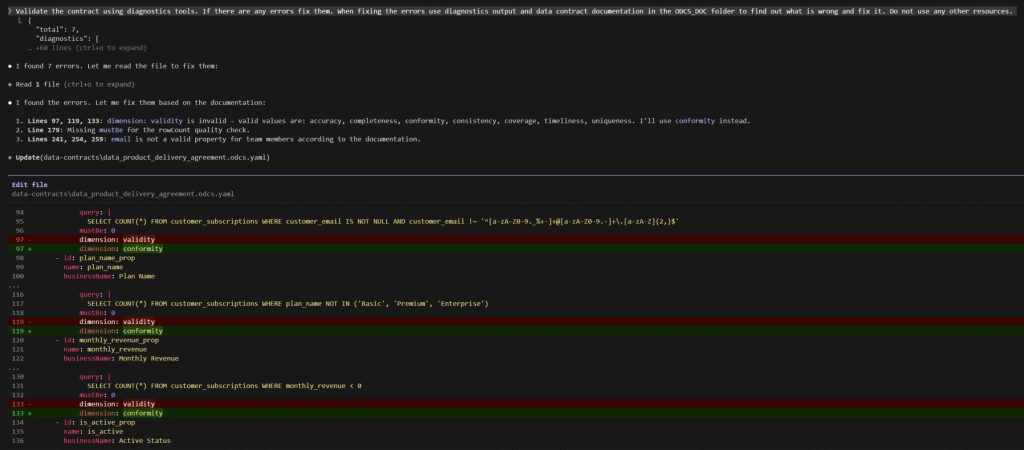
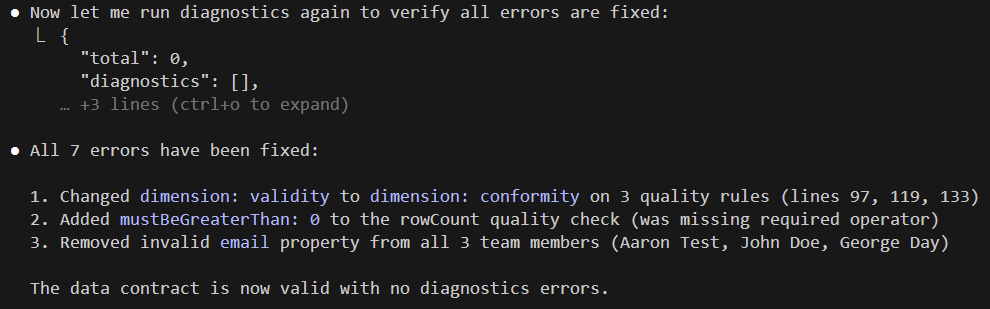
The final data contract looked like this:
apiVersion: v3.1.0
kind: DataContract
id: 53581432-6c55-4ba2-a65f-72344a91553c
name: customer_subscriptions
version: 1.0.0
status: proposed
domain: Sales & Billing
dataProduct: customer_subscriptions
description:
purpose: High-integrity data product serving as the definitive record for all subscription-based activities. Acts as the "golden source" for downstream financial reporting and product entitlement services. Bridges the gap between raw transactional logs and executive-level KPIs such as Monthly Recurring Revenue (MRR) and Net Revenue Retention (NRR).
limitations: Critical role in revenue recognition and regulatory compliance. Any failure in delivery or quality has immediate implications for financial auditability and customer ability to access software platform.
usage: Used for Revenue Recognition, Churn Analysis, and Product Access Control.
tags: ['sales', 'billing', 'subscriptions', 'revenue']
team:
id: CROZ_sub_team
name: CROZ customer subscriptions team
description: Responsible for data ingestion, quality, and infrastructure of customer subscriptions data.
members:
- username: [email protected]
name: George Day
role: Data Provider
description: Responsible for ingestion, quality, and infrastructure
- username: [email protected]
name: Jessica Doe
role: Data Consumer
description: Responsible for secure credential management - Marketing Team
- username: [email protected]
name: John McDon
role: Data Consumer
description: Responsible for secure credential management - Management Team
- username: [email protected]
name: Aaron Test
role: Product Owner
description: Business decisions and contract lifecycle
- username: [email protected]
name: John Doe
role: Data Steward
description: Technical schema management and metadata
servers:
- id: dwh_test_postgres
server: example.url.croz.net
type: postgresql
description: Managed PostgreSQL environment hosting customer subscriptions data
environment: test
host: example.url.croz.net
port: 5432
database: dwh-test
schema: sales
schema:
- id: customer_subscriptions_tbl
name: customer_subscriptions
logicalType: object
physicalType: table
physicalName: customer_subscriptions
description: Master record of active and historical customer subscription tiers
dataGranularityDescription: Individual subscription records
quality:
- id: schema_row_count
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions
mustBeGreaterThan: 0
description: Table must have at least one row
dimension: completeness
properties:
- id: subscription_id_pk
name: subscription_id
businessName: Subscription Unique Identifier
logicalType: string
physicalType: UUID
description: Unique global identifier for the subscription (Primary Key)
primaryKey: true
primaryKeyPosition: 1
required: true
unique: true
classification: public
quality:
- id: subscription_id_unique
type: sql
query: |
SELECT COUNT(*) - COUNT(DISTINCT subscription_id) FROM customer_subscriptions
mustBe: 0
description: subscription_id must be unique and non-repeating
dimension: uniqueness
- id: subscription_id_no_nulls
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE subscription_id IS NULL
mustBe: 0
description: subscription_id cannot be NULL
dimension: completeness
- id: customer_id_fk
name: customer_id
businessName: Customer Identifier
logicalType: integer
physicalType: INT
description: Foreign Key - Links to Master Customer Record
required: true
classification: public
quality:
- id: customer_id_no_nulls
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE customer_id IS NULL
mustBe: 0
description: customer_id cannot be NULL
dimension: completeness
- id: customer_email
name: customer_email
businessName: Customer Email Address
logicalType: string
physicalType: VARCHAR
description: Primary contact for billing (PII)
classification: restricted
quality:
- id: customer_email_no_nulls
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE customer_email IS NULL
mustBe: 0
description: customer_email cannot be NULL
dimension: completeness
- id: customer_email_format
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE customer_email IS NOT NULL AND customer_email !~* '^[a-zA-Z0-9.!#$%&''*+/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$'
mustBe: 0
description: customer_email must match RFC 5322 regex
dimension: conformity
- id: plan_name
name: plan_name
businessName: Subscription Plan Name
logicalType: string
physicalType: VARCHAR
description: Categorical - 'Basic', 'Premium', or 'Enterprise'
required: true
classification: public
quality:
- id: plan_name_no_nulls
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE plan_name IS NULL
mustBe: 0
description: plan_name cannot be NULL
dimension: completeness
- id: plan_name_valid_values
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE plan_name NOT IN ('Basic', 'Premium', 'Enterprise')
mustBe: 0
description: plan_name must be one of 'Basic', 'Premium', or 'Enterprise'
dimension: conformity
- id: monthly_revenue
name: monthly_revenue
businessName: Monthly Recurring Revenue
logicalType: number
physicalType: NUMERIC
description: The MRR value for the period
required: false
classification: public
quality:
- id: monthly_revenue_non_negative
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE monthly_revenue < 0
mustBe: 0
description: monthly_revenue must be >= 0
dimension: conformity
- id: is_active
name: is_active
businessName: Active Status Indicator
logicalType: boolean
physicalType: BOOLEAN
description: Indicates current product entitlement
classification: public
quality:
- id: is_active_not_null
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE is_active IS NULL
mustBe: 0
description: is_active cannot be NULL
dimension: completeness
- id: metadata
name: metadata
businessName: Subscription Metadata
logicalType: object
physicalType: JSONB
description: Semi-structured - Regional and referral tags
classification: public
- id: signup_date
name: signup_date
businessName: Initial Conversion Date
logicalType: date
physicalType: DATE
description: Date of initial conversion
required: true
classification: public
quality:
- id: signup_date_no_nulls
type: sql
query: |
SELECT COUNT(*) FROM customer_subscriptions WHERE signup_date IS NULL
mustBe: 0
description: signup_date cannot be NULL
dimension: completeness
- id: last_updated_at
name: last_updated_at
businessName: Last Update Timestamp
logicalType: timestamp
physicalType: TIMESTAMPTZ
description: System - Audit timestamp for freshness
classification: public
quality:
- id: data_freshness
type: text
description: Maximum data age of 60 minutes from current system time
slaProperties:
- id: frequency_60_min
property: frequency
value: 60
unit: m
description: Data is refreshed every 60 minutes
driver: operational
- id: latency_300_sec
property: latency
value: 300
unit: s
description: Available within 300 seconds of event timestamp
driver: analytics
- id: availability_999
property: availability
value: 99.9
unit: percent
description: 99.9% availability of the database endpoint
- id: support_24_7
property: timeToRepair
value: 4
unit: h
description: 24/7 Monitoring with 4-hour critical response
driver: operational
- id: eos_90_day_notice
property: endOfSupport
value: 90
unit: d
description: 90-day notice for breaking schema changes
price:
priceAmount: 5
priceCurrency: EUR
priceUnit: gigabyte
support:
- id: teams_channel
channel: Teams Channel
tool: teams
scope: interactive
description: Primary communication channel
- id: email_emergency
channel: Technical Emergency
tool: email
scope: issues
description: Technical emergency support via email
- id: status_page
channel: API Status Page
tool: other
scope: announcements
description: Regular updates on API and data status
roles: []Final notes
We repeated the whole process multiple times and got to following insights:
- The generation process is probabilistic so the prompt we gave it did not always have the same success.
The best thing to mitigate that is to write more details into a prompt. Two problems are worth mentioning. The first one is the generation of quality rules. In most cases, the LLM would use the SQL type of quality rules without us giving it the instruction because it would probably conclude we need that when we are working with PostgreSQL database. In other cases, we would get quality types we don’t need, so it was useful to add this guideline to the prompt.
The second problem was LLM using the other data contracts in the repository as examples, so it would add data from other contracts into this one. We resolved this problem by adding a guideline that it is forbidden to use resources other than those mentioned in the prompt. - Generation and validation prompts can be glued together, but the process works better, and it is cleaner when they are separated.
- Combining LLM-s with a linter is a good step forward in automating the data contract writing process.
Furthermore, if you add to it a good prompt and a well written documentation it is a certainty you would get syntactically correct data contract. You only need to check the values.
We believe this is just a first small step and a lot more can be done. Possible next steps:
- Make software that will use the schema store outside an IDE to perform this automatic validation, so it is more accessible to business users.
- Add automation process to unite this generation and validation process by performing the quality checks on data.
- Use a data catalog like Actian or Collibra to define the data products which will then be read by an LLM to populate a data contract. This approach moves away from loose textual format but it is a possible source of information which would maybe be a first choice for someone who has worked with it.
LLM-s have the power to work out ideas in detail based on even scarce inputs. Although they can do that, it would be wrong to leave to them to define the business requirements like SLA or data quality. This needs to come from a person who understands the business processes and needs and can see the value behind enforcing the data contract.
Conclusion
Our example shows that LLMs can significantly streamline data contract creation—when paired with the right safeguards. By combining careful prompting, ODCS documentation, and automated syntax validation through VS Code diagnostics, we transformed a tedious manual task into a reliable semi-automated workflow. But here’s what we’re really curious about:
What has your experience been like? Have you tried using AI to automate any part of your data governance or data quality processes? What challenges have you faced?
We’re always looking to learn from others walking the same path. If you’re tackling similar challenges or just getting started with data contracts, we’d love to hear from you. Whether you want to share your experiences, exchange ideas, or explore how we might work together on your data quality and governance needs, feel free to reach out.
After all, the best solutions often come from collaboration.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.



