To better experience Data lineage, we can observe it from the view of the visual representation of a directed graph. A Graph Database consists of nodes that represent different data elements, such as tables, transformations and reports, and edges that show relationships between nodes and describe the flow of data between them. This allows us to trace the origin of data and understand how it is manipulated and transformed over time.
Imagine this: You have an extensive business system with countless tables, and you need to identify where specific sensitive data is displayed across multiple processes and reports in the organization. However, you find yourself short on resources and time to perform a thorough system scan and search for the information you need. This is where the power of data lineage comes to the rescue.
Prerequisites for Data Lineage
To implement data lineage in a company, the elementary step is to identify the key elements: data sources, data transformation, BI tools and data consumers within the organization. This process helps us to understand how data is created, changed, and used across different departments and systems through pipelines.
After completing the previous action, the logical progression would be to choose a comprehensive Data Catalog that helps to maintain an organized inventory of data assets and a metadata management system to capture, store, and manage information about your data assets. The Data Catalog, which will be explained in detail later here, serves as a foundation for documenting and understanding data lineage within your organization.
Guide to Selecting the Perfect Data Catalog
To achieve effective data lineage, it is important to use data integration and transformation tools that support lineage tracking. However, there is no data catalog tool that supports all transformation tools. Therefore, it’s important to carefully evaluate and choose a data catalog tool that supports the specific transformation tools your organization uses and to consider factors such as integration capabilities, metadata management, access control, and, as discussed, lineage tracking capabilities.
However, if some transformation tools are not compatible with the chosen data lineage, so you can not automatically connect them to lineage, you can do it manually. For now, some data transformation tools, such as Apache NiFi, Talend, and StreamSets, provide built-in lineage tracking capabilities, enabling you to capture and visualize data lineage as part of the transformation process, while other tools, such as Apache Spark and Apache Beam, require additional configuration to enable lineage tracking. We believe that with today’s rapid development of technology, most data catalogs will have automated connections for the most used transformation tools.
To overcome this challenge, CROZ can conduct an assessment of your existing data and transformation tools to identify gaps in data lineage coverage and determine which Data Catalog is best suited for building a complete data lineage. With our assessment and selection of the right data catalog tool, your organization can establish a sturdy foundation for effective data lineage enabling you to share lineage information with relevant stakeholders while ensuring that sensitive data and lineage information are only accessible to authorized users.
In the next chapter, embark on an exciting exploration as we discover the fascinating world of the data lineage. You will discover two essential types, business and technical, that will empower and enrich you on this incredible journey.
Business Data Lineage
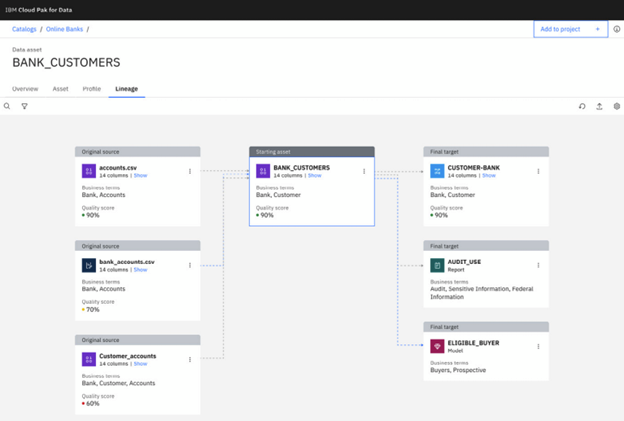
A data lineage of business provides a visual representation of the flow of data, based on their business glossary, through an organization’s systems and processes from their point of origin to their destination. By monitoring the flow of data, companies can locate sensitive information, determine access points, and implement effective security measures. So, when data lineage is combined with well-defined common vocabulary such as business terms and classifications, it offers organizations a powerful tool to identify, manage, and protect sensitive or any kind of classified data, by both technical and non-technical stakeholders with appropriate access. By assigning relevant business terms to data assets, organizations can easily locate and track the flow of sensitive information.
For example, customer data can be classified into categories such as ‘personally identifiable information (PII)’, ‘financial data’, and ‘contact details’, while business terms such as ‘customer name’, ’email address’, and ‘credit card number’ can then be assigned to these categories, simplifying the process of identifying and tracking sensitive data. Once terms and classifications are in place, organizations can leverage business data lineage to locate sensitive customer data across their systems. By tracing the flow of data elements tagged with specific business terms, companies can identify where sensitive information resides, and how it is processed and stored. This process also uncovers potential vulnerabilities or points of non-compliance, allowing businesses to take corrective action.
When it comes to creating robust business lineage, the IBM Watson Knowledge Catalog (WKC) offers a powerful tool for defining and managing data assets, and one of the standout features is its ability to create business lineage using business terms and classifications.
Technical Data Lineage
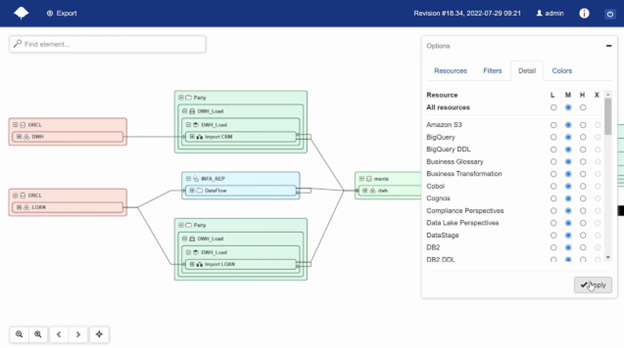
While businesses typically track their lineage through a glossary, in the technical realm, data lineage is a more prevalent method due to the frequent changes made to data systems to remain competitive and adaptive to new requirements. Data lineage is the process of tracking and understanding how data or a specific column, e.g., ‘credit card number’, moves through an organization’s data architecture, whether as a batch or a streaming process. It provides a clear understanding of the relationships between data sources, tables, columns, processes, and reports.
One of the important reasons why organizations need to have technical Data Lineage is to be able to assess the impact of changes on their infrastructure if they want to change the table structure on the source or some column that is further used in transformations and reports. By tracing the data flow, organizations can assess the extent of the changes that need to be implemented and determine which tables, processes, and reports will be affected by these modifications. Also, knowing the scope of the changes can help businesses allocate the necessary resources more efficiently, avoid wasting time and money on unnecessary modifications, and focus on the most critical aspects.
For organizations looking to achieve detailed and automated technical lineage, IBM Manta offers a robust solution. Manta’s technology focuses on providing comprehensive visibility into data flows and transformations across various systems and platforms. This capability is crucial for understanding the technical aspects of data movement and ensuring data integrity.
Conclusion
The importance of business and technical data lineage cannot be overstated in today’s data-driven world. Investing in a robust data lineage solution with CROZ will empower your organization to unlock the full potential of your data assets, ultimately enabling you to make better decisions, reduce risks, and remain competitive in an ever-evolving business landscape.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.