Blog
Why do you need Apache Airflow?

 10 minute read
10 minute read
03.09.2021
The need for workflow management tools
In today’s world, data analytics plays one the key roles in the decision-making process of various stages of business in almost every industry. Data is generated at an enormously brisk pace through different sources.
Considering the fast-moving pace at which data is generated nowadays, implementing use cases such as moving data from one place to another, automating your DevOps operation, or managing your machine learning pipelines can be challenging. When those complex systems evolve at such a fast pace, a workflow management system (WMS) like Apache Airflow saves the day. It ties everything together in a place where every piece of the puzzle can be orchestrated properly with APIs. When it comes to data schema, data inflow rates, processing needs, or the dynamic nature of data sources, it is crucial to use proper scheduling, managing, and monitoring of data pipelines for a stable and reliable data platform. If this is not enough for you and you still ask yourself: Why do I need Airflow when I can run a bunch of cron scripts? – we will provide you with some functions that Airflow offers you, but cron does not.
Airflow vs. Cron
With Airflow, you can:
- Automatically rerun your jobs after failure
- Add dependency checks (such as triggering one job after the completion of another)
- monitoring (viewing the status of tasks from the UI), alerting about DAG failures
With cron, you must write code for the above functionalities, while Airflow provides them.
Apache Airflow
Apache Airflow is an open-source WMS designed for authoring, scheduling, and monitoring workflows as DAGs (directed acyclic graphs). Workflows are written in Python, which allows flexible interaction with third-party APIs, databases, and data systems. Data pipelines in Airflow are built by defining a set of tasks to extract, transform, load, analyze or store the data.
Airflow is a workflow scheduler designed to help with scheduling complex workflows and provide them with an easy way to maintain them. It is a great product for data engineering if you use it with the purpose it was designed for – to orchestrate work executed on external systems such as Spark, Hadoop, Druid, cloud services, etc. For example, if your task is to load data in PostgreSQL, make some aggregations using Spark, and store the data on your Hadoop cluster (like in Figure 2.), then Airflow is the best choice since it can tie many external systems together. Airflow was not designed to execute any workflows directly inside but to schedule them and keep the execution within external systems.
UI Walkthrough
The Airflow UI makes it easy to monitor and troubleshoot your data pipelines. We will quickly introduce you to some of the features and visualizations you can find in the Airflow UI.
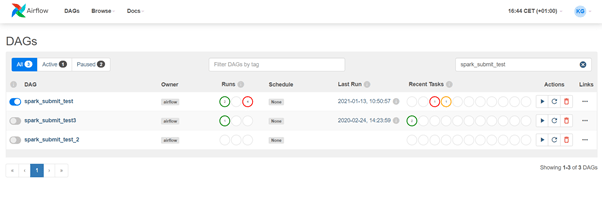
Figure 1. Ariflow's UI
Figure 1 shows DAGs View (a list of DAGs in our environment), where we can see exactly how many tasks succeeded, failed, or are currently running at a glance.
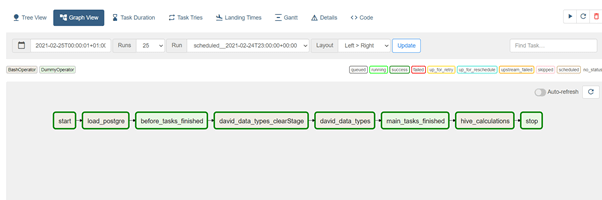
Figure 2. Sample DAG Graph View
Figure 2 depicts DAG Graph View, which is perhaps the most comprehensive. In Graph View we can visualize DAG’s dependencies and their current status for a specific run.
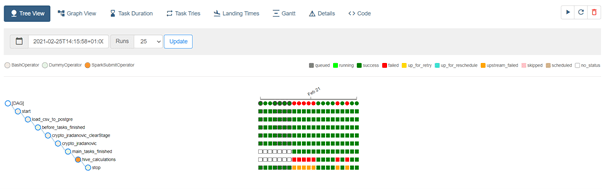
Figure 3. Sample DAG Tree View
Figure 3 shows a tree representation of the DAG that spans across time. If a pipeline is late, we can quickly see where the different steps are and identify the blocking ones.
Moreover, Airflow’s UI offers other cool features like the Gantt Chart, which analyzes the task duration. Also, you can quickly identify bottlenecks and where the majority of the time is spent for specific DAG runs. Task Duration view lets you find outliers and quickly understand where the time is spent in your DAG over many runs and Airflow’s Code View allows you to see the code that generates the DAG and provide yet more context.
DAG in Airflow
Now, the question you might be asking yourself is – What is a DAG in Airflow?
A DAG is a collection of all the tasks you want to run, organized in a way that reflects their relationships and dependencies. Each node in a DAG represents a task that needs to be run. A user will mention the frequency at which a particular DAG needs to be run, and also user can specify the trigger rule for each task in a DAG (for example, you want to trigger the alert task right after one of the previous tasks fails).
At a high level, we can think of DAG as a container that holds tasks and their dependencies and sets the context for how and when these tasks should run.
Airflow’s key components
Let’s quickly introduce you to the main components of Airflow and explain how to set up Airflow architecture for production.
The main components of Airflow are:
- A Metadata Database
- A Scheduler
- An Executor
- A Webserver
Airflow is using a relational database to store configuration and information (state of tasks, state of workflows, task runs, etc.) of all the DAGs.
The scheduler is responsible for scheduling your tasks according to the frequency mentioned. As a user, your interaction with the scheduler is limited since you will only provide it with information about tasks and when they must run. The scheduler uses the DAGs definitions with task states in the metadata database to decide which tasks to execute and in which order. Also, if a DAG failed and you enabled retry, the scheduler will automatically put that DAG up for retry.
When DAGs tasks and scheduling definitions are in place, the executor comes into play. The executor is responsible for running a task. It is a message queuing process that decides which worker will execute each task, how many tasks will be run in parallel, etc. The tasks are pulled from a queue (for example, RabbitMQ). The executor is tightly connected to the Scheduler and determines the worker processes that execute each scheduled task. You can run your task on multiple workers that are managed by Celery or Kubernetes, for example. Executing Airflow DAGs on Kubernetes is a popular approach lately because it’s so easy to scale workers automatically.
Finally, the webserver is serving as the frontend for Airflow. In the webserver, users can enable or disable DAGs, retry DAGs, and also see logs for a DAG – all that from the Airflow’s beautiful UI. If you like analyzing things, you can see which tasks have failed, how long did each task run for, what caused the failure of a task, when was a task last retried, and many other features.
Overall Airflow architecture with components mentioned above is illustrated in the Figure 4.
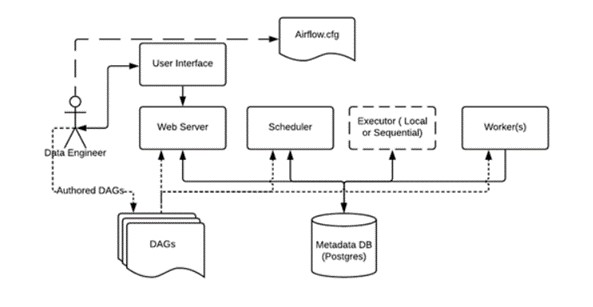
Figure 4. Airflow architecture
Comparison with Oozie and Luigi
Apache Oozie is an open-source workflow scheduling system written in Java for managing and executing Hadoop jobs in a distributed environment. Oozie is designed to work within the Hadoop ecosystem, therefore it’s not as flexible as Airflow. Oozie workflow is a collection of actions (Map-Reduce job, Hive job, custom Java applications, etc.) arranged in a control dependency DAG, specifying a sequence of actions execution. The DAG is specified in hPDL (an XML Process Definition Language).
Luigi is a Python package for building complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more. The purpose of Luigi is to address all the plumbing typically associated with long-running batch processes. You want to chain many tasks and automate them. In Luigi, you can specify workflows as tasks and dependencies between them.
Let’s compare Airflow, Oozie, and Luigi, considering the features we think are the most important when choosing a WMS.
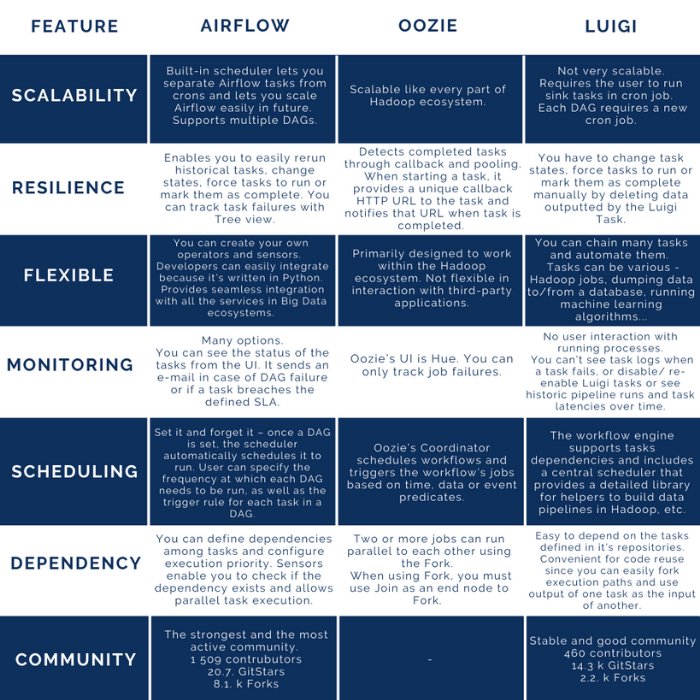
To sum up, we at CROZ moved from Oozie to Airflow years ago and we are enjoying its flexibility. Transition to new tools can be demanding so if you have any doubts or struggles, we at CROZ will be delighted to help you with implementation or migration to Airflow.
Photo by Rabih Shasha on Unsplash.