General
So far in this blog series we presented some of the reasons why we decided to use Apicurio schema registry in one of our recent projects. We continue the series with the topic of serde libraries comparison between Apicurio’s and Confluent’s libraries.
The Apache Kafka provides a Serde interface, which is a wrapper for serializer and deserializer of a data type. Kafka provides an implementation for several common data types, and Avro type is not among them. Because of that, we had to use some Serde library that provides implementation for Avro type, for example Apicurio or Confluent Serdes.
Throughout our project we have used both mentioned Serde libraries, them being Apicurio and Confluent Serdes libraries. We started our project using Apicurio Serde because we were trying to stick to only one schema registry ecosystem, but as the project progressed, we started to realize that Apicurio might not have been the optimal choice because of its immaturity in some aspects. Then we decided to make a switch to Confluent Serdes library. Apicurio schema registry has Confluent compatible API and that did us a favor when switching to Confluent Serdes because we could keep Apicurio schema registry while not using its Serde library. Because of that, we were ready to switch to Confluent schema registry any time if necessary.
The serializers and deserializers from both platforms provide support for multiple schema technologies. There is available support for Protobuf and JSON schemas, along with Avro schemas.
In Confluent the serializers and deserializers are available in multiple languages, including Java, .NET and Python, while Apicurio Serde is only available in Java.
Compatibility
To provide compatibility with Confluent Serdes (and other clients), Apicurio Registry implements the API defined by the Confluent Schema Registry. This is only provided for compatibility purposes, and when using Apicurio Registry, the core Registry API should be used instead. Although compatible API exists, it is not fully functional yet. Unfortunately, it lacks support for schemas with references registered in Apicurio Registry. So, when using Apicurio Registry in combination with Confluent Serde library, it is necessary to avoid using references in Avro schemas in order for things to work. The compatible API has endpoint /apis/ccompat/v6, for example if localhost is used, its configuration might look like something like this
kafka.schema.registry.url: http://localhost:8080/apis/ccompat/v6
Using the combination of Apicurio Registry and Confluent Serdes, it is possible to get the schema string identified by the input ID, but not to retrieve only the schema identified by the input ID. It is also not possible to get, update and delete the mode for specific subject through this API. Compatibility-wise, it is not possible to perform a compatibility check on the schema against one or more versions in the subject like it is using Confluent Schema Registry. Speaking of compatibility resource, provided API has every functionality like Confluent’s API except the deletion of the specified subject-level compatibility level config that reverts compatibility level to the global default.
Confluent Schema Registry does not provide compatible APIs towards other Serde libraries because it is considered to be de facto schema registry standard.
Schema Retrieval
The Kafka serializers and deserializers use lookup strategies to determine the artifact ID and global ID under which the message schema is registered in registry in order to retrieve the schema. Both Serde libraries share the similar implementations of these strategies. The default strategy in both Serde libraries is TopicIdStrategy or TopicNameStrategy in Apicurio and Confluent respectively. These strategies use topic name in combination with key or value suffix. Another strategy uses the full name of the schema to find the given schema in registry, that strategy is called QualifiedRecordIdStrategy (Apicurio) or RecordNameStrategy (Confluent). There is also a similar strategy to QualifiedRecordIdStrategy in Apicurio called RecordIdStrategy that uses schema namespace, which is optional, and schema name. Their downside is that they do not guarantee the uniqueness of subject per topic. Another shared strategy across libraries is TopicRecordIdStrategy (Apicurio) or TopicRecordNameStrategy (Confluent). It uses the topic name and the full name of the schema. In Apicurio there is also the fourth option, SimpleTopicIdStrategy that only uses the topic name.

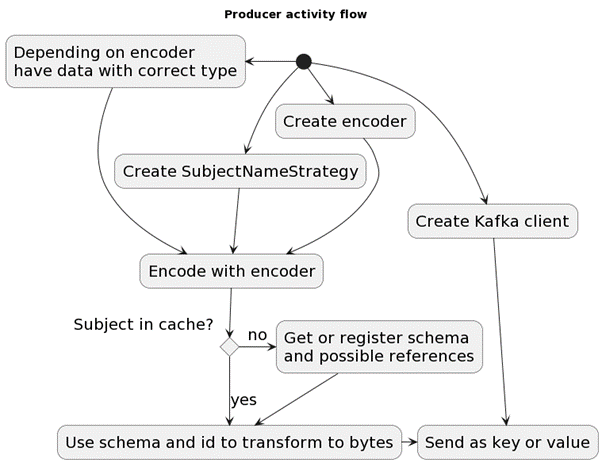
1 – Producer activity flow in Confluent
Configuration
It is possible to configure specific client serializer and deserializer services and schema lookout strategies directly in a client application. Configuration can be done in lots of ways. We will explain the Apicurio and Confluent configurations that we used in our project.
When configuring serializers and deserializers, it is mandatory to specify schema registry URL in both platforms. In our project we didn’t want to auto-register schemas to avoid later problems that it would cause. If we had used it, we could have ended up with multiple projects that expect different schemas under the same name because they all have registered different schemas under the same name. We wanted more strict and stable structure of the messages and schemas to avoid this problem. Because we have used Avro format as a message format, we had to specify that in configuration. Schema retrieval strategy that we used was previously mentioned QualifiedRecordIdStrategy/RecordNameStrategy. In Apicurio there was no need for that configuration in deserializer because the schema global ID that the deserializer uses is sent in the message payload, and the deserializer extracts the global ID from it and uses it to look up the schema in the registry. Another Apicurio-specific configuration was about the location of global ID in the messages. By disabling headers, we managed to send global ID in the message payload rather than headers. In Confluent there was no need for that because it does not support headers for that purpose. We have configured the Confluent Serdes to use the reflection API when serializing/deserializing.
Apicurio serializer configuration:
private <T> AvroKafkaSerializer<T> configureSerializer() {
AvroKafkaSerializer<T> serializer = new AvroKafkaSerializer<>();
Map<String, Object> config = new HashMap<>();
config.put(SerdeConfig.REGISTRY_URL, schemaRegistryUrl);
config.put(SerdeConfig.AUTO_REGISTER_ARTIFACT, false);
config.put(SerdeConfig.ARTIFACT_RESOLVER_STRATEGY, QualifiedRecordIdStrategy.class);
config.put(SerdeConfig.ENABLE_HEADERS, false);
config.put(AvroKafkaSerdeConfig.USE_SPECIFIC_AVRO_READER, true);
serializer.configure(config, false);
return serializer;
}
Apicurio deserializer configuration:
private <T> AvroKafkaDeserializer<T> configureDeserializer() {
AvroKafkaDeserializer<T> deserializer = new AvroKafkaDeserializer<>();
Map<String, Object> config = new HashMap<>();
config.put(SerdeConfig.REGISTRY_URL, schemaRegistryUrl);
config.put(SerdeConfig.AUTO_REGISTER_ARTIFACT, false);
config.put(SerdeConfig.ENABLE_HEADERS, false);
config.put(AvroKafkaSerdeConfig.USE_SPECIFIC_AVRO_READER, true);
deserializer.configure(config, false);
return deserializer;
}
Confluent Serdes configuration:
private Map<String, Object> configureKafka(String schemaRegistryUrl) {
Map<String, Object> props = new HashMap<>();
props.put(KafkaAvroDeserializerConfig.AUTO_REGISTER_SCHEMAS, false);
props.put(KafkaAvroDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG, schemaRegistryUrl);
props.put(KafkaAvroDeserializerConfig.KEY_SUBJECT_NAME_STRATEGY, RecordNameStrategy.class);
props.put(KafkaAvroDeserializerConfig.VALUE_SUBJECT_NAME_STRATEGY, RecordNameStrategy.class);
props.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
props.put(KafkaAvroDeserializerConfig.SCHEMA_REFLECTION_CONFIG, true);
return props;
}
Testing
When unit testing using Apicurio Serde there is a need to write mock methods for serialization and deserialization ourselves because they do not exist as a part of any Apicurio library. How exactly this can be done will be mentioned in future blogs. On the other hand, Confluent Schema Registry provides a way to mock its serialization and deserialization methods and that makes mocking of it fairly easy to do. The ways to mock those methods are the biggest difference in testing between Apicurio and Confluent Serdes libraries.
Next Blog
After the comparison of Serde libraries, in the next blog post we will talk more about some of the challenges we faced while using Apicurio such as schema registration, performance testing and more.
Schema registry blog series (3 of 6):
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.