

Unit Testing
The unit testing of applications that use the Apicurio schema registry is possible. We will explain how it works through a straightforward example written in Groovy using a testing and specification framework called Spock. In this example, we will be testing the Kafka Streams processor application.
First, we need a component that is used for testing topologies. Kafka’s TopologyTestDriver is the class we are going to use – https://kafka.apache.org/31/javadoc/org/apache/kafka/streams/TopologyTestDriver.html. This class makes it easier to write tests to verify the behavior of topologies created with Topology or StreamsBuilder. It is used both for testing simple topologies that have a single processor and for testing very complex topologies that have multiple sources, processors, sinks, or sub-topologies.
Best of all, it works without a real Kafka broker, so the tests execute quickly with little overhead. Although the driver doesn’t use a real Kafka broker, it does simulate Kafka consumers and producers that read and write raw byte[] messages.
Its constructor’s arguments are topology and properties from Kafka stream configuration. After its usage, it is necessary to close the driver, its topology, and all processors.
TopologyTestDriver testDriver =
new TopologyTestDriver(topology, properties)
…
testDriver.close()
The next components we need are TestInputTopic and TestOutputTopic. TestInputTopic is used to pipe records to the topic in TopologyTestDriver and TestOutputTopic is used to read records from a topic in TopologyTestDriver. We can let TestInputTopic and TestOutputTopic handle conversion from regular Java objects to raw bytes. To use TestInputTopic we need to create a new instance something like this:
TestInputTopic<String, SpecificRecords> inputTopic =
testDriver.createInputTopic(topicSource, keySerializer, valueSerializer)
We need to pass the source topic name, key serializer, and value serializer to its constructor. After that, in actual test code, we can pipe new record values, keys and values or list of KeyValue pairs. If we have multiple source topics, then we need to create a TestInputTopic for each. To pipe new records, we use TestInputTopic’s function pipeInput()
InputTopic.pipeInput(key, value)
On the other hand, we can create a new instance of TestOutputTopic like:
TestInputTopic<String, SpecificRecords> outputTopic =
testDriver.createInputTopic(topicSource, keySerializer, valueSerializer)
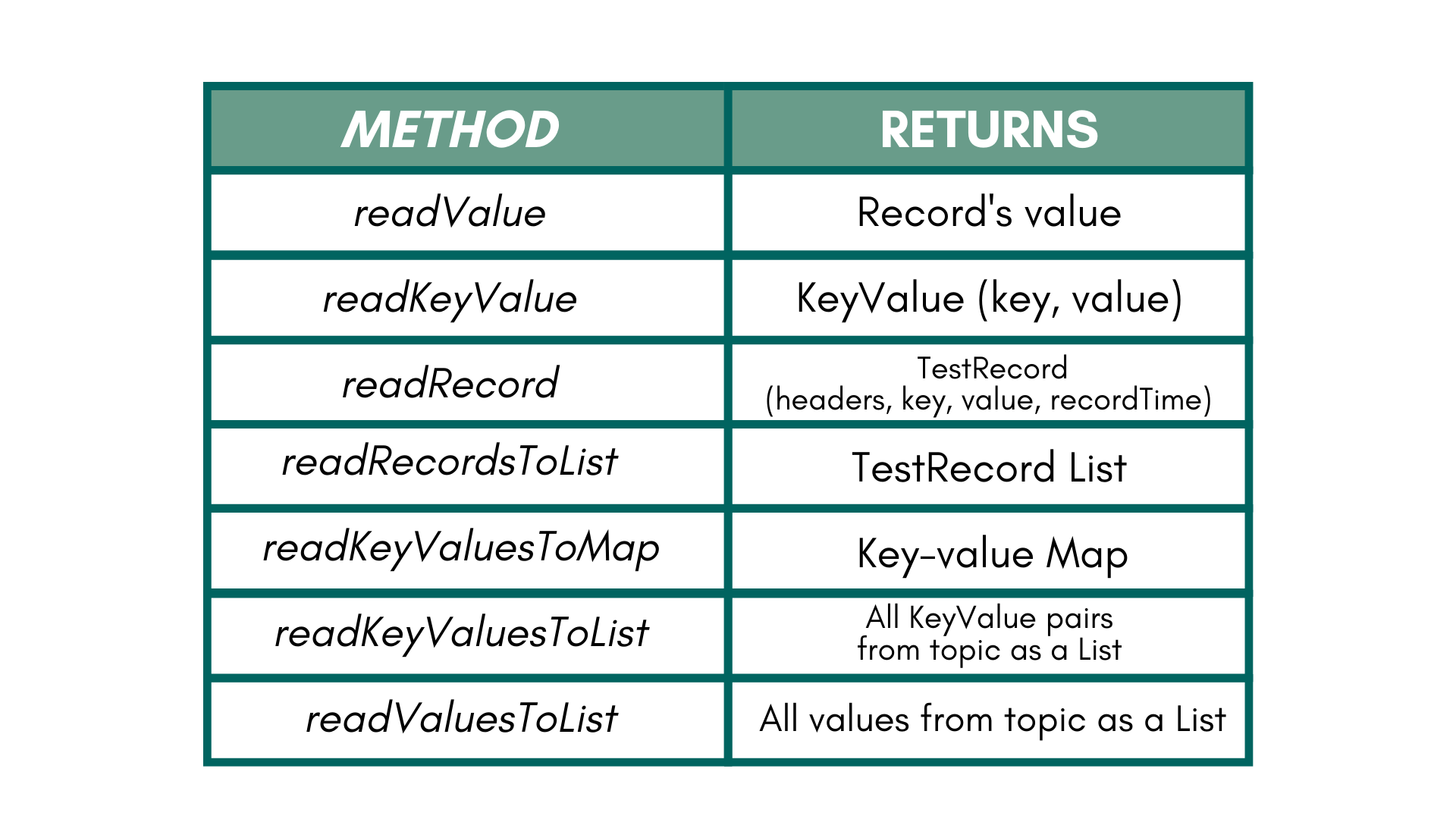
And after that, we can read record values, keys, keyValue, or TestRecord. If we have multiple source topics, we need to create a TestOutputTopic for each one. Its available methods are readRecord() for reading key, value, headers, and timestamp, readKeyValue() for KeyValue pair, but this way we don’t get access to the record’s timestamp or headers, and similarly using readValue() we can get only the value of a record. There are also a few other available methods listed in the table below.
Because there is no way to mock AvroKafkaSerializer and AvroKafkaDeserializer using Apicurio, we need to use a workaround to solve this problem.
First, we are going to need some sort of local cache to store incoming events. For this purpose, we will use the Map object with the key of type Bytes and the value of type SpecificRecord. In the serialize() method we transform incoming events to bytes and use them as a key in the map, and we store the event as its value. That way, later, we can in the deserialize() method fetch the event held as a value because that method gets the event in the form of bytes as an argument, and we are going to use those bytes to fetch the event from the map.
Map<Bytes, SpecificRecord> eventSerDeCache = new LinkedHashMap<>()
We must override methods serialize() and deserialize() from mentioned classes by ourselves.
@Override
byte[] serialize(String topic, Headers headers, SpecificRecord data) {
DatumWriter writer = new GenericDatumWriter(data.getSchema())
ByteArrayOutputStream out = new ByteArrayOutputStream()
BinaryEncoder encoder = EncoderFactory.get().directBinaryEncoder(out, null)
writer.write(data, encoder)
byte[] byteArr = out.toByteArray()
Bytes bytes = Bytes.wrap(byteArr)
eventSerDeCache.put(bytes, data)
return byteArr
}
@Override
SpecificRecord deserialize(String topic, Headers headers, byte[] data) {
return eventSerDeCache.deserialize(Bytes.wrap(data))
}
These are components necessary for basic unit testing of our Kafka processors. Additionally, internal state stores are also probably needed, depending on your processor. You can get one by fetching it from the test driver by its name.
store = testDriver.getKeyValueStore(“store”)
Next Blog
The basics for Apicurio unit testing were presented and clarified in this blog, and you should now be ready to write unit tests for your processor. The following blog will be the last one in the series and will be on Apicurio Registry Operator and schema management.
Schema registry blog series (5 of 6):


