Ein technischer Deep Dive zu KubeVirt, Architektur und Automatisierung
Im ersten Teil dieser Artikelserie hat Mate die betriebswirtschaftliche Perspektive eines Wechsels von VMware zu OpenShift Virtualization beleuchtet – und erläutert, warum sich Unternehmen zunehmend für Plattformen auf Basis von Open-Source-Prinzipien interessieren.
Dieser zweite Teil richtet den Fokus auf die technische Ebene. Wenn Sie Begriffe wie KubeVirt, CRDs, GitOps oder MTV gehört haben und sich gefragt haben, wie diese zusammenhängen, sind Sie hier richtig.
Wir erklären, wie OpenShift Virtualization technisch funktioniert, auf welchen Komponenten es aufbaut, wie es sich mit bekannten VMware-Konzepten vergleichen lässt – und warum die größten Herausforderungen in der Praxis häufig nicht technischer, sondern organisatorischer Natur sind.
Open Source als Fundament
Red Hats Open-Source-Strategie
Ein zentraler Bestandteil der Produktstrategie von Red Hat ist das sogenannte Upstream-First-Prinzip. Jedes Produkt basiert auf einem vollständig offenen Upstream-Projekt, in dem Innovation transparent entwickelt wird, bevor sie für den Enterprise-Einsatz gehärtet und supportet wird.
- Red Hat Enterprise Linux basiert auf Fedora
- OpenShift basiert auf OKD
- OpenShift Virtualization basiert auf KubeVirt
Dieses Modell sorgt für Transparenz, reduziert das Risiko eines Vendor Lock-ins und ermöglicht es Unternehmen, Innovationen planbar zu adaptieren. Zudem kann der Zugriff auf den Quellcode bei der Analyse ungewöhnlicher Fehlerbilder äußerst hilfreich sein – insbesondere bei komplexen Systemverhalten.
KubeVirt: Die Grundlage von OpenShift Virtualization
KubeVirt ist das Open-Source-Projekt, das es OpenShift ermöglicht, virtuelle Maschinen nativ neben Containern zu betreiben. Anstatt eine eigenständige Hypervisor-Plattform darzustellen, wird KubeVirt als Operator bereitgestellt, der in einem bestehenden OpenShift-Cluster installiert werden kann.
Aus Deployment-Sicht ist das ein entscheidender Unterschied. OpenShift Virtualization benötigt keinen separaten Infrastruktur-Stack. Stattdessen erweitert es eine Standard-OpenShift-Installation um Virtualisierungsfunktionen. Die wichtigste Voraussetzung ist, dass der Cluster Bare-Metal-Worker-Nodes im Node-Pool enthält. Diese Nodes stellen den Zugriff auf KVM bereit, der für den performanten Betrieb virtueller Maschinen erforderlich ist.
Im Kern verwendet KubeVirt QEMU/KVM als zugrunde liegende Virtualisierungs-Runtime. QEMU übernimmt die Emulation von Hardware-Geräten, während KVM durch Nutzung von CPU-Virtualisierungserweiterungen eine nahezu native Performance ermöglicht. Diese Kombination ist im Linux-Ökosystem etabliert und weit verbreitet. Red Hat verfügt über langjährige und umfassende Erfahrung mit KVM und hat zuvor Enterprise-Virtualisierungsplattformen auf Basis von Red Hat Virtualization (RHV) entwickelt und betrieben. Obwohl RHV inzwischen eingestellt wurde, haben Technologie und Betriebserfahrung dieses Produkts die Weiterentwicklung von OpenShift Virtualization maßgeblich geprägt.
Das Besondere an KubeVirt ist die Art und Weise, wie die Virtualisierungsschicht in Kubernetes integriert wird. Jede virtuelle Maschine läuft innerhalb eines Pods – häufig als sogenannter virt-launcher-Pod bezeichnet. In diesem Pod wird der QEMU-Prozess ausgeführt, während Kubernetes weiterhin für Scheduling, Lifecycle-Management, Health Checks und die Ressourcensteuerung verantwortlich bleibt.
Architekturüberblick: OpenShift Virtualization
Sobald KubeVirt als Operator installiert und QEMU/KVM in den Cluster integriert ist, wird OpenShift Virtualization zu einer natürlichen Erweiterung der OpenShift-Control-Plane. Virtuelle Maschinen werden nicht mehr über einen eigenständigen Hypervisor-Stack verwaltet, sondern über Kubernetes- und OpenShift-Primitiven geplant, betrieben und überwacht.
Genau dieser architektonische Ansatz unterscheidet OpenShift Virtualization grundlegend von klassischen Virtualisierungsplattformen – und ist zugleich Quelle seiner Leistungsfähigkeit wie auch seiner Lernkurve.
Wie OpenShift Virtualization virtuelle Maschinen ausführt
Architektonisch betrachtet ersetzt OpenShift Virtualization Kubernetes nicht – es baut konsequent darauf auf.
Die Fähigkeit, virtuelle Maschinen zu betreiben, entsteht dadurch, dass Virtualisierungsfunktionen als zusätzliche Schicht auf Kubernetes-Primitiven aufgesetzt werden. Zentrale Komponenten sind:
- HyperConverged (HC) CRD
Die zentrale Ressource zur Aktivierung der Virtualisierung in OpenShift. Im HyperConverged-Objekt wird die globale Cluster-Konfiguration definiert, beispielsweise CPU-Overcommitment, Konfiguration von Live-Migration, Default-StorageClasses für temporäre Zustände (z. B. vTPM) - VirtualMachine (VM) CRD:
Declarative definitions of VM configuration - VirtualMachineInstance (VMI) CRD:
Repräsentiert die laufende Instanz einer virtuellen Maschine. - virt-handler:
Ein Daemon auf jedem Node, der für Lifecycle-Operationen von VMs zuständig ist, etwa Start, Stop oder Health Checks. - CDI (Containerized Data Importer):
Verantwortlich für das Importieren, Hochladen und Klonen von VM-Images. - AAQ (Application Aware Quota)
Ein spezialisierter Quota-Validator für VM-spezifische Workloads (Details folgen in einem späteren Abschnitt). - virt-launcher:
Ein Pod, in dem eine QEMU/KVM-Instanz ausgeführt wird. Jede virtuelle Maschine erhält ihren eigenen Pod.
In OpenShift ist eine VM somit technisch betrachtet ein Pod mit einer zusätzlichen Virtualisierungsschicht – kein eigenständiges, separates Konstrukt. Das ermöglicht einheitliches Scheduling, konsistentes Monitoring sowie eine durchgängige Automatisierung auf Basis der Kubernetes-Mechanismen.
Einordnung von OpenShift Virtualization im Vergleich zu VMware-Konzepten
Auch wenn ein direkter 1:1-Vergleich fachlich nicht vollständig korrekt ist (darauf gehen wir in Abschnitt 5 noch ein), hilft es, OpenShift-Konzepte mit Begriffen zu verknüpfen, die VMware-Administratoren bereits kennen.
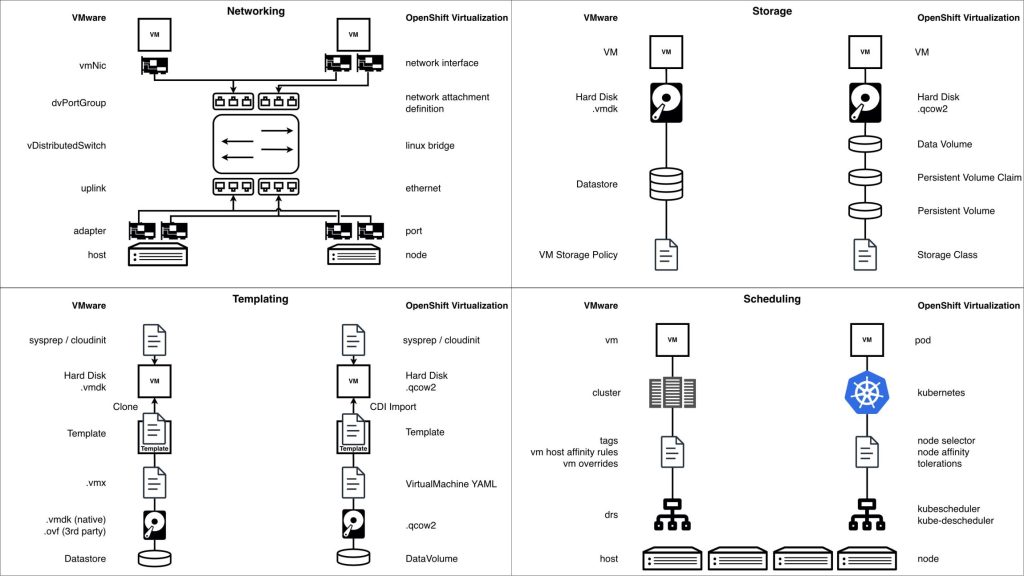
Networking in OpenShift Virtualization
Das Networking in OpenShift Virtualization folgt Kubernetes-nativen Prinzipien und unterstützt gleichzeitig klassische Anforderungen virtueller Maschinen. Dieses hybride Modell ist leistungsfähig, bringt jedoch wesentliche Unterschiede gegenüber traditionellem, hypervisor-basiertem Networking mit sich – Unterschiede, die Infrastruktur-Teams frühzeitig verstehen sollten.
Jede virtuelle Maschine ist standardmäßig mit dem Pod Network verbunden. Dieses wird vom primären CNI-Plugin des Clusters bereitgestellt – in der Regel OVNKubernetes – und bildet die Grundlage der VM-Konnektivität. Das Pod Network ermöglicht native Kommunikation zwischen virtuellen Maschinen und Container-Workloads, Integration von VMs in Kubernetes-Services wie DNS und Routing, konsistente Nutzung von Plattformfunktionen wie Load Balancing und Service-Exposition. Im Gastbetriebssystem der VM erscheint das Pod Network als normale Netzwerkschnittstelle. Auf Plattformebene stellt es jedoch sicher, dass die VM vollständig in das Kubernetes-Netzwerkmodell integriert ist.
Neben dem Pod Network unterstützt OpenShift Virtualization über Multus zusätzliche Netzwerke. Damit können VMs mehrere Netzwerkschnittstellen erhalten. Diese zusätzlichen Interfaces werden über sogenannte NetworkAttachmentDefinitions (NADs) definiert und kommen typischerweise zum Einsatz für VLAN-basierte Netzwerke, Traffic-Separation, Integration externer Systeme. Jedes sekundäre Netzwerk wird der VM als Standard-NIC bereitgestellt. Dadurch bleibt die Kompatibilität mit klassischen VM-Netzwerkkonzepten erhalten – bei gleichzeitig deklarativer Verwaltung über Kubernetes-Ressourcen.
Für anspruchsvollere Szenarien wird häufig der NMState Operator eingesetzt. NMState ermöglicht eine deklarative Netzwerkkonfiguration auf Node-Ebene, darunter Interface-Bonding, VLAN-Konfiguration, konsistente Interface-Zuordnung über mehrere Worker-Nodes hinweg. Dies ist insbesondere bei Multus-basierten Netzwerken relevant, da so ein vorhersehbares und einheitliches Netzwerkverhalten auf allen Nodes sichergestellt wird, die virtuelle Maschinen ausführen.
Die Netzwerksicherheit orientiert sich am Kubernetes-Durchsetzungsmodell. Aktuell gelten Kubernetes NetworkPolicies nur für die Pod-Network-Schnittstelle einer VM, da die Policy-Durchsetzung über OVNKubernetes erfolgt. Sekundäre Interfaces, die über Multus angebunden sind, unterliegen derzeit keiner NetworkPolicy-Durchsetzung. Die Segmentierung dieser Interfaces muss daher über folgende Mechanismen erfolgen: VLAN-Isolation, externe Firewalls, architektonische Netzdesign-Maßnahmen. Diese Einschränkung ist bekannt und Gegenstand aktiver Weiterentwicklung. Künftige Erweiterungen sollen die Policy-Durchsetzung auch auf zusätzliche VM-Netzwerkschnittstellen ausdehnen.
Storage in OpenShift Virtualization
Storage ist häufig der größte Unsicherheitsfaktor, wenn Unternehmen OpenShift Virtualization erstmals bewerten. Während sich Compute- und Networking-Konzepte vergleichsweise gut aus klassischen Hypervisor-Umgebungen übertragen lassen, folgt Storage einem anderen Betriebsmodell, das insbesondere in gewachsenen Enterprise-Umgebungen sorgfältig analysiert werden muss.
In OpenShift Virtualization basieren VM-Festplatten auf Kubernetes Persistent Volumes (PVs). Diese werden dynamisch über StorageClasses bereitgestellt und über einen Container Storage Interface (CSI)-Treiber angebunden. Diese Abstraktion ermöglicht die Integration unterschiedlichster Storage-Backends. Gleichzeitig entsteht jedoch eine zentrale Voraussetzung: Die eingesetzte Storage-Plattform muss über einen vollständig kompatiblen und stabil getesteten CSI-Treiber verfügen.
Nicht alle CSI-Treiber bieten denselben Funktionsumfang. Bei der Bewertung von Storage für OpenShift Virtualization sollten insbesondere folgende Funktionen geprüft werden:
- Block- und Filesystem-Volume-Modi
- Volume-Expansion
- Snapshot- und Clone-Funktionen
- Performance- und Latenzverhalten
- Unterstützung von Live-Migration
- Disk-Verschlüsselung
- Disaster-Recovery-Replikation
- Backup-Fähigkeiten
Ein konzeptionell bedeutender Unterschied zu VMware liegt in der Backend-Zuordnung des Storage.
In VMware entspricht ein Datastore typischerweise einer einzelnen LUN, in der mehrere virtuelle Maschinen und deren Festplatten angelegt werden. In OpenShift wird in der Regel jedes Persistent Volume einer eigenen LUN im Backend-Storage zugeordnet.
Das hat mehrere Implikationen:
- Eine VM mit zwei Festplatten verbraucht üblicherweise zwei separate LUNs
- Große VM-Landschaften können zu einer hohen Anzahl von LUNs im Backend führen
- Storage-Teams müssen LUN-Limits, Provisionierungsmodelle und betriebliche Prozesse entsprechend berücksichtigen
Diese Architektur stellt keine funktionale Einschränkung dar, erfordert jedoch ein bewusstes Storage-Design und entsprechende Planung. Manche Storage-Plattformen können sehr große LUN-Anzahlen effizient verwalten, andere benötigen Anpassungen oder architektonische Optimierungen.
Das Ökosystem der Werkzeuge und Automatisierungsmöglichkeiten
OpenShift Virtualization steht nicht isoliert für sich. Einer der größten Vorteile besteht darin, dass virtuelle Maschinen unmittelbar vom umfassenden OpenShift-Ökosystem profitieren, das konsequent auf Automatisierung, deklarative Konfiguration und API-getriebene Betriebsmodelle ausgerichtet ist. OpenShift selbst ist als operator-basierte Plattform konzipiert. Neue Funktionen werden durch die Bereitstellung von Operatoren ergänzt, die Anwendungslogik, Lifecycle-Management und Upgrades kapseln. OpenShift Virtualization folgt exakt diesem Modell und integriert sich nahtlos mit weiteren Operatoren – etwa für Storage, Networking, Security, Observability oder Automatisierung. Dadurch lässt sich ein Cluster schrittweise erweitern: Es werden nur die Funktionen aktiviert, die tatsächlich benötigt werden. Das ermöglicht ein modular aufgebautes, bedarfsgerechtes Plattformdesign.
Gleichzeitig bringt diese Flexibilität eine wichtige betriebliche Konsequenz mit sich. Jeder zusätzliche Operator ist eine weitere Komponente, die verwaltet werden muss – mit eigenem Lifecycle, Ressourcenverbrauch, Upgrade-Pfad und potenziellen Fehlerbildern.
Operatoren vereinfachen Installation und Wartung im Vergleich zu klassischen manuellen Ansätzen erheblich. Dennoch erfordern sie technisches Verständnis, klare Zuständigkeiten und eine bewusste Betriebsverantwortung.
Migration Toolkit for Virtualization (MTV) und Containers (MTC)
Das Migration Toolkit for Virtualization (MTV) ist der zentrale und empfohlene Mechanismus zur Migration virtueller Maschinen nach OpenShift Virtualization. Es wurde speziell dafür entwickelt, VMs aus VMware-Umgebungen und anderen unterstützten Virtualisierungsplattformen kontrolliert, reproduzierbar und skalierbar zu migrieren. Ziel ist es, manuellen Aufwand zu minimieren und Risiken während der Migration zu reduzieren.
MTV deckt den gesamten Migrationslebenszyklus ab. Dazu gehören die Analyse der Quellumgebung, die Inventarisierung der VMs, das Mapping von Netzwerk und Storage, die Konvertierung von Festplatten, das Entfernen der VMware-Guest-Tools, die Installation der KVM-Guest-Tools sowie die Erstellung der virtuellen Maschinen auf der OpenShift-Seite. Durch die direkte Integration in die OpenShift-APIs fügt sich MTV nahtlos in automatisierte und deklarative Workflows ein, anstatt auf einmalige, manuelle Schritte zu setzen.
Abhängig von der Anzahl der zu migrierenden virtuellen Maschinen und den Performance-Eigenschaften der Umgebung kann MTV so konfiguriert werden, dass für den Migration-Traffic ein dediziertes Netzwerk verwendet wird. Dadurch lassen sich Migrations-Workloads vom produktiven Traffic isolieren und die Performance bei groß angelegten Migrationen besser planbar gestalten. Wichtig ist dabei, dass dieses dedizierte Migrationsnetzwerk idealerweise bereits bei der Cluster-Erstellung berücksichtigt und konfiguriert wird, da es grundlegende Netzwerkdesign-Entscheidungen voraussetzt.
MTV unterstützt das Konzept sogenannter Migration Waves. Dabei handelt es sich um iterative Sammelmigrationen mehrerer virtueller Maschinen, die anhand fachlicher, anwendungsbezogener oder technischer Kriterien zu Gruppen zusammengefasst werden.
Waves ermöglichen es Organisationen,
- Migrationsprozesse schrittweise zu validieren,
- interne Skripte und Prozesse gezielt auf die neue Zielumgebung vorzubereiten,
- Risiken zu reduzieren, indem bewusst gesteuert wird, welche Workloads zu welchem Zeitpunkt migriert werden,
- Cutover-Phasen strukturiert zu planen und durchzuführen,
- sowie die Migrationsstrategie zwischen einzelnen Iterationen anzupassen oder bei Bedarf zurückzurollen.
In großen Enterprise-Umgebungen lassen sich diese Migration Waves in der Regel deutlich einfacher koordinieren, wenn sie in die Ansible Automation Platform integriert werden. Ansible kann dabei Vorabprüfungen vor der Migration, die Aufbereitung und Pflege von Inventardaten, Validierungen nach der Migration sowie applikationsspezifische Konfigurationen über Hunderte oder Tausende von virtuellen Maschinen hinweg orchestrieren.
In kleineren Umgebungen oder bei einer begrenzten Anzahl virtueller Maschinen kann MTV auch manuell über die OpenShift-Konsole eingesetzt werden, ohne zusätzliche Automatisierungstools.
Das Migration Toolkit for Containers (MTC) spielt derzeit eine Rolle in bestimmten Storage-Migrationsszenarien, insbesondere dann, wenn im Rahmen der Virtualisierungsmigration persistente Daten zwischen unterschiedlichen Storage-Backends verschoben werden müssen. In einigen Workflows ist MTC aktuell noch eine notwendige Abhängigkeit. Perspektivisch wird jedoch erwartet, dass diese Abhängigkeit entfällt, sobald Storage-Migrationsfunktionen stärker in MTV oder in die OpenShift-Kernfunktionen integriert werden. Dadurch werden Migrationsarchitekturen weiter vereinfacht.
Der menschliche Faktor: Migration ist kein rein technisches Thema
Nach der Betrachtung von Architektur, Networking, Storage und Tooling wird deutlich, dass die Migration zu OpenShift Virtualization kein ausschließlich technisches Vorhaben ist. Die Plattform ist ausgereift, die Werkzeuge sind leistungsfähig und die architektonischen Muster klar definiert. In der Praxis entstehen die größten Herausforderungen jedoch nicht durch fehlende Funktionen, sondern durch Menschen, Prozesse und Denkweisen.
Organisationen gehen OpenShift Virtualization häufig mit der Erwartung an, es verhalte sich wie eine klassische Hypervisor-Plattform. Genau diese Erwartung führt zu Reibungsverlusten. Zwar existieren viele vertraute Konzepte wie virtuelle Maschinen, Netzwerke, Storage oder Live-Migration, doch das zugrunde liegende Betriebsmodell unterscheidet sich grundlegend. OpenShift Virtualization basiert auf OpenShift und Kubernetes. Diese Grundlage bringt Voraussetzungen, Annahmen und Arbeitsweisen mit sich, die es in klassischen VMware-Umgebungen so nicht gibt.
Ein häufiger Fehler besteht darin, Hypervisor eins zu eins miteinander vergleichen zu wollen. OpenShift Virtualization sollte nicht als direkter Ersatz für vSphere auf Feature-Ebene bewertet werden. VMware ist eine hypervisor-zentrierte Plattform, die auf imperative Operationen und zentrale Verwaltung ausgelegt ist. OpenShift Virtualization hingegen ist eine Kubernetes-basierte Applikationsplattform, auf der Virtualisierungsfunktionen aufsetzen. Konzepte wie deklarative Konfiguration, Reconciliation-Loops und clusterweite Operationen sind daher keine optionalen Erweiterungen, sondern fundamentaler Bestandteil des Betriebsmodells.
Diese Unterschiede haben unmittelbare Auswirkungen auf Teams und Rollen. VMware-Administratoren werden nicht überflüssig, ihre Kompetenzen müssen sich jedoch weiterentwickeln. Der effektive Betrieb von OpenShift Virtualization setzt Kenntnisse in Git, YAML-Konfiguration und grundlegenden Kubernetes-Prinzipien voraus. Aufgaben, die früher über grafische Oberflächen ausgeführt wurden, werden heute als Code beschrieben und über Pipelines sowie Automatisierung gesteuert.
Schulung spielt eine entscheidende Rolle für einen erfolgreichen Übergang. Ohne strukturiertes Enablement fällt es Teams häufig schwer, bestehende Virtualisierungsexpertise mit Kubernetes-nativen Betriebsmodellen zu verknüpfen. Frühzeitige Investitionen in praxisnahe Trainings reduzieren Reibungsverluste deutlich, verkürzen Einführungszeiten und stärken das Vertrauen innerhalb der Teams.
Hier in CROZ haben wir ein strukturiertes Trainings- und Enablement-Programm entwickelt, um Organisationen dabei zu unterstützen, die erforderlichen Kompetenzen und das notwendige Vertrauen für eine erfolgreiche Migration von VMware zu OpenShift Virtualization aufzubauen:
- Grundlagen Docker & Containerisierung
- Kubernetes Grundlagen
- Vorbereitungskurs zur Kubernetes Zertifizierung CKA oder CKAD
- Grundlagen Red Hat OpenShift
- OpenShift Virtualization: Modernisierung von Workloads
- VMware Exit Strategie & Alternative Plattformen
- Grundlagen Ansible
Ebenso entscheidend ist der organisatorische Aspekt. Erfolgreiche Migrationen erfordern eine enge Zusammenarbeit zwischen Infrastruktur-, Plattform-, Storage-, Netzwerk- und Automatisierungsteams. Klare Verantwortungsmodelle, eine geteilte Verantwortung für Operatoren und Plattformkomponenten sowie gezielte Investitionen in Schulung und Weiterentwicklung sind dabei unerlässlich.
Teams, die OpenShift Virtualization lediglich als „einen weiteren Hypervisor“ betrachten, stoßen häufig auf Schwierigkeiten. Organisationen hingegen, die den Schritt als Plattformtransformation verstehen, realisieren langfristige Vorteile in Bezug auf Konsistenz, Skalierbarkeit und operative Effizienz.
Fazit
OpenShift Virtualization steht für eine grundlegende Weiterentwicklung in der Art und Weise, wie virtuelle Maschinen bereitgestellt und betrieben werden. Aufbauend auf Open-Source-Technologien, getragen von KubeVirt und QEMU/KVM und tief in die OpenShift-Plattform integriert, vereint es virtuelle Maschinen und Container in einem gemeinsamen, deklarativen Betriebsmodell. Die Architektur ist ausgereift, das Tooling-Ökosystem leistungsfähig, und die Plattform entwickelt sich dynamisch weiter.
Wie dieser Artikel gezeigt hat, hängt der Erfolg mit OpenShift Virtualization jedoch nicht allein von der Technologie ab. Er erfordert ein klares Verständnis der Kubernetes-basierten Architektur, eine sorgfältige Planung von Netzwerk- und Storage-Design, einen disziplinierten Einsatz von Automatisierung und Operatoren sowie – vor allem – Investitionen in Menschen und Kompetenzen. Organisationen, die diesen Schritt als Plattformtransformation und nicht lediglich als Austausch eines Hypervisors verstehen, sind deutlich besser positioniert, den vollen Mehrwert zu realisieren.
Damit gelangen wir zum nächsten Schritt auf dieser Reise.
Im nächsten Beitrag dieser Serie lösen wir uns von der Plattform selbst und richten den Blick auf das, was häufig schon lange vor der Migration der ersten virtuellen Maschine über Erfolg oder Misserfolg entscheidet: Planung und Assessment. Wir beleuchten, warum die Assessment-Phase entscheidend ist, weshalb sie sich weniger auf OpenShift Virtualization selbst und stärker auf Drittintegrationen wie Storage und Backup konzentrieren sollte und wie Unternehmen ein realistisches und belastbares Bild ihrer bestehenden VMware-Landschaft entwickeln. Außerdem betrachten wir, wie Migrations-Roadmaps typischerweise aufgebaut werden, welche Rolle Tools wie RVTools dabei spielen und warum Persona-Mapping sowie Mitarbeiterschulungen als zentrale Eingangsgrößen und nicht als nachgelagerte Maßnahmen verstanden werden sollten.
Wenn Sie es mit einer erfolgreichen VMware-Ablösestrategie ernst meinen, beginnt alles mit einem strukturierten Assessment.
Bleiben Sie dran.
Falls Sie Fragen haben, sind wir nur einen Klick entfernt.