


Putting customer front and center changed much in how we perceive technology and what we expect from it. For the last 20-30 years, all technology advances were aimed primarily at speeding up the process of producing the right features and delivering them to end users. The Cloud, containers, microservices, decoupling, API economy, automation… all these concepts are in the service of fast experimentation and shortening the feedback loop.
Ten years ago, we were developing fat, monolithic applications running on heavy-weight application servers. The deployment process was manual and rare were the people who managed to configure everything correctly on the first try resulting in a perfect application start-up. More commonly some manual configuration step was forgotten that turned routine deployment into a murder scene and a quest for missing or misconfigured properties. So strong was the trauma from such an experience that people soon stopped deploying on Fridays to prevent outages from ruining their weekends.
Can we truly put the customer front and center if we’re so afraid to push new features to production that we’re doing it less often than going to the dentist?
Every significant piece of technology in the last 20 years helped in reshaping this reality. Microservices and APIs helped in decoupling the system, the cloud helped in fast provisioning of the runtime environment, containers helped in packaging the software to be more suitable for automation. As soon as people recognized these benefits, they became more confident in their delivery process. Very soon we had organizations taking down “No deploys on Friday” banners and deploying to production on every single codebase change. True one-piece flow.
The flip side of these benefits is that technology is becoming increasingly complex. Cloud Native Computing Foundation (CNCF) maintains Cloud Native Interactive Landscape – a map intended to guide people through cloud-native technologies. There are more than 1,500 projects on the map. Although you won’t be using all of the projects, it does give you a feeling of what kind of jungle is out there. There is no way a single team, let alone a single person, could have enough skills, knowledge, and capacity to build the software solution, the infrastructure it runs on, automation, monitoring and security tools, etc.

CNCF Cloud Native Landscape
As true as it might be that modular and loosely-coupled systems bring many benefits, they also make systems more complex. Therefore, one cannot say that distributed architecture is necessarily better than the monolithic one without truly understanding the context. Distributed systems require more infrastructural components that are additionally even more complex than they used to be.
Putting customer front and center means working on features that are most valuable to the customers and delivering them as fast as possible. It has been proven time and again that the fastest delivery process is the one in which a single team has full control and autonomy to deliver value end-to-end, without handing off work items to other teams. Hand-offs are typically points where friction happens. Things get lost and forgotten. Tasks get misunderstood and priorities reshuffled. All this results in process bottlenecks where tasks end up waiting to be pulled.
To speed up the delivery process, a single team could potentially take over a lot of tasks to be more independent and enable the rapid flow of change. This team could for example install all necessary infrastructure components, build collaboration tools, build automation scripts, provision all environments, build the solution, figure out how to do observability, put vulnerability scanning components in place, etc. Having control over all of these aspects of the software delivery process and supporting components would surely increase their independence and allow them to deliver features without depending on other teams. Without hand-offs, they would be able to deliver features at the highest possible pace. That is probably true.
But there is also a downside to this approach. Setting up and taking care of all the infrastructure components while also building the software solution takes a lot of different skills, not to mention time. There are so many new things to learn and, as mentioned before, the technology is not getting simpler. Being able to own the infrastructure, the process, and the software solution while simultaneously keeping an eye on and evaluating new technologies and approaches that are popping up every day takes a lot of human bandwidth. In fact, it takes so much bandwidth that it’s unrealistic to expect that a single team could do it in a reasonable period of time. This is what Matthew Skelton and Manuel Pais call the “cognitive load”.
The cognitive load is the Work in Progress that happens in our heads. If too many things are in our focus, then everything takes forever and nothing gets done.
Imagine developing a simple calculation service. You read the specification and are ready to develop it. You fire up your favorite IDE and start coding. WAIT, where do I take this configuration from? What is the best practice? Let me see… A couple of hours later… OK, where were I… coding… WAIT, how do I build and run this? People talk about this container stuff… A couple of days later… These containers are so much fun, let’s move on… WAIT, where do I deploy this? I need a test environment, let me create one… A couple of weeks later… OK, this Kubernetes is pretty cool, where were I… deploying… WAIT, how do I deploy this? I need some kind of script, let me create one… A couple of weeks later… Ansible rules… Where was I… deploying a calculation I believe… What calculation was it? What year is it today anyway? Is the pandemic over yet?
Although a bit exaggerated, this is what happens in real life. Teams try to do everything on their own and their pace of delivery grinds to a halt. There is always a tension between taking over more of the process and infrastructure to remove hand-offs and taking too much of it that pushes the cognitive load over the team’s capacity.
Taking more scope increases autonomy and removes hand-offs, but increases cognitive load. Taking less scope reduces cognitive load but introduces hand-offs and possible bottlenecks. The art is to strike that perfect balance.
One approach to cope with this situation is by applying the concept of Team Topologies to your organization. Team Topologies describe four fundamental team types that an organization needs and interactions between them. These four fundamental team types are:
- stream-aligned teams
- enabling teams
- complicated subsystem teams
- platform teams
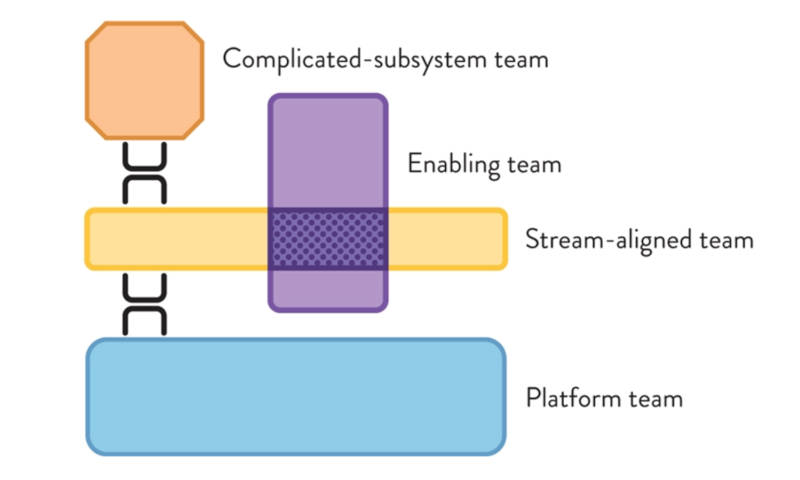
The Four Fundamental Team Topologies
Fast delivery of value to the customers is the ultimate organizational goal. Stream-aligned teams are the ones that are delivering new features. But with all the process and infrastructure complexity that is out there, we need to offload some of that complexity to the other teams so stream-aligned teams can have a fast flow of change.
Enabling teams are there to help stream-aligned teams pick up new skills, for example when service would benefit from a reactive programming model to increase performance. The reactive programming model is not trivial and requires a shift from the traditional programming mindset. It would take a considerable time for stream-aligned teams to learn this new programming model, explore available frameworks, pick the appropriate one, and learn how to use it. And all the while delivering new features to the customers. This is where enabling teams jump in. Like reconnaissance platoons, enabling teams explore that path in front, look for new technologies and approaches, and share this information with stream-aligned teams helping and enabling them to move faster.
Complicated-subsystems teams are there to encapsulate and offload very specific work for which very specific business or technical knowledge is necessary. A good example is developing a complex algorithm for displaying social media feed or developing middleware for embedded devices. One requires a deep understanding of business rules while the other requires a deep understanding of a very specific technology stack. It makes no sense for all the other teams to acquire that very specific knowledge. It makes more sense to form dedicated complicated-subsystems teams to develop those components and provide clear interfaces for all other teams to use.
Platform teams are there to build and maintain a platform that stream-aligned teams use to deliver software solutions. When talking about the internal platform we usually think of a technical platform covering source code repositories, build and release automation, and Kubernetes cluster complemented with observability and security toolset. But the platform is not restricted to technical solutions only. As Matthew Skelton says, a platform is “a curated experience for engineers – the thinnest set of docs, APIs, config, etc. that accelerates delivery in teams that use it.”
An internal platform is definitely *not* a wrapper around AWS/Azure/GCP/Aliyun. Don’t do that!
A platform is a curated experience for engineers – the thinnest set of docs, APIs, config, etc. that accelerates delivery in teams that use it. https://t.co/4ggPHNTk5u
— Matthew Skelton #BLM (@matthewpskelton) November 13, 2020
Building a technical platform is complicated, expensive, and time-consuming. If appropriate developer experience can be achieved with a simpler and cheaper solution, don’t go overboard building a super complex technical platform that nobody will fully use. Technology is in the service of organizational goals. Stick with the simplest solution that helps stream-aligned teams move fast. Sometimes that means just having good documentation.
How is this different, one might say, from what we had in the past?
If we look at stream-aligned teams as Developers, and platform team as Operations, don’t we have silos again? Although it might look like silos, the collaboration dynamics between these teams are fundamentally different. Traditional Dev and Ops worked completely independently. Developers were experts in development, there were no reasons for Ops people to mess with that part of the delivery process. Once the release was created, Dev people would just hand the binary file to Ops people who would take care of running it in a specified environment. This process reminds of a relay race where one team member is handing over the baton to the other one who is completing the race. Both runners are doing their best to win the race together, but the process is such that runners are bound to slow down during hand-off, and sometimes they even drop the baton which introduces even more delay. Each runner is running for themselves and cannot help each other.

Traditional Dev and Ops as relay race
The new (DevOps) paradigm resembles more of a bicycle race in which members of the same time ride together. They stay close to each other, in a tight formation called the peloton, periodically rotating on the leading position that is the most exhausting one with other team members drafting behind the leader. In this setup, every team member will achieve a better result than they could possibly do individually, without help from the others.

DevOps moving along as peloton
Four core team types act as a peloton in cycling. The ultimate organizational goal of fast delivery of value to the customers is impossible without all teams working together like cyclists in a peloton.
Sometimes people think that stream-aligned teams are the rock stars and all other team types are there just to help them deliver value. This is wrong. Every team type has its own purpose, and if there is a need for having such team type in an organization, it is as valuable as any other team type. It is a team effort. Without enabling, complicated-subsystem, and platform teams, stream-aligned teams would never deliver as fast as they could.



