Blog
Data Anonymization - Hide and Seek with Data
05.09.2019
Being anonymous in today’s world is so in that hacktivists and even less active groups like it. Surfers used to check their hairstyles before surfing, now they check if they’re anonymous. Tor likes it and we all know the data; they always have to be in, so they like to be anonymous too.
What Is Data Anonymization?
Data anonymization is the process of data manipulation in order to hide sensitive data.
The benefits of data anonymization are numerous. For example, anonymized data can be passed down from production to the testing or development environment, so that development and testing can be done using data which don’t contain sensitive information but maintain data relationships, types and other data characteristics which exist on the production environment. Furthermore, anonymized data can also be passed down to a third party that can perform machine learning on them and gain some valuable insights without knowing to which subject client results refer. That’s why GDPR is so in love with data anonymization that it leaves it speechless. Once the data are anonymized, they can be processed however you want without the consent of the data subject because that relationship becomes hidden or even broken so the data aren’t personal anymore and thus GDPR has nothing to say about them.
Data anonymization can be reversible or irreversible. With reversible data anonymization it’s possible to recreate the source dataset if the details about used data anonymization techniques are known and if their nature allows it. According to some sources, this process is distinct from data anonymization and it’s called pseudonymization. Other sources say that pseudonymization is just another data anonymization technique. With irreversible data anonymization it’s impossible to recreate the source dataset based on the anonymized dataset, even if the details about applied anonymization techniques are known.
Give us a call in case you need assistance in making your data anonymous, BFF’s with GDPR, totally in or so attractive that everybody want to hang out with them all the time.
Data Anonymization Techniques
There are many anonymization techniques. They usually replace an attribute’s value with another one, modify a part of an attribute’s value, remove data etc. Some of the most often used anonymization techniques are:
- Suppression
- Masking
- Pseudonymization
- Shuffling
- Data perturbation
Other anonymization techniques include the combination of two other techniques – it may involve some encryption, changing the row order, altering the type and the length of data, aggregation (if it’s acceptable for the anonymized dataset to contain less data or rows than the source dataset), etc. It depends on the nature of data you are working with and on the data anonymization goals.
Suppression
The removal of rows or attributes from the source dataset. It’s usually the first considered anonymization technique because it’s easy to apply and it can help speed up the anonymization process if some other data anonymization technique needs to be performed. It’s applied when some data won’t be needed in the anonymized dataset. Its reversibility depends on other applied anonymization techniques. For example, if suppression is the only anonymization technique applied then it’s reversible if the source dataset and the list of applied suppressions are known.
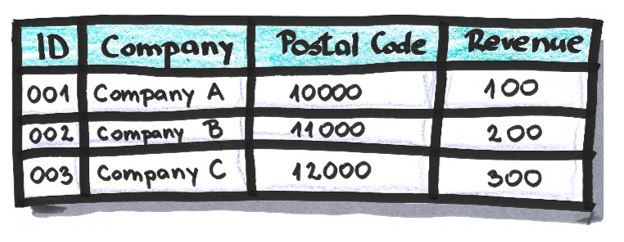
Example:
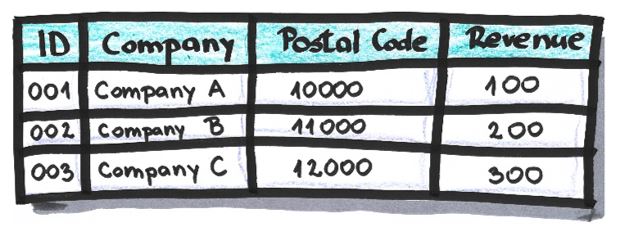
After the suppression of attribute ‘Postal Code’ and the row which relates to Company C:

Masking
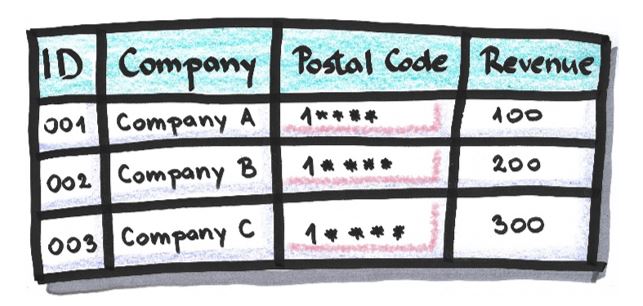
The replacement of a part of an attribute’s value with a character, usually ‘*’ or ‘x’. It’s used when it doesn’t affect the relationship between data or when that relationship won’t be important in the anonymized dataset. It’s often irreversible, because the special character could replace any character, as well as just one specific character, e.g. ‘A’.
Example:
After masking of attribute ‘Postal Code’ (last four characters are replaced with ‘*’):
Pseudonymization
The replacement of an attribute’s value with some other value based on a dictionary in which it’s defined which value maps to which. It’s used when referential integrity needs to be respected or when a certain relationship between data needs to be preserved. It’s reversible.
Example:
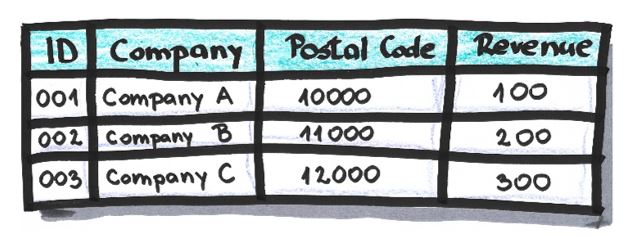
The dictionary in which it’s defined how source IDs will be mapped in anonymized IDs:

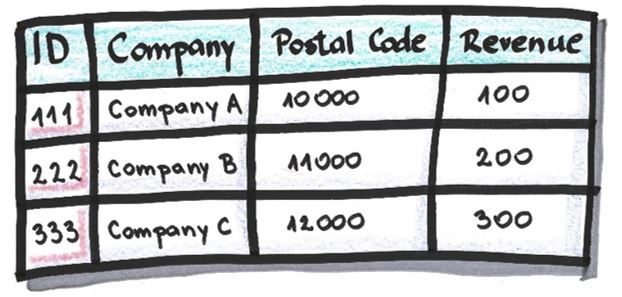
Table after pseudonymization based on the dictionary above:
Shuffling
The replacement of an attribute’s value with some, usually random, value within the same attribute. It’s used when it doesn’t affect the relationship between data or when that relationship won’t be important in the anonymized dataset. It’s usually irreversible.
Example:
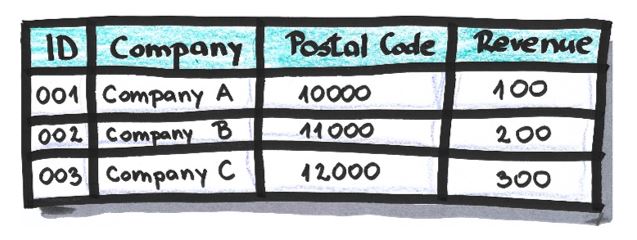
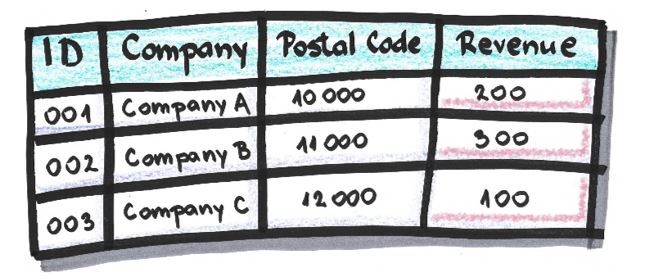
Table after values in attribute ‘Revenue’ are shuffled:
Data Perturbation
The replacement of an attribute’s value with some other value based on a mathematic formula. It’s used when it doesn’t affect the relationship between data or when that relationship won’t be important in the anonymized dataset. Its reversibility depends on the nature of the formula applied, but it’s usually reversible.
Example:
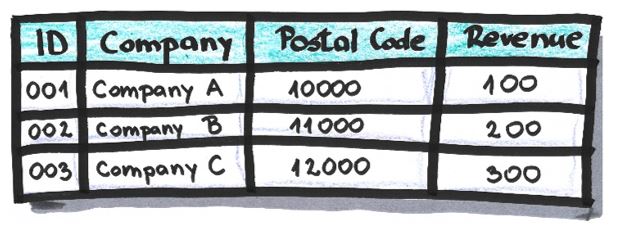
Table after values in attribute ‘Revenue’ are multiplied by 3 and 17 is added to that result:

It’s wise to use a more complex formula to increase the chances that the pattern won’t be noticed in the anonymized data, so that the source data can be better protected.
Data Anonymization Step-by-Step
Data anonymization isn’t just about anonymization techniques – it’s about much more, that’s why it’s a process. Things which need to be considered are:
- How, where, to whom, and in which format will the anonymized dataset be available
Will it be on an encrypted disk or maybe on a company network? Will it be available just to employees of a specific department, a third party or maybe the public? Will it be put in CSV files or in a new database schema? These and similar questions need to be answered. - Classification of data attributes
It’s important to determine the scope of the anonymized dataset; which tables, attributes and rows are of interest, which attributes contain sensitive information that could directly or indirectly lead to client identification or reveal some other trade secrets. Data which are usually targeted for anonymization are those which contain IDs, names, addresses, phone numbers, emails, revenues etc. - Data anonymization techniques
The choice depends on whether the anonymized dataset should be reversible to the source dataset or not, and on the nature, sensitivity and importance of the data which are being anonymized. - Anonymized dataset evaluation
Does the anonymized dataset satisfy the anonymization requirements? Are sensitive pieces of information hidden and is it practically impossible to reverse to the source without knowing all the details about the applied anonymization techniques? Is the anonymized dataset available only to the group it’s intended for? Is it encrypted? These types of questions need to answered, and requirements which should be met must be clearly defined in order to do that. - Legal measures
If necessary, the anonymized dataset should be legally protected, so that people who shouldn’t process it or people who shouldn’t reveal the insights they got by processing it could be legally prosecuted etc. - Documentation of data anonymization
The information about the process should be documented, especially if the data anonymization process should be reversible. Documentation should be stored securely, with limited access.
The need for data anonymization is increasing, especially since GDPR came into force. More often than ever do production data need to be made suitable for use on nonproduction environments or to be passed down for processing by a third party or even to the public etc.
Give us a call in case you need assistance in making your data:
- anonymous,
- BFF’s with GDPR,
- totally in,
- so attractive that everybody want to hang out with them all the time.