
Data streaming conferences
Each year brings us a bunch of conferences with great content on streaming topics. Two of the most popular are Confluent’s Current and Ververica’s Flink Forward conferences. If you missed those in 2023, here are my two cents on it. Flink Forward was of course focused on Flink and Ververica’s platform that is developed around Flink. But since Confluent is also placing a lot of eggs in the Flink basket, spotlights were on it as well in the Current 2023 conference.
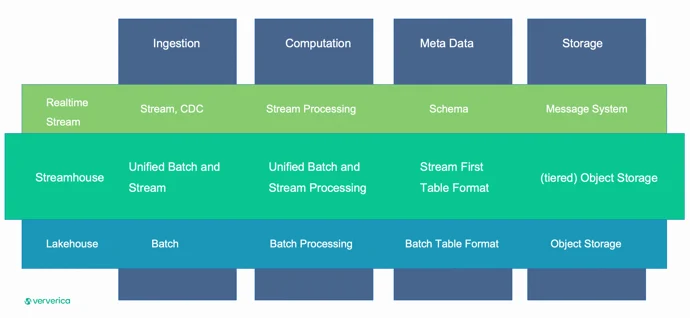
Ververica introduced Streamhouse architecture that brings the best of streaming and lakehouses. It is marketed as a unification layer between lakehouses and realtime streams by providing unified batch and stream processing. This makes sense since Flink can be used for both batch and streaming, but we could also argue on whether lakehouses are batch only and how Spark can also do both batch and streaming. And it would be an interesting discussion. I’m a big fan of Spark and I’ve been using it for many years now, but primarily for batch use cases because of the higher latencies in Spark streaming and lower feature set. One thing to note about Streamhouse is that it relies on Apache Paimon, a storage platform born as a Flink sub-project, which enables realtime ingestion of data while supporting both batch and streaming use cases. I’ll definitely keep an eye on Streamhouse in the future. If you want to read more about it, take a look at Ververica’s blog here, and for other highlights from the Flink Forward conference check this out.
One very important achievement in the development of Apache Kafka was the introduction of KRaft, a consensus protocol that removed Kafka’s dependency on ZooKeeper for metadata management. And that was one of the major things highlighted in Current 2023. I’m currently involved in a project where we will use ZooKeeperless Kafka, so I’ll definitely be looking forward to sharing our experience in one of the future newsletters. As I already mentioned, Flink was a hot topic at the Current 2023 conference. As Confluent acquired Immerok, a company that offered a fully managed Flink service in a cloud, they started introducing Flink capabilities in the Confluent Cloud platform.
In September 2023, Confluent introduced Confluent Cloud for Apache Flink which now enables the development of streaming applications using Flink’s SQL API, available in preview on a couple of AWS regions. So yeah, Flink is the coolest kid on the block. And if you’d like to read a bit more about the differences between Kafka Streams and Flink, check out the “Stream processing landscape” part of this newsletter. For more highlights on Current 2023, read here.
Did you know that CROZ is also hosting a conference? It is called QED (short for Quality in Enterprise Development) and this May we will host the 16th edition of the conference with a lot of great talks, starting with keynote speaker Sam Newman, the author of the books Building Microservices and Monolith to Microservices.
It wouldn’t be fair to end this conference section without giving a big shoutout to my colleague, Miroslav Bicanic, for delivering a great talk on Data Science Conference Europe on how to apply ML in realtime. The full video of the talk is available on YouTube.
Stream processing landscape
In the years following LinkedIn’s open-sourcing of Kafka in 2011, many interesting stream processing technologies emerged. Flink was first released in 2011 (then known as the Stratosphere project) and became a top-level Apache project in 2014. In 2013, LinkedIn open-sourced another project called Samza, which was used for stream processing and was developed in conjunction with Kafka. In the same year, Storm became a top-level Apache project. Also, around 2013, Apache Spark added support for stream processing, while the Kafka Streams library was released as a part of the open-source Apache Kafka project in 2016.
It’s obvious that data streaming was booming 10 years ago, and it’s more than just a hot topic still to this day. Some of the aforementioned technologies, including Storm or Samza are nowhere to be seen or heard, while some new ones emerged like Google Cloud Data Flow which is based on Apache Beam. But still, the most popular stream processing technologies remain Apache Flink and Kafka Streams.
When it comes to capabilities to solve most of the data streaming challenges, both Flink and Kafka Streams will be able to do the job. Flink is often regarded as a heavy lifter compared to Kafka Streams, capable of solving the most complex stream processing challenges, although such complex scenarios are not seen very often. So, in most cases, you would be good to go with any of the two.
But there are a couple of crucial differences between Flink and Kafka Streams that need to be taken into consideration:
Flink
- Runs in a cluster (YARN, Kubernetes, Standalone)
- Extremely scalable
- Supports Scala (deprecated), Java, Python, and SQL
- Integrates with multiple source and target systems like Kafka, Pulsar, RabbitMQ, Cassandra
- Excels in complex event processing (like detecting complex patterns in streams)
Kafka Streams
- It is a Java library
- Obviously, supports only Java
- Kafka is the only supported source and target system
- Integration with other systems could be done with Kafka Connect or custom integration
When it comes to projects we do for our clients, we use both Flink and Kafka Streams. In most cases we tend to go with Kafka Streams, however when data analytics is the primary use case, we usually go with Flink.
What is stream processing?
For those that want to go into technicalities, I’ll explain in a bit more detail what stream processing is.
In the simplest terms, stream processing is a common name for a set of tools, methods, and technologies that enable us to process data in real-time. To take it a step further think of it this way, stream of data is like a river that never stops flowing. As the river flows, it carries with it all sorts of things – rocks, leaves, and even fish. Data stream processing is like trying to capture and analyze all of these things as they flow by. It can be as simple as filtering a stream of data based on some value, or more complicated involving stateful aggregations on the stream or detecting complex patterns in data.
You will often see stream processing operations being divided into two categories: stateless and stateful operations. Stateless operations are simpler ones that operate on a single event and include operations like filter, split, or map. Those operations do not store any intermediate data between processing the current and next event in a stream. In other words, those operations don’t maintain any state and that’s why they are called stateless operations.
On the other hand, stateful operations like group by, aggregate, window or reduce need to maintain state while processing different events to be able to produce correct results. For example, if we want to count the number of API calls in the last hour, we need to increase the counter with each API call, therefore we are maintaining state and doing stateful operation.
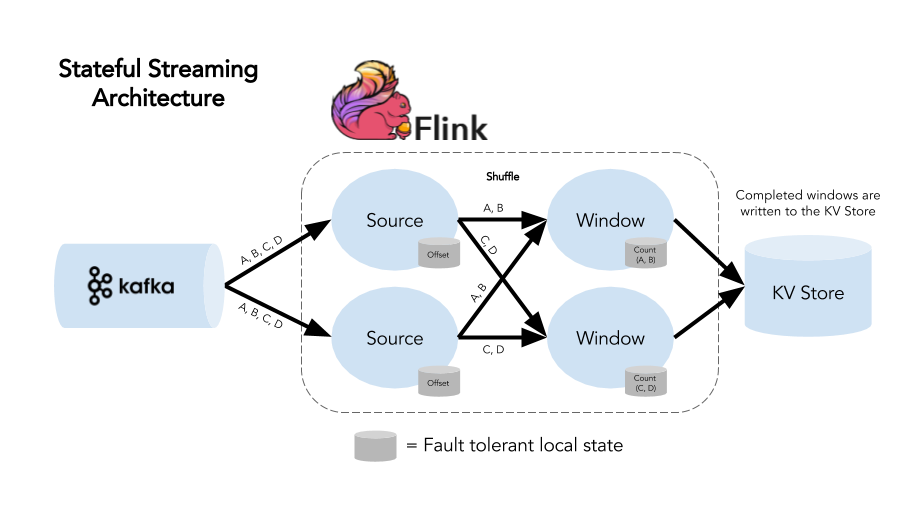
Figure 1: Flink Stateful processing (https://www.ververica.com/blog/queryable-state-use-case-demo)
That’s great! Now you can tell if your use case will require stateless or stateful operations. You might be wondering, what tool can I use to implement that kind of stream processing application? Some of the most popular frameworks and tools include Kafka Streams, Apache Flink, Faust, Spring Cloud Data Flow, Apache Spark, Azure Stream Analytics, Google Cloud Data Flow, IBM Event Automation, and the list goes on and on.
You can do both stateful and stateless stream processing with all the above-mentioned technologies, although some have more capabilities than others. Each technology has its pros and cons and is suited depending on whether you’re in the cloud or on-prem, whether you prefer Java or another language. If you are starting a new project or have some specific case and you’re not sure what stream processing engine to use, feel free to send me a message on LinkedIn and I’ll happily give you a few pointers and guidelines.
Tips & Tricks
Do you know how to use Kafka transactions to ensure exactly-once semantic (EOS) in your stream processing application?
Kafka transactions support is available since Kafka 0.11 and it provides ACID properties for a batch of messages published to Kafka. As we would expect from ACID properties, either all the messages in a batch will be written successfully or none of the messages will be written. This is important for use cases where data integrity is crucial and we can’t afford to lose data, like in the financial industry.
Now, we all know that Kafka is a distributed system, and although the exactly-once delivery is not possible in distributed systems (two generals’ problem), it can be achieved in Kafka with the combination of transactions and idempotent producers. Since Kafka 3.0, with acks=all and enable.idempotence=true properties on producers, we can easily make sure our writes to Kafka will provide level message ordering and duplicates protection.
So, in essence, we can achieve exactly-once semantics by using transactions and idempotent producers. And if you want to know more about it check out this blog post from Strimzi’s Federico Valeri. There are also some problematic edge cases found over the years with hanging transactions in Kafka. There is a great talk on this topic and improvements that are in the making delivered by Confluent’s engineer Justine Olshan on Current 2023.
Related News



