

In one of our previous blogs, we talked about the importance of using and contributing to Free and Open source projects and introduced MLflow (if you somehow missed that blog, go and check it out). In this blog, we’ll continue with “flow” projects and introduce Kubeflow, a toolkit for the deployment of Machine learning (ML) workflows on Kubernetes, and do a quick overview of services that Kubeflow offers. If you’re interested in a more hands-on introduction to Kubeflow, we’ll be releasing another blog that will go through the process of setting up and running a Kubeflow Pipeline
Growing demand for AI solutions introduces the need by more and more companies to have a platform on which they can build ML use cases. Implementing a solution to one ML problem can be easy, but maintaining various solutions in a team with multiple Data Scientists can be challenging. Generally, in those types of situations, we look for a platform that can ease the development process and simplify maintaining phase, hence Kubeflow.
Kubeflow offers components for simplifying or automating steps in a typical ML workflow:
- model research (Kubeflow Notebooks)
- training (Kubeflow Pipelines)
- hyperparameter tuning (Katib)
- model serving (KServe and similar)
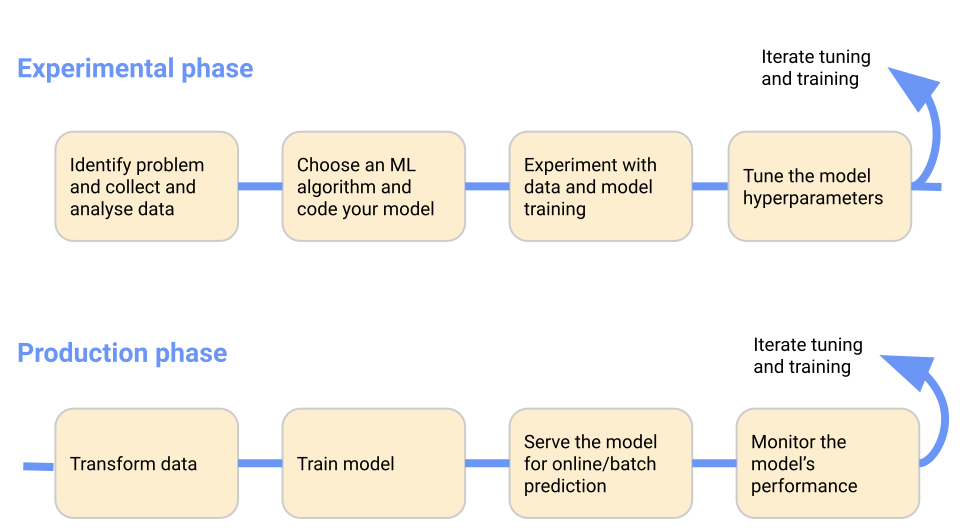
Typical ML workflow depicted on Kubeflow.
Central Dashboard
When you set up Kubeflow on your Kubernetes clusters, you can access the Central Dashboard or Kubeflow UI.
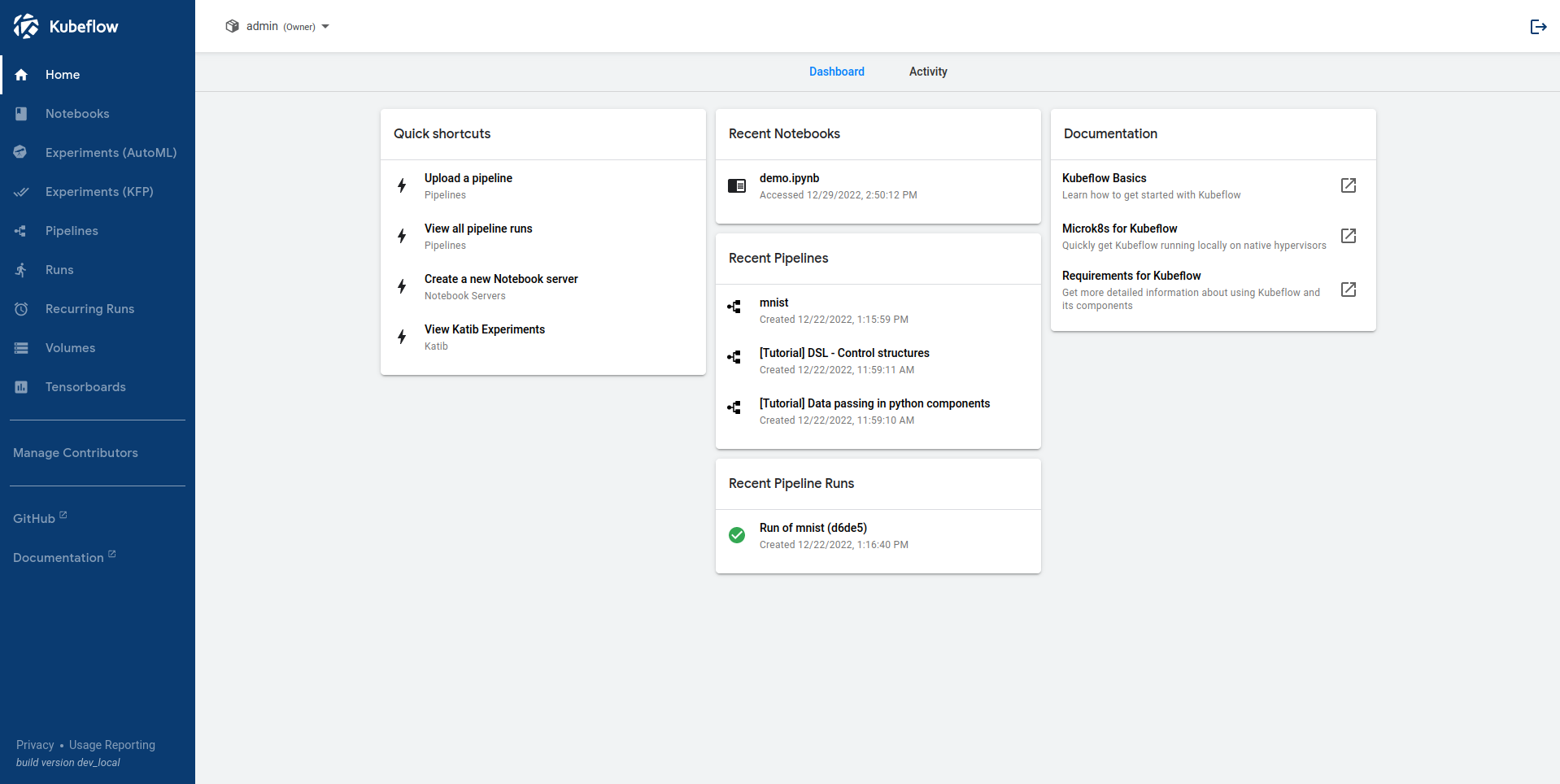
The menu on the left lets you access major components (alternatively, you can use quick access boxes in the middle):
- Notebooks and Tensorboards → managing Jupyter notebook and Tensorboard servers
- Models → managing deployed KServing models
- Volumes → managing cluster volumes
- Experiments (AutoML) → managing Katib experiments
- Experiments (KFP), Pipelines, Runs, and Recurring Runs → managing Kubeflow Pipelines (KFP) features
- Artifacts and Executions → ML Metadata (MLMD) features
- Manage Contributors → configuring user access across namespace
The top left, next to the menu, is a drop-down that lets you change a namespace. Namespaces (sometimes called profiles or workgroups) allow for multi-user isolation, i.e., only users with access rights can see components of a given namespace.
Components
Notebooks
Notebooks provide a way to run development environments inside your Kubernetes cluster. It supports JupyterLab, RStudio, and Visual Studio Code. It is a way for users to create notebook containers directly in the cluster using provided notebook images with packages pre-installed.
When you open the Notebooks dashboard page click on “New Server” and choose your configuration. Some of the things you can select are:
- Name → can include letters and numbers, but no spaces
- Image → Docker image for notebook server. You can choose already configured images or use a custom one
- Amount of CPU and RAM for your server
- Volumes that will be mounted as Persistent Volume Claim (PVC) Volume
After you select “Launch” your new notebook server will be created, and you’ll get an option to connect to it. When you connect, you’ll be redirected to another view where you can create new notebooks or import your own.
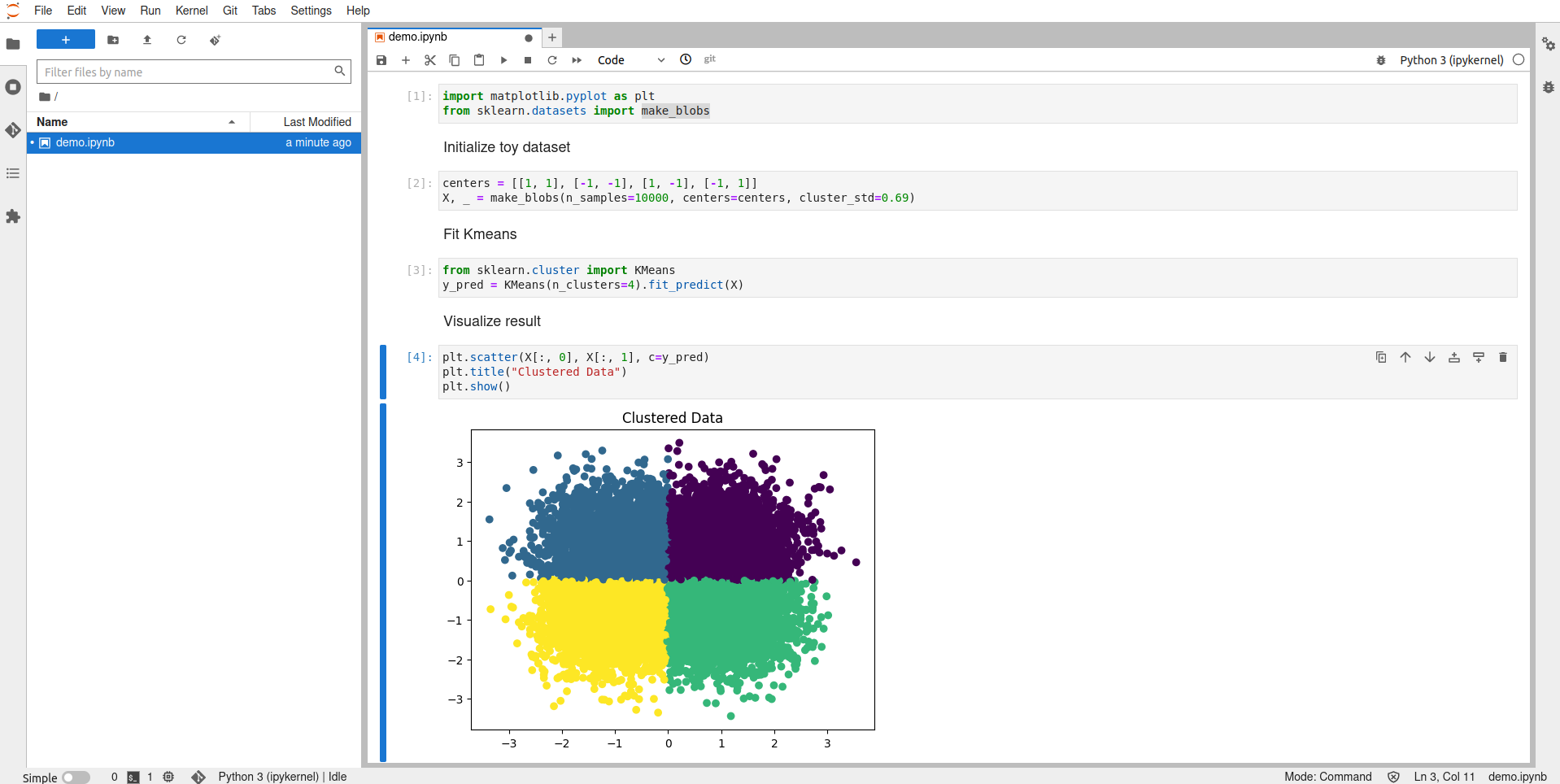
Pipelines
Pipelines is a platform for end-to-end orchestration of ML workflows based on Docker containers. Workflows are described using a pipeline (hence the name) which is defined by one or more steps called tasks. A task is a set of instructions for execution inside a single container and includes input and output parameters. It’s possible to link tasks to one another and for a computed acyclic graph (DAG) of tasks. Pipelines are written in Python for simplicity, compiled to YAML for portability, and executed on Kubernetes for scalability.
Opening the Pipelines dashboard gives you an overview of your pipelines and lets you upload new ones by specifying a YAML file, which you got by compiling your Python source code.
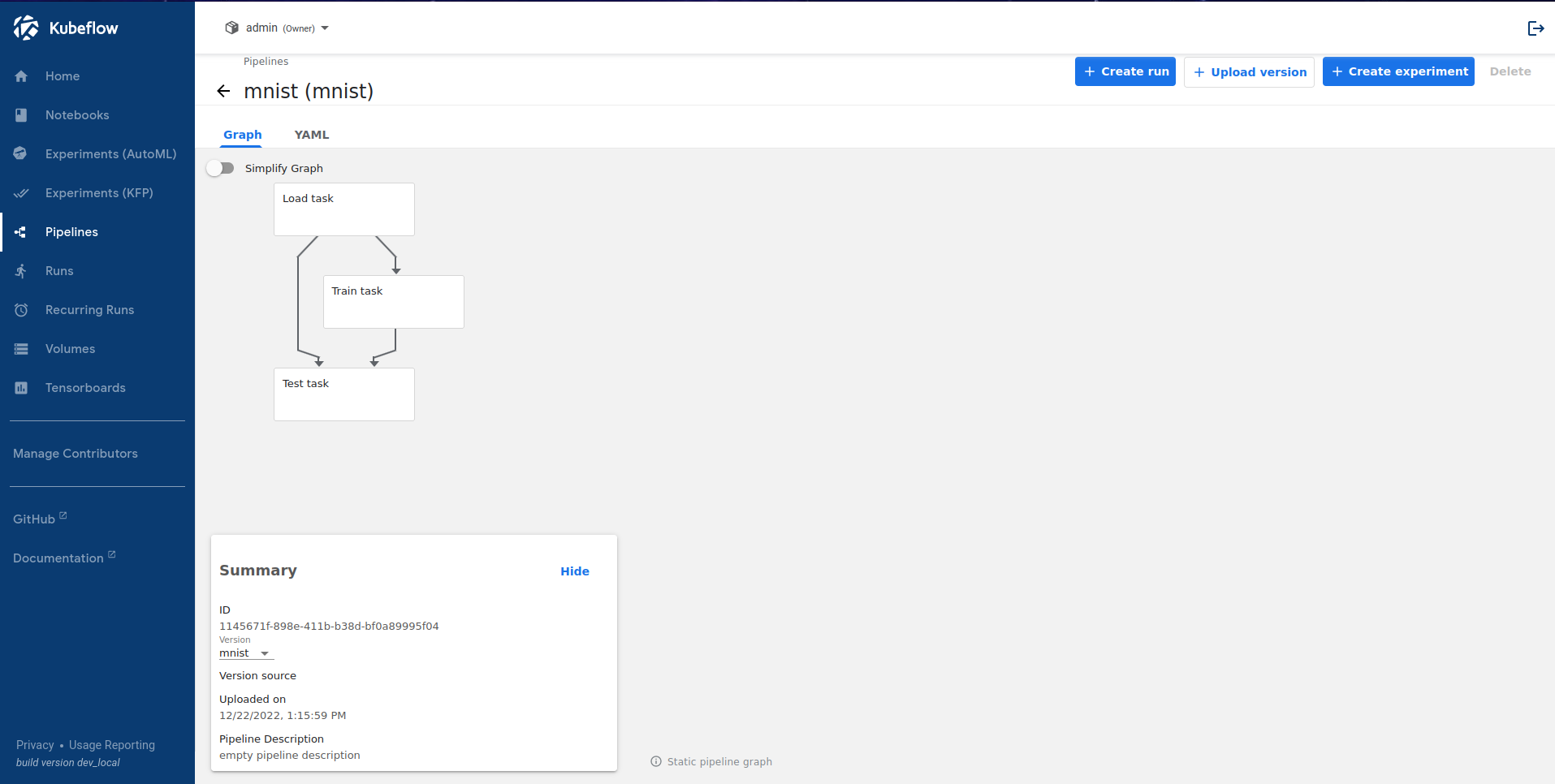
Once you’ve uploaded your pipeline, you can run it. Every pipeline run has an experiment associated with it, a space that contains the history of runs and lets you run different kinds of configurations of the same pipeline to compare the results.
Katib
Katib is a Kubernetes-native project for automated machine learning (AutoML). It natively supports many ML frameworks, such as Tensorflow, Pytorch, XGBoost, and others.
It is currently in beta status, which means there is a timeline defined for when it will become stable.
Tools for serving
Kubeflow offers two multi-framework model serving systems out-of-the-box, KServing and Seldon Core. Alternatively, it offers support for the standalone model serving system or external multi-framework systems like BentoML.
Summary
With Kubernetes being one of the most popular container orchestration tools it’s not hard to find a team that uses it, and with Kubeflow integrating into it without much extra configuration makes it a desirable service for any ML platform engineer out there. Features Kubeflow offers are extensive but simple to use and with a large community helping in maintaining and upgrading it, it will only become better.


