

Artificial Intelligence (AI) is all around us and is no longer a novelty in IT. It doesn’t surprise that more and more enterprise businesses are interested in using AI and toolssuch as MLflow for various business cases. Here in CROZ, we are always trying our best to provide modern solutions of high quality and reliability for diverse problems and business opportunities. You can read about our latest AI-related ventures in this blog written by our CTO Krešimir Musa.
In our effort to deliver the best product, we use many tools and technologies. While we always try to look for the best tool for the job, we are also aware of the importance of Free and Open Source (FOSS) technologies and we use them whenever an opportunity arises. In this blog, we will talk about MLflow, a great tool for our needs in CROZ and also an open-source platform.
MLflow in Machine Learning Cycle
MLflow is “an open-source platform for the machine learning lifecycle”, as it says on its official web page. In the following sections, we will address what a machine learning lifecycle is, to begin with, and why we need a dedicated platform to manage one.
In machine learning projects, there are many concerns related to building and maintaining good-performing pipelines. Those pipelines often consist of numerous steps with configurable parameters and sometimes even stochastic outcomes. A typical machine learning pipeline consists of the following parts:
- Data collection
- Pre-processing
- Model training
- Performance evaluation
- Product deployment
As a project grows larger, it becomes almost impossible to track everything that happens in each phase of the project and in different parts of the pipeline. That’s why using version control tools such as Git is the norm in any professional IT environment. Much like version control for code, some form of tracking is needed for machine learning-related elements, and MLflow provides exactly that. MLflow currently consists of four components for various parts of the ML life-cycle, and all four are of great use for every Data Science team.

Components
Although MLflow offers support for various stages and components of machine learning projects, we are mainly using MLflow Tracking and Registry alongside some other tools for pipeline orchestration and model serving, allowing us even greater flexibility.
Model Training
MLflow natively supports many machine learning frameworks such as Tensorflow, Pytorch, and Scikit-learn. However, sometimes, in our effort to find the best solution for our problems, we have to use customized models. In that case, MLflow offers the possibility to use Python function flavor for our models, as it provides the flexibility we need while still being highly integrated with all MLflow components. Logging a trained model is very straightforward, and one working example is shown in the following code block.
Model Train
mlflow.pyfunc.log_model(
python_model, # our trained model object
artifact_path, # path to model artifacts
registered_model_name, # name to be used in model registry
input_example, # dataset[:n] - first n rows of dataset used in training
signature
=
mlflow.models.signature.infer_signature(dataset),
)
Using trained models
After the training finishes, we can analyze results in the Experiments view by using MLflow UI. Here we have information on how long training lasted, which parameters were used, did the training finish successfully, what dataset was used, etc.
Data lineage is an important aspect of model governance. Using MLflow to track experiments gives us the advantage of knowing which model version was trained on which dataset, which parameters were used, who initiated model training, and finally, what were the results.
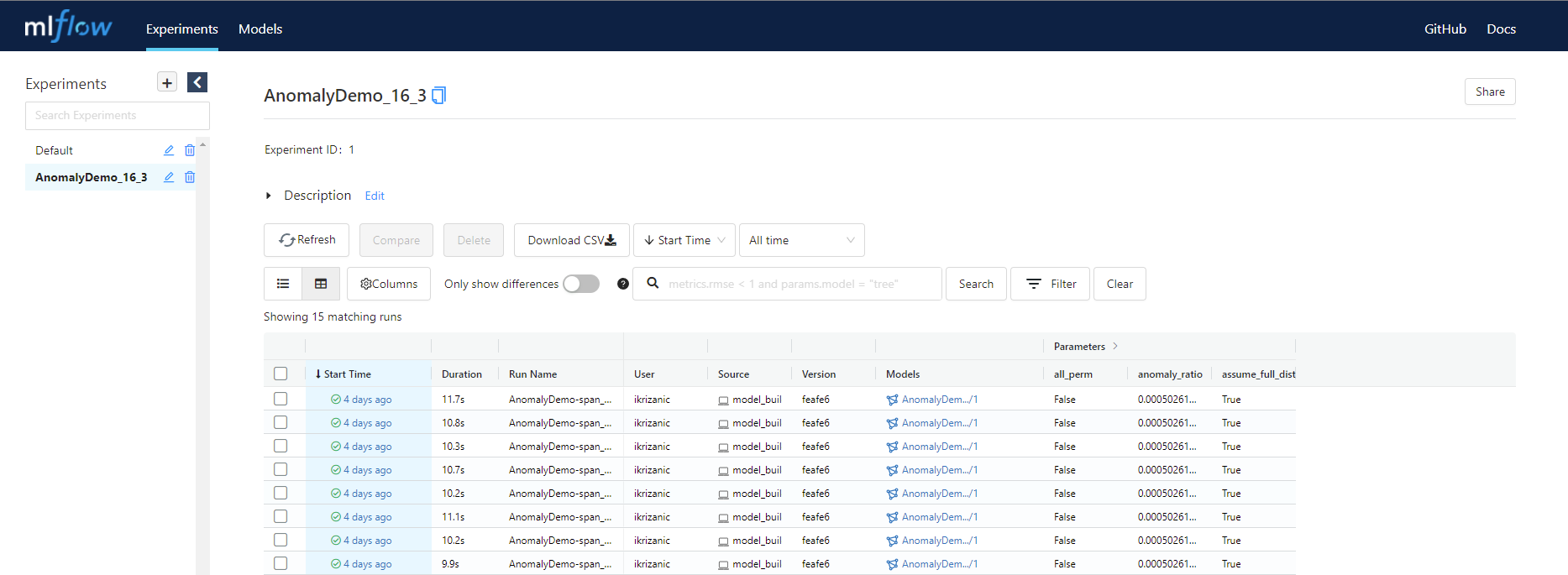
If we need more detailed information on a specific model, we can click on it in the Experiments view and review every logged information about the chosen model. Here we have all logged parameters, artifacts, and metrics.
Although experiment tracking doesn’t seem to be an overly complicated task, with a continuously growing number of models and experiments, it can become quite overwhelming if there isn’t any structured system of experiment tracking. Questions like “Did we check how parameter x influences metric y on model z if trained on dataset d?” require precise and structured logging, which MLflow Tracking provides.
If we are satisfied with the performance of our model, we can either manually register it using the MLflow UI, or we can register it programmatically during the training process. When we think that a registered model is production-ready, we can assign a specific model version to a production stage. Although this allows us to manage model versions easily, MLflow doesn’t provide advanced audit and user control in model registration and version control.
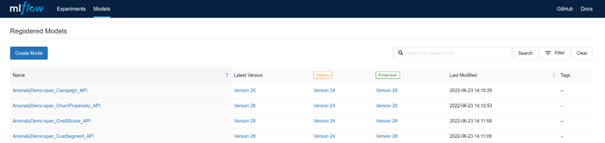
There are many more applications where MLflow shines, and though it’s not perfect in every possible way, it provides a simple and feature-rich solution for various ML workflows.
Components that are yet not implemented in MLflow are mainly related to security, integration, and inference monitoring. With MLflow being a relatively new project and counting many contributors, we have no doubts that the current lack of some features will be addressed in the future. As a gesture of gratitude for this amazing open-source project, and because of our interest in such technology, we began to contribute by solving some issues in the current MLflow roadmap, and we are looking forward to adding some features ourselves.
We strongly recommend you to use some kind of versioning in ML development and join us on our journey of creating better ML solutions, making lives easier for you as developers and for everybody else who uses them.

