
DataOps, is it just a DevOps for data processing? The new buzzword for some know-how that has already been present for some time? Just like data science is, at its core, something our grannies used to call statistics. Or is it something new and groundbreaking?
DataOps is a process-driven methodology that aims to monitor and optimize data management. It seeks to improve all of its phases, from brainstorming, collecting, storing and processing data to using it in reports and it seeks to establish optimal cooperation, integration between those phases.
Just a DevOps for data processing?
DataOps isn’t just a DevOps for data processing. In a way, it’s a superset of DevOps. It also aims to automate integration, testing and deployment of code or ETL jobs, but it also seeks to optimize phases occurring before that, shaping ideas and development. Since it’s agile by nature it aspires to constant cooperation improvements between all parties involved in the data management process e.g. managers, data consumers, analysts, data architects, data engineers, data scientists, data analysts. The outcomes are better sprints, efficiently and effectively meeting of client’s requirements, clearly defined goals and priorities, better data quality, code, ETL jobs, data reports, and better feedback.
Something new and groundbreaking?
DataOps’s main focus is on monitoring and optimization of the so-called data factory. The data factory consists of a value pipeline and innovation pipeline. Value pipeline is a stream through which raw data is collected and transformed into data used in various models and reports to make added value. Innovation pipeline is a pillar making sure the value pipeline doesn’t fall apart. If that’s not obvious when we let our imagination, see the picture bellow as a picture of a bridge. This pillar is built on ideas transformed into optimized code, ETL jobs which are the result of automated tests of data quality and business logic and continuous performance monitoring.
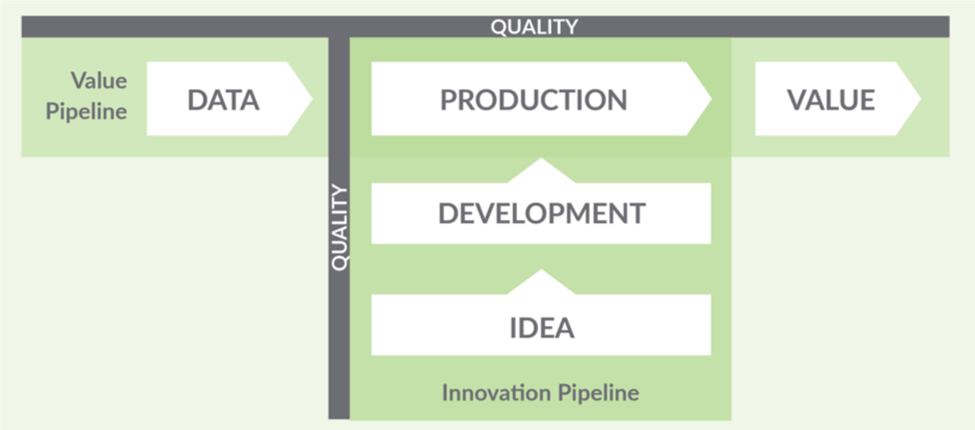
Before building a data factory it’s necessary to define what development, test and production environments will look like. From hardware and software used, various policies applying to them (security, GDPR, etc.) to source and scope of data residing, being processed and used. These days defining source and scope of data has a lot to do with data anonymization, especially since GDPR came into force, so this is the perfect place for free ad for our blog about data anonymization, Data Anonymization – Hide and Seek with Data, which could, joke aside, come in handy in those situations.
When the data factory is built and before development or at least first testing and deployment, measures of quality need to be defined. Data quality tests (e.g. does attribute x contain only numbers?), tests for implemented business logic (e.g. is calculated revenue the same as the one on the reports provided for test purposes?) and performance tests (e.g. how long does it take for ETL job to finish?). Requirements to be met to deploy code, ETL job should also be defined (e.g. after x consecutive days of running on development environment without an error code or ETL job can be deployed on a test environment) and automation of that process should also be defined.
If you are a data something – architect, engineer, scientist or analyst – does most of this seem familiar? I believe so. Maybe you didn’t apply everything mentioned to the full extent (e.g. higher degree of deployment automation), but the core of it looks like typical data processing related project activities. So it’s not something completely new, so it can’t be groundbreaking, but the importance of these activities and continuous need for their optimization is undoubted. It’s something that can make or break a project.
The new buzzword for some existing know-how?
Based on everything I’ve read about DataOps, my own experience and interesting conversations about DataOps with my colleagues, I would say that DataOps is the new buzzword for some know-how which, more or less, has already been present for some time.
It has a lot to do with that I was lucky enough when I started working at CROZ – it had already been well known for its agile culture and you could sense that when you were part of a project team.
Earning the client’s trust is of the highest importance to CROZ, especially in the early stages of a project and it’s hard to think of a better way for achieving that than by demonstrating proactive, agile culture. That also earns to you autonomy needed for implementing your best practices, know-how, going full DataOps and at the end that leads to a win-win situation for your team, project and most importantly, your client. Project teams, I was part of had to-do list related to mentioned DataOps activities in mind, we just didn’t call it DataOps.
Of course, not everything was clear from the start, but that to-do list made sure we never forgot what needed to become clear as the project evolved and as we were adapting our agility to the client’s organizational culture and needs. Optimization of brainstorming, collecting, storing, processing and data reports was always on our minds.
It seems to me that most struggles related to DataOps often have a lot to do with its DevOps part – achieving a high degree of automated integration, testing, and deployment. Probably not so much with deployment and integration as with testing. Various tools and shell scripts could come in handy while dealing with the first two problems, but tests automation could be tricky here, maybe not of the performance related ones but business logic related. CROZ tackles that problem with its testing automation framework or TAF which enables defining and scheduling execution of various SQL queries for testing performances and implemented business logic and it enables the generation of reports about their results.
Whether you also think DataOps is just a new buzzword for some already existing know-how or not, I’m sure we can agree on its significance in making sure that “Oops, I did it again” can only be heard in a song and not again and again said to your data. It’s excellent the methodology behind it got a name and it made people start talking and understanding it more in our constant seek for its improvements and optimization.
Feel free to give us a call in case you are interested in going full DataOps with us.
Related News



