The IBMs data and cloud solutions have recently been receiving recognition by Gartner and Forrester Wave in several fields – IBM was named a Leader in the latest Gartner’s 2021 Magic Quadrant for Cloud AI Developer Services and Magic Quadrant for Data Science and Machine Learning Platforms for Watson Studio. Forrester Wave evaluates IBM a leader for the Multimodal Predictive Analytics and Machine Learning, Q3 2020 for Watson studio and Watson Knowledge Catalog for Machine Learning Data Catalogs Q4 2020. Along that, Gartner recognized IBM as a leader in 2020 for Cloud Database Management Systems for its DB2 and Forrester recognized Red Hat-IBM and their Red Hat OpenShift 4.3 as the leading Multicloud Container Development Platform provider in Q3 2020.
What do all these solutions have in common? They are all part of IBM Cloud Pak for Data. In Gartner and Forrester Wave reports you could see in detail what are the capabilities and their scores against the other providers. In this blog post we will try to explain what we think are the key features that differentiate Cloud Pak for Data from others.
Cloud/Hybrid – multi cloud, Open Shift Containers
The foundation of all Cloud PAKs, including Cloud PAK for Data (CP4D), is Open Hybrid Multicloud Platform which is based on OpenShift containers. The main architecture of CP4D is of a loosely coupled data services, refactored to create containerized workloads. These containerized workloads are flexibly deployed, orchestrated, and managed at one place.
CP4D solution and services are all certified on Red Hat OpenShift. Full certification brings added confidence knowing that all the components came from a supported source and that container images contain no known vulnerabilities. Most importantly containers running throughout are compatible across Red Hat Enterprise Linux environments, regardless of the cloud type.
This means that the CP4D is cloud agnostic and can be deployed anywhere — private cloud, public cloud, on-premises or even with a hybrid approach which can mix any of these.
As you know, one of the reasons of the IBM acquisition of RedHat in 2019. was the prospect of developing hybrid cloud solutions and the whole family of Cloud PAKs prove that that strategy is going in the right direction.
Easily installed, changed, licensed and maintained
services and integrations
The main building blocks of CP4D – CP4D Services, since they are based on containers, are easily installed, changed, licensed, and maintained through the platform. The number of services which were added to or supported by CP4D is extended in each update. Cloud Pak for Data has a growing ecosystem of OpenSource, Partner, and IBM Extended Services. The full list of currently available Services is here and here. Just to mention some of them, the Services include well known IBM products as:
- Watson family of products
- Cognos Analytics and Dashboards
- DataStage
- InfoSphere
- SPSS Modeler
- DB2 family of products
Together with a set of third-party solutions, including:
- Postgres
- Apache Spark based solutions
- CockroachDB
- MongoDB
- Intel Deep Learning Reference Stack
In addition to CP4D Services there are two specific sets of resources available:
Industry accelerators – a set of artefacts that can help CP4D users address common business issues related to specific industry and can be used as a starting point for development of new business analysis case. Most accelerators include a Sample analytics project with everything you need to analyse data, build a model, and display results. The sample projects include detailed instructions, data sets, Jupyter notebooks, models, and R Shiny applications. Most accelerators also include a Business glossary that consists of terms and categories for data governance. The terms and categories provide meaning to the accelerator and act as the information architecture for the accelerator.
External data sets – external reference data that can be used to enrich transactional data. Some of the data sets provide historical data, while others provide real-time data e.g. weather forecasts.
Integrate a multitude of different data sources with Data Virtualization
Since there is a multitude of different data sources available, the main question is how to seamlessly integrate such mesh? One of the services that CP4D provides which handles this task is Data Virtualization. Data Virtualization integrates data sources across multiple types and locations and turns all this data into one logical data view.
What does this mean in real life? This means that You can use the data from any of Your data source, mix it together and provide a unified, Virtual view of this combination to any of CP4D service in the same manner as if all of them were the on the same data source. In the background, Data Virtualization service will analyse data sources and provide optimised, distributed SQL execution of data fetches without moving data, duplication, ETLs, or additional storage requirements, so processing times are greatly accelerated.
The Data Virtualization feature is available for most of the data sources in CP4D and it also provides connectors which can be used to access and use this feature on external sources (e.g. Amazon Redshift, Cloudera Impala, Google BigQuery, Microsoft SQL Server, Oracle).
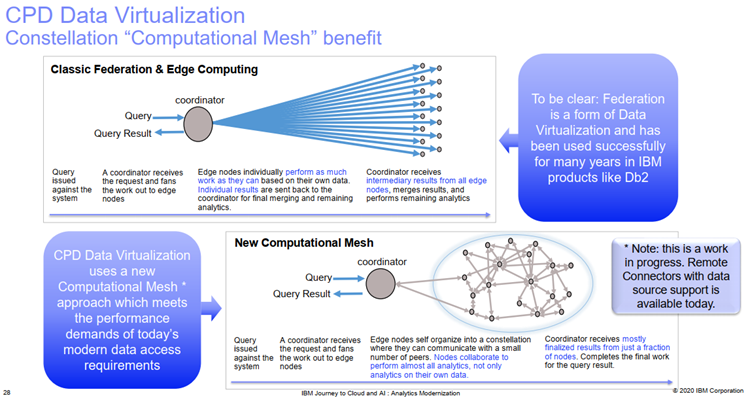
Following picture represent the difference between classic data federation approach and new Data Virtualization:
DataOps
Using the Watson Knowledge Catalog and Master Data Connect, CP4D provides a single point for all Data organization actions:
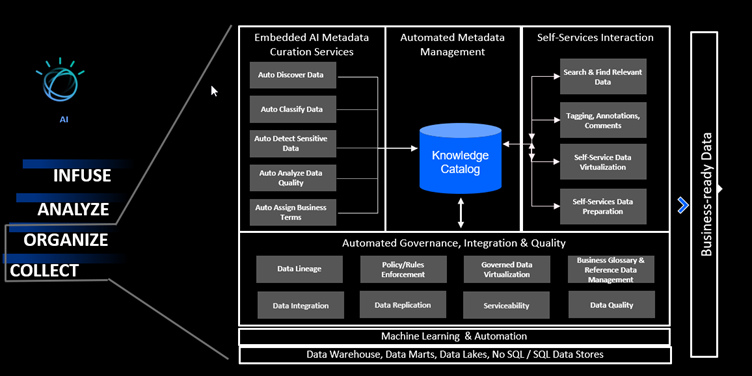
In everyday work with their data, companies often face challenges like complex integrations with siloed tools, extreme effort to properly curate and catalog data and finally making governed and protected data available to users. Centralized data governance and lineage help users to understand what the data means, where it comes from, and how it is related to other assets. There are a lot of APIs for extensive and customizable metadata management. Every user can enable self-service access to trusted and governed data and collaborate with other users. Only if you know your data and trust it, then you can use it.
If your data has poor or unknown data quality for critical data elements and you need to be compliant with regulations like GDPR in real time, Data Discovery and Quality feature of CP4D ensures fast time-to-value by leveraging ML to automate custom data discovery and curation processes. New industry-leading discovery of Personal Identifiable Information (PII) and critical data elements at massive scale with continuous analysis in real-time, wherever data lives have great impact in modern architecture. Main goal is delivering trusted, quality data with speed.
Today, many developers spend a lot of time for complex integration and transformation logic. They have issue with inaccurate execution due to data quality. In CP4D everything is under one platform and it is designed to optimize data integration delivery. You need to design only once and run everywhere with automatic load balancing and elastic scaling. Data could be captured in real time or bulk with In-flight data quality and data security. Data integration in CP4D is fast, efficient, secure, and scalable data delivery.
AI pipeline
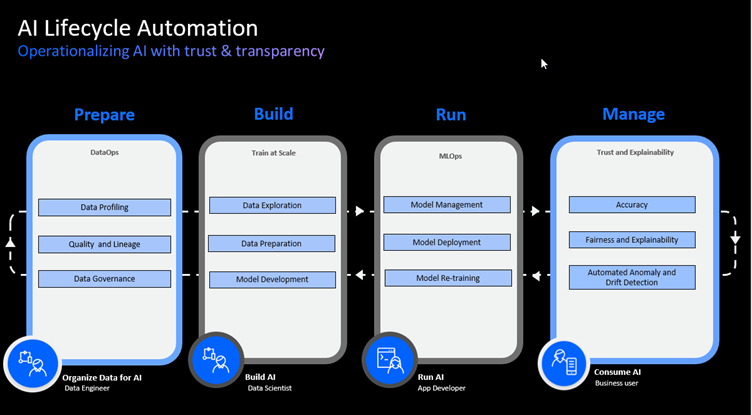
Building custom AI models could take weeks or months but with CP4D you can automate ingest, clean, transform, and model with hyperparameter optimization. Watson Machine Learning provides model deployment in one-click. CP4D AutoAI automatically prepares data, applies algorithms, and attempts to build model pipelines best suited for your data and use case and shorten development process to minutes.
Conclusion
In this blog we presented the set of CP4D features which we think that represents its main advantage over the other cloud solutions. This platform is part of the IBM Cloud Pak family (overview) and can easily be integrated with others. This is still a fast-evolving platform and with every new release a significant set of new Services is added.
This blog was a short overview of some of the functionalities of Cloud Pak for Data. For more information visit official IBM Cloud Pak for Data Page or contact us.
Extras
Bloor InDetail report Learn how IBM Cloud Pak for Data helps to build a trusted foundation to monetize data faster.
Make AI-powered business decisions with Palantir for IBM Cloud Pak for Data
Forrester shows how an integrated data and AI platform can help maximize insights from data.

Get faster planning and forecasting cycles on IBM Cloud Pak for Data