Azure Synapse is an analytics service that allows you to ingest, transform, manage, and analyse the data – all in one place. It is an integrated data platform that combines data warehousing and Big Data analytics. The Synapse data warehousing features are included in the dedicated SQL pool which is formerly known as SQL Data Warehouse. In a few recent projects, we have worked on the migration of data from an on-premises database to a dedicated SQL pool. That encouraged us to further explore possible methods of migration. In this article, we will focus on the migration process using copy activity in Azure Data Factory.
Architecture
In the following diagram, you can find an overview of the architecture that was used for the data migration.
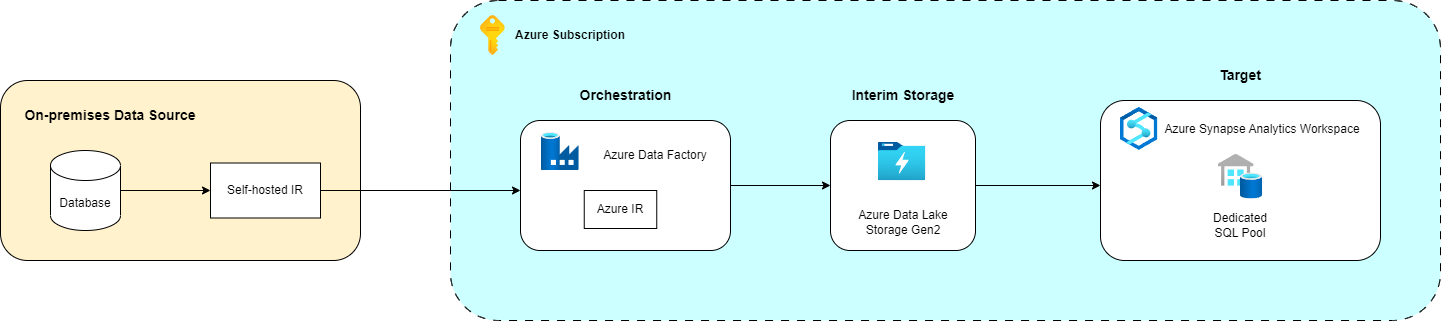
Azure Data Factory (ADF) is a data integration service for constructing ETL pipelines and orchestrating the movement and transformation of data. Some of the key components in ADF are pipelines and activities. Each processing step is represented as an activity and a logical group of activities that performs a task defines a pipeline. Copy activity is used to copy data between data stores located both on-premises and in the cloud. It is executed on a compute infrastructure known as integration runtime (IR).
There are different kinds of integration runtimes, and it is important to choose the appropriate one according to your requirements. When the on-premises source database resides in a private network and is not publicly accessible, the appropriate choices of integration runtimes are the Azure integration runtime with a managed virtual network or the self-hosted integration runtime. Since that was the case in our environment, self-hosted integration runtime was used to copy data between the on-premises database and a cloud data store. Besides the direct transfer from the on-premises database to the dedicated SQL pool, Azure Data Lake Storage Gen2 was set up as an interim staging store. For the cloud-to-cloud data transfer, both Azure integration runtime and self-hosted integration runtime were used.
The type of integration runtime is specified in the linked service configuration. A linked service is an object that contains the information needed for establishing a connection to a resource. For example, in our setup, three linked services were created – for the source database, the interim storage and the target datastore. Since each of those three resources can be associated with a different type of integration runtime, it is possible that a copy activity is associated with more than one type of integration runtime. In that case, the self-hosted integration runtime takes priority over the Azure integration runtime. For instance, if either the source or target linked service associates with a self-hosted integration runtime, the copy activity is executed on the self-hosted integration runtime.
Migration process
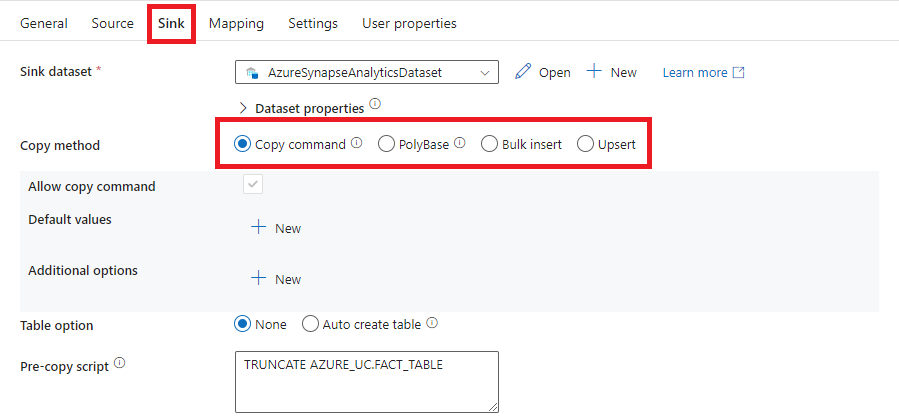
In case Azure Synapse dedicated SQL pool is specified as the target store inside the ADF copy activity, three options can be used to load the data:
- Bulk insert
- Polybase
- COPY command
We can specify the option we want to use in the copy activity Sink tab:
When using the bulk insert method, data is transferred directly from the source to the target database, while when using the other two methods, an interim staging store is used. The staging option can be enabled in the copy activity Settings tab:
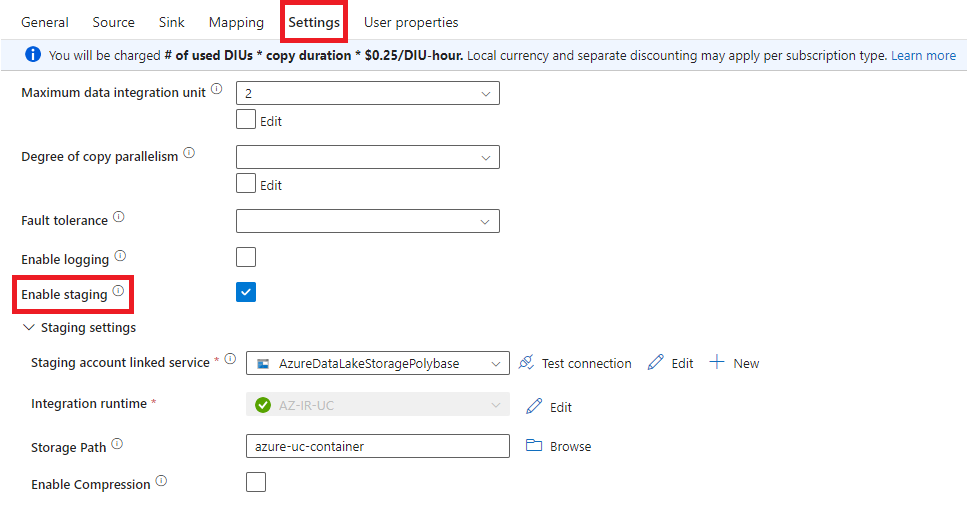
If the staging option is enabled, data is temporarily stored in Azure Storage, before loading it into the final target store. But why should we even bother to use the staging step when the data can be loaded directly to the target? The answer is simple – the methods that use the interim staging store are faster and highly parallel. A table with approximately 800k records was loaded from the on-premises database to the dedicated SQL pool using three different loading methods. The load duration was reduced by around 25% when using two methods with the staging copy feature enabled compared to the load duration when the bulk insert method was used.
What happens in the background?
All the queries that are generated during the loading process to Synapse can be found in the management view sys.dm_pdw_exec_requests in Synapse:
SELECT START_TIME, COMMAND FROM sys.dm_pdw_exec_requests;
When the Polybase option is used, data is first automatically converted to meet the data format requirements and stored in the specified interim storage. The next step is the load to Azure Synapse. During this step, the following additional resources are created:
- database scope credential – authentication information required for establishing a connection to Azure Data Lake Storage:
CREATE DATABASE SCOPED CREDENTIAL [ADFCopyGeneratedCredential_...] WITH IDENTITY = 'Managed Service Identity'
-
- external data source – a reference to the Azure Storage and a specification of the credential that will be used to access the storage:
CREATE EXTERNAL DATA SOURCE [ADFCopyGeneratedDataSource_281fa530-85e9-45ca-b076-e7e6bdc63e48] WITH ( TYPE = HADOOP, LOCATION = 'abfss://azure-uc-container@azhybridpipucstacsecured.dfs.core.windows.net/', CREDENTIAL = [ADFCopyGeneratedCredential_...] );
-
-
- external file format – description of the file type format:
-
CREATE EXTERNAL FILE FORMAT [ADFCopyGeneratedFileFormat_995f2f10-2339-40fc-a905-064a39889850]
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (
FIELD_TERMINATOR = '|',
USE_TYPE_DEFAULT = False,
STRING_DELIMITER = '',
First_Row = 2
)
);
Those resources are used for creating an external table:
CREATE EXTERNAL TABLE [dbo].[ADFCopyGeneratedExternalTable_3dfda399-4ddc-4174-9a62-3185d8f23b28] ( [COLUMN1] varchar(50) NOT NULL, [COLUMN2] decimal(38, 0) NOT NULL ) WITH ( LOCATION = '2655730c-2279-4c61-b1cf-2ff65dbfba16/Polybase/', DATA_SOURCE = [ADFCopyGeneratedDataSource_281fa530-85e9-45ca-b076-e7e6bdc63e48], FILE_FORMAT = [ADFCopyGeneratedFileFormat_995f2f10-2339-40fc-a905-064a39889850], REJECT_TYPE = value, REJECT_VALUE = 0 );
Data is then inserted from the external table to the dedicated SQL pool table:
INSERT INTO [AZURE_UC].[FACT_TABLE](
[COLUMN1],
[COLUMN2]
)
SELECT
[COLUMN1],
[COLUMN2]
FROM
[ADFCopyGeneratedExternalTable_3dfda399-4ddc-4174-9a62-3185d8f23b28]
OPTION (
LABEL = 'ADF Activity ID: 2655730c-2279-4c61-b1cf-2ff65dbfba16'
)
After the load is finished, all the auxiliary resources are deleted. It is worth noting that the used format type and format options are predetermined and can’t be manually altered in the copy activity settings.
The background process is a bit different when we choose the COPY command option. No additional resources are created when loading the data from the interim storage to Synapse, only the COPY INTO statement is used with the CSV file type and other options specified:
COPY INTO [AZURE_UC].[FACT_TABLE] (
[COLUMN1] 1,
[COLUMN2] 2
)
FROM
'https://azhybridpipucstacsecured.dfs.core.windows.net:443/azure-uc-container/53f9c651-5300-4374-801e-86a210e6212f/SynapseImportCommand/'
WITH (
IDENTITY_INSERT = 'OFF',
CREDENTIAL =(IDENTITY = 'Managed Identity'),
FILE_TYPE = 'CSV',
COMPRESSION = 'NONE',
FIELDQUOTE = '""',
FIELDTERMINATOR = ',',
ROWTERMINATOR = '0x0A',
FIRSTROW = 2,
ENCODING = 'UTF8'
)
OPTION (
LABEL = 'ADF Activity ID: 53f9c651-5300-4374-801e-86a210e6212f'
)
In this case, we also can’t alter the options used in the COPY INTO statement inside the copy activity.
Polybase vs. COPY command
We haven’t noticed a major difference in the duration of the load when comparing the Polybase and the COPY command method. However, the COPY command proved to be less error-prone while correctly loading the data.
The first issue that we encountered when using the Polybase method occurred when the DECIMAL type columns contained NULL values. In this case, the load failed with the following error message:
Unexpected error encountered filling record reader buffer: HadoopSqlException: Error converting data type VARCHAR to DECIMAL. Detailed Message=Empty string can't be converted to DECIMAL.
The solution was to unselect the ‘Use type default option’ in the copy activity Polybase settings. However, we need to be careful when unselecting that option because it specifies how the missing values are handled and it causes the empty strings in the VARCHAR columns to also be loaded as NULL values.
The second issue that we faced was related to the records that contained ‘rn’ or ‘n’. When using the Polybase method, new lines inside the records were interpreted as row terminators, so the load failed because the data was incorrectly arranged across columns:
Unexpected error encountered filling record reader buffer: HadoopExecutionException: Not enough columns in this line.
We haven’t encountered that issue when the COPY command method was used.
Pricing
Now let’s talk about everyone’s favourite subject – pricing. While Polybase and COPY command methods are faster, there is of course a price you must pay for that. When the staging is used during copying data from an on-premises database to a cloud data store, you are charged for two parts of the copy activity – on-premises to cloud (hybrid) and cloud-to-cloud transfer. We will explain the billing for the Data movement part through an example. Let’s say that we used one copy activity with the staging feature enabled to copy the data from an on-premises table to a cloud datastore. The load from on-premises to the interim staging took 1 minute and 20 seconds while the load from the interim storage to the target datastore took 40 seconds. The first part of the load is rounded up to 2 minutes and the other part to 1 minute. Then the price is calculated using the following expression:
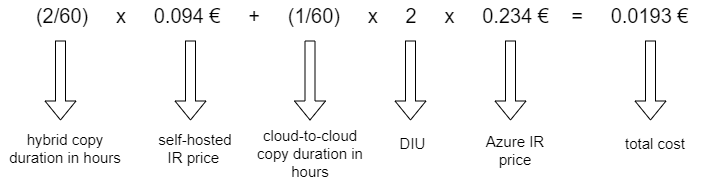
where DIU (data integration unit) is a measure which represents the power of a single unit in a pipeline which applies to the Azure integration runtime. Increasing the number of DIUs in the copy activity can speed up the loading process, but it also causes the price to go up. However, when copying the data into Azure Synapse using Polybase or COPY command, the number of DIUs is set to 2 and it cannot be increased.
The total price from our example may not seem high, but it is just the price of one copy activity for migrating only one table and the load didn’t last that long. The price would quickly go up if we were to migrate a larger number of tables and therefore use more copy activities, especially because you are charged a minimum of 1 minute for each activity, so the load duration is rounded up when calculating the price. Let’s just say that using copy activity is not cheap and we have learnt that the hard way.
It is worth emphasising that the self-hosted integration price per hour is approximately 5 times lower compared to the price of Azure integration runtime per hour when the lowest number of 2 DIUs is used. The cloud-to-cloud part of copy activity can also be executed on a self-hosted integration runtime which causes the overall price of the copy activity to be lower because only the price of the self-hosted data movement applies.
Load the data from Azure Data Lake Storage to Azure Synapse
There is a more budget-friendly way of migrating the data using interim storage. If the data is already loaded to Azure Data Lake Storage, instead of using copy activity to load the data to Synapse, we could use external activities and implement the whole process that copy activity carries out for us. We could write our own COPY command or create an external table for the Polybase load and execute all the commands through external activities in ADF. If we look into the total cost calculation in the example in the previous section, we can see that the self-hosted integration runtime price for data movement during copy activity is 0.094 € per hour of execution. When using external activity, the price per hour is reduced to 0.000094 € which significantly lowers the overall cost. However, if we opt for external activities, a lot of additional effort is needed to write all the necessary commands and maintain the whole process.
Conclusion
To sum up, from our experience when transferring data from an on-premises database to Azure Synapse, it is more convenient to opt for a method that uses the interim staging storage. Furthermore, if we were to pick between the Polybase and the COPY command option, we would go with the latter because it proved to be more reliable during our testing.
Literature: