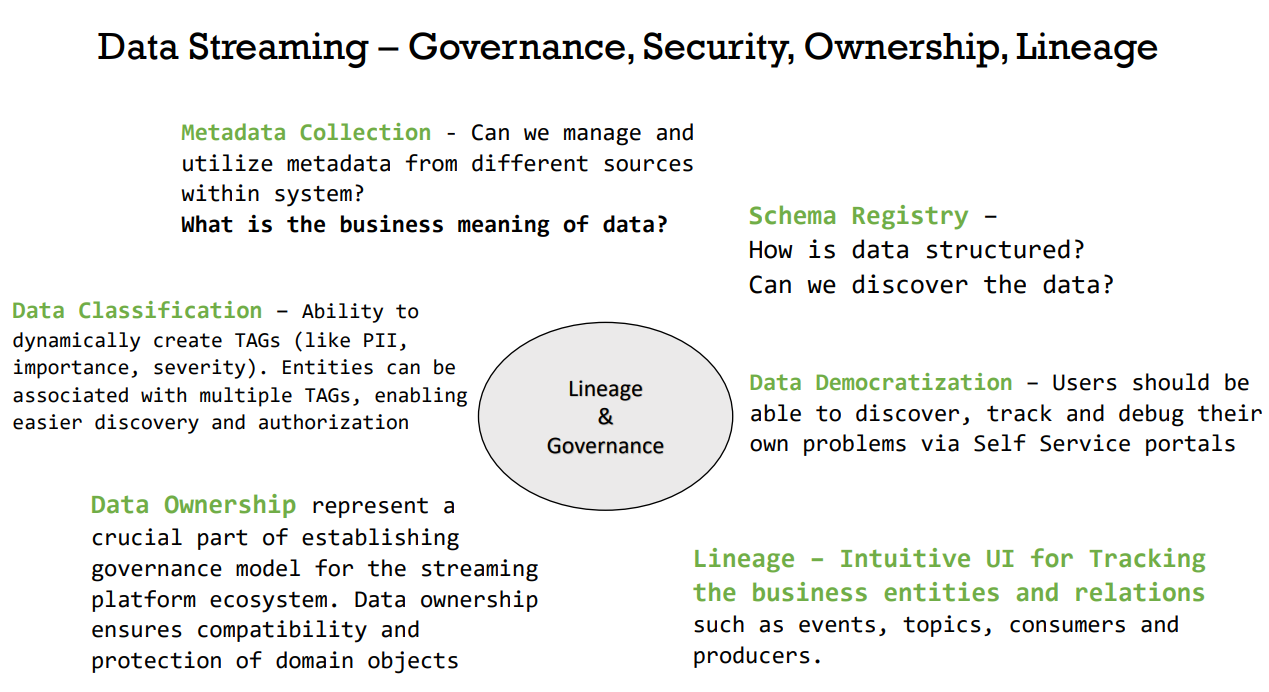
To keep up with the growing amount of data and its uses, companies often turn towards a data management concept called Data Governance. In short, Data Governance is a framework designed to help companies keep better control over the data that they possess by enforcing policies and rules that must be obliged when working with data. An example of a policy could be a naming standard that must be used for certain columns in tables, or perhaps a security policy that allows only some people to access a resource. Data Governance is a truly wide concept, but when it comes to streaming data there are specific parts of it that are especially useful when implemented correctly. Streaming data is characterized by its real-time data streams and because of them, we must treat it differently than data at rest. For better management and control of data streams, we must incorporate the following pillars of Data Governance:
1. Data security – it is important that all the resources are adequately guarded against unauthorized access and that only the necessary users are able to access the needed data. Applications like Apache Ranger are used for monitoring and enforcing access policies on resources.
2. Data catalog – it is a must to keep track of all the data that flows in our streams. Catalogs are especially useful because they allow us to keep in an organized manner all the metadata that is associated with our assets.
3. Schema registry – a part of the mentioned metadata is the schema that is paired with the data. Schemas are an important part of every data stream, not only because they describe the format of the data, but they also force users and applications to transform the data they use, not allowing them to push data to a stream in the wrong format.
4. Data lineage – a lineage graph allows us to track the data stream by identifying the key factors that are responsible for the changes made to the stream.
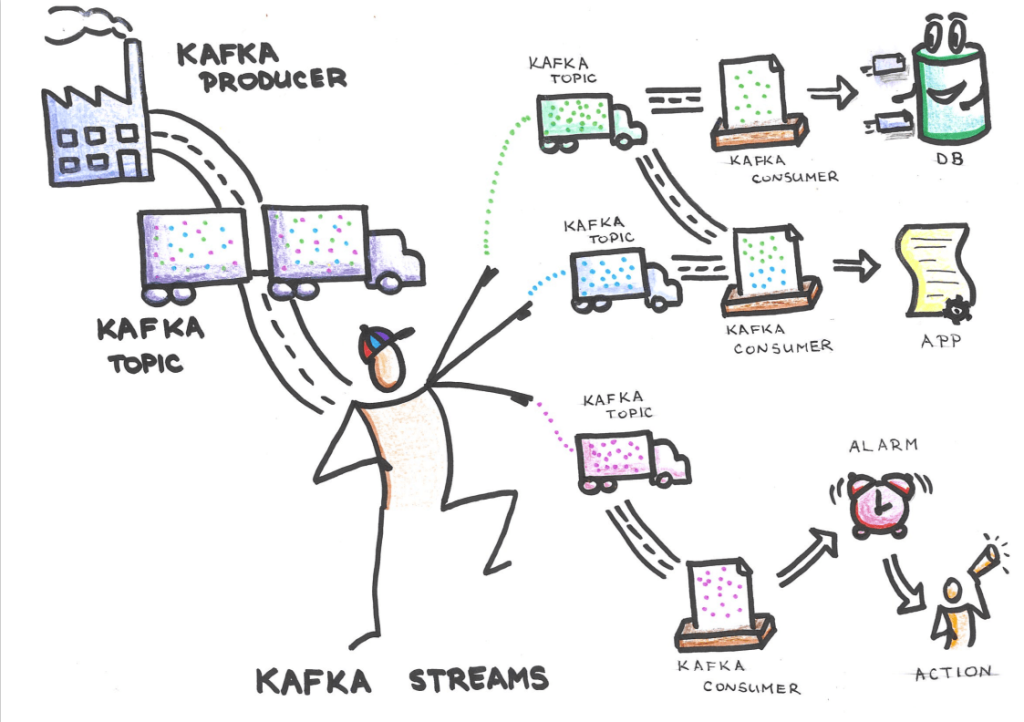
One of the most popular streaming platforms is Kafka. If you are familiar with Kafka, you probably know that there is not a lot of information available about the user’s interaction with the platform. That is because Kafka doesn’t have the tools to establish a Streaming/Data Governance concept out of the box. Commercially available platforms like Cloudera or Confluent have their versions of a streaming governance tool for Kafka. At CROZ, we developed a simple application that allows us to combine the 4 key points of Data Governance mentioned above.
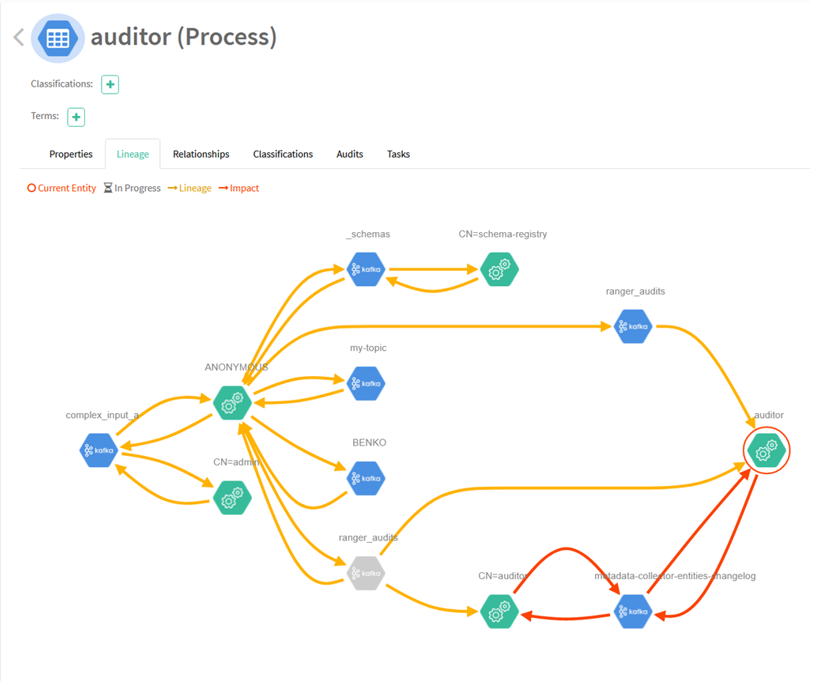
We ended up with a system built around Kafka, that allows us to have a better understanding and control of our data streams. By implementing streaming governance, we were able to secure and monitor every activity on our Kafka cluster. Not only by restricting access to resources, but also by keeping logs of every action that is made over the given resources. We established a data catalog that keeps track of all our topics and the metadata associated with them. Every topic is synced with its schema and is available for further classification to allow even stricter control and authorization. Thanks to the lineage graph, we got a graphical view of the whole path that a data stream forms, from source to sink. Every action by a user or application is shown. Now we are able to keep track of every producer and consumer that is associated with a topic. If we ever stumble on a problem, looking at the lineage graph we can trace its origins and find the cause.
To sum everything up, by implementing a streaming governance tool you get a secure environment in which you will be able to monitor, authorize and keep up with the changes that your data goes through, leaving you without any unanswered questions about your data streams.
If you are interested in the technical details, make sure to stay tuned for the second part of the blog where we will go through the whole process and the requirements for setting up the Streaming Governance concept using popular open-source projects like Apache Atlas and Apache Ranger.
In the meantime, find out what’s new in Apache Kafka 3.0.0.