Problems with big data
We live in a modern world where data is produced at every step. Data is captured from device metrics, location data, workflows, user behavior tracking, etc. There is also a diversity of storage mechanisms available for data as relational databases, NoSQL databases, document databases, key-value stores, object storage systems, etc. Many of these are necessary for modern organizations, sometimes even more than one at the same time. Not all of these allow us to query and inspect data stored with standard tools. Some cannot perform at necessary performance. Some of them don’t allow horizontal scaling which narrows several potential use cases. Also, it is not so easy to query data from multiple sources. If there was only a problem solver for all these problems.
Trino can solve all these problems and unlock new opportunities with federated queries to disparate systems, parallel queries, and horizontal cluster scaling. Trino also satisfies polyglot persistence.
Firstly, we will introduce you to Trino and its components and architecture. Then Web UI and clients will be described. The reader that already knows a thing or two about Trino can read more about query execution in Trino and the results of the performance testing of Trino on Hive data, Hive, and Hive-interactive in the following blog “The Future is Here – Trino”.
Trino
Presto was created to address the problems of low latency interactive analytics over Facebook’s Hadoop data warehouse. Later, Facebook wanted to grant their developers, who had no prior knowledge about Presto, commit rights on the project. At that moment, the founders of Presto went the other way, working on an open-source project. As a result of these events, two products were created – Presto as a part of the Presto Foundation established by Facebook and PrestoSQL that was later rebranded to Trino. Trino is a distributed SQL query engine designed to efficiently query large data sets distributed over one or more heterogeneous data sources. Trino breaks the choice between having fast analytics using an expensive commercial solution or using a slow free solution.
What can an end-user expect from Trino?
Trino is designed to handle data warehousing and analytics, including data analysis, aggregating large amounts of data, and producing reports. Together, these are classified as Online Analytical Processing (OLAP). As of all that, Trino supports SQL.
If you work with terabytes of data, Trino is designed to efficiently query vast amounts of data as an alternative to using pipelines of MapReduce jobs when querying HDFS the way Hive or Pig does. In addition to that, Trino is not limited to accessing HDFS. Using appropriate data sources at the right time can be of great performance boost instead of forcing only one type of database. This is called polyglot persistence. Trino has been extended to operate on different data sources, including traditional relational databases, Kafka, Cassandra, and many more.
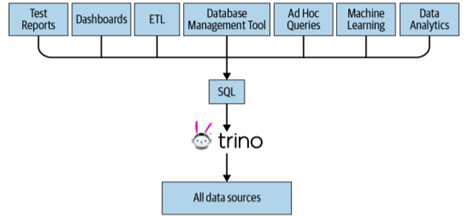
Figure 1. One SQL access point for many use cases to all data sources
Trino’s key components
Generally, there are two types of Trino servers:
- coordinators
- workers
There is always only one coordinator and one or more workers. The coordinator node can also be a worker node.
Trino coordinator is responsible for parsing statements, planning queries, and managing Trino worker nodes. The coordinator is the server clients connect to. Clients have no idea of the existence of the workers. The coordinator keeps track of the activity of each worker and coordinates the execution of a query. Using this track of activity creates a logical model of a query involving a series of stages, that later translates to series of connected tasks running on a cluster of Trino workers.
A Trino worker is responsible for executing tasks and processing data. It fetches data from connectors and exchanges intermediate data with other workers.
How does a coordinator know which workers are available?
Trino worker nodes advertise themselves to the discovery server in the coordinator. The whole communication between nodes is using REST API.
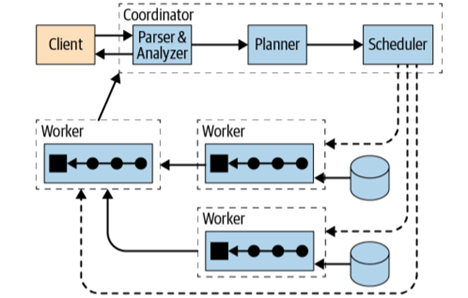
Figure 2. Trino architecture
Let’s clarify few more terms:
- connectors
- catalogs
- schemas
- tables
A connector adapts Trino to a data source. You can think of a connector the same way you think of a driver for a database. A Trino catalog contains schemas and references a data source via a connector. That means we can use multiple catalogs which use the same connector for different instances of a similar database. Let’s say we have two Hive clusters – we would define two catalogs that use Hive connector, and that would allow us to query data from both Hive clusters. Schemas in relational databases translate to Trino schemas, but sources that don’t have schemas defined will organize tables to schemas in a way that makes sense for the underlying data. Together, a catalog and schema define a set of tables that can be queried. A table is a set of unordered rows, which are organized into named columns with types. The mapping from source data to tables is defined by the connector.
Now we know some details about Trino’s concepts, yet we don’t know anything about Trino’s query execution and it’s implementation. For that, we need more knowledge about the following terms:
- statements
- queries
- stages
- tasks
- splits
- drivers
- operators
- exchanges
Why do we talk about statements and queries separately? We do so because, in Trino, statements refer only to the textual representation of a SQL statement. Trino executes ANSI-compatible SQL statements (those are statements that consist of clauses, expressions, and predicates).
When Trino parses a statement, it converts it into a query and creates a distributed query plan. This plan is realized as a series of interconnected stages running on workers. To make the difference between query and statements simple, the statement is a SQL text passed to Trino, while query refers to the configuration components needed to execute that statement.
A query is executed in the hierarchy of stages. The parent stage always aggregates the output of several children’s stages. Stages are used as a model of a distributed query plan for the coordinator. They are not executed on the workers.
Each stage is implemented as a series of tasks distributed over a network of Trino workers. A task has inputs and outputs and is executed in parallel with a series of drivers.
When Trino is scheduling a query, the coordinator queries a connector for a list of all splits available for a table. The coordinator keeps track of which splits are being processed by which tasks and which machines are running which tasks.
Drivers combine operators to produce output that is then aggregated by a task and delivered to another task in another stage. It is the lowest level of parallelism in the Trino architecture, and it has one input and one output.
An operator consumes, transforms and produces data. Examples of operators are table scans which fetch data from a connector, produce data to be consumed by other operators, and filter operator which will produce a subset of data applying a predicate over the input data.
Finally, exchanges transfer data between Trino nodes for different stages of a query.
Web UI
Trino server provides a web interface that exposes details about the Trino server and query processing on the server. The main dashboard shown in Figure 3 shows details about the Trino utilization and a list of queries. More information about the queries can be found when selecting a query. This is useful for monitoring Trino and tuning performance.
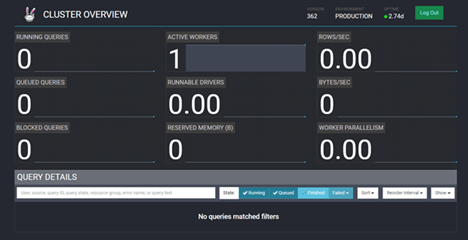
Figure 3. Web UI interface
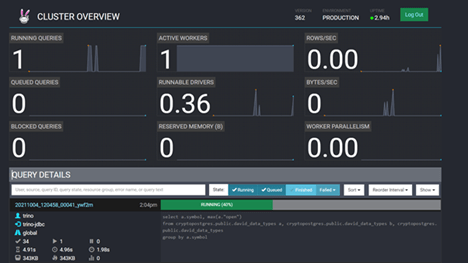
Figure 4. Web UI interface when the query is active
Trino clients
There are several Trino clients available. The first one is using the command line and is easy to use. Start the client and type the SQL you want to use to query your data. These would be
some meta examples of SQL commands:
show catalogs;
show schemas from [catalog];
show tables from [catalog].[schema];
select * from [catalog].[schema].[table];
There are also available drivers for Java, Python, Windows, Go, R, Ruby, etc.
I hope you liked the article and that Trino interested you enough to go deeper into the analysis. Now when you know everything about the basics of Trino, it is time for the next chapter. Find out more in the article “Future is here – Trino.”