

This is where data anonymization techniques become essential. By transforming personal data into a format that cannot be traced back to specific individuals, anonymization ensures privacy while allowing organizations to leverage data for valuable insights.
Why Data Anonymization Matters
1. Privacy Protection: Anonymization safeguards personal information, ensuring that sensitive data remains confidential and secure.
2. Regulatory Compliance: With stringent regulations like the General Data Protection Regulation (GDPR) in place, anonymization helps organizations comply with legal requirements and avoid hefty fines.
3. Ethical Data Use: Anonymizing data allows for ethical use and sharing, enabling research and analytics without compromising individual privacy.
In this blog, we will explore the use of Large Language Models (LLMs) for anonymizing free-form text. We will delve into the process of dataset generation and fine-tuning smaller models like llama3.1, and make them even more efficient by leveraging quantization. Additionally, we will discuss why LLMs are an interesting tool for this task, even when there are smaller models used for token classification which can anonymize text quite well.
Why use LLMs for data anonymization?
In the realm of data anonymization, traditional models like BERT and newer transformer-based models have proven to be effective tools, particularly for named entity recognition (NER). These models excel at identifying and classifying tokens within text, making them valuable for pinpointing specific pieces of information that need to be anonymized. However, the advent of Large Language Models (LLMs) has introduced new possibilities and advantages that are worth considering.
No need to train the model
The most important reason that LLMs are so popular today is the fact that LLMs can be utilized without the need for extensive training. Thanks to their broad and comprehensive capabilities, they can perform anonymization tasks effectively right out
of the box. This zero-shot capability is a game-changer for organizations that need to deploy solutions quickly and efficiently, regardless of the domain and the problem. It eliminates the need for time-consuming and resource-intensive training processes, allowing for immediate application.
Rewriting to remove private information
One of the primary benefits of using LLMs for data anonymization is their ability to rewrite text while preserving its original meaning. Unlike token classification models that simply identify and mask sensitive information, LLMs can generate new text that omits private data but retains all relevant context. For instance, an LLM can transform a sentence like “John Doe, a 45-year-old from New York, said…” into “A 45-year-old individual from a major city said…”. This capability ensures that the anonymized text remains coherent and informative, while also often making the text more readable and user friendly, which is crucial for maintaining the utility of the data.
Here is the example of using llama-3.1-405b-instruct model with zero-shot prompting in two different use-cases. The first one shows similar results to those if traditional models for token classification were used. The other one shows an alternative approach where the text is rewritten so that all valuable information is kept, but private data is left out, which can’t be achieved with traditional models.
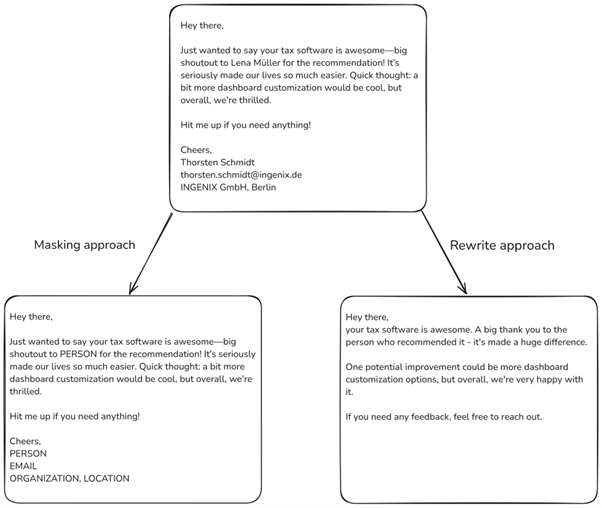
New entities? No problem!
Another significant advantage of LLMs is their ability to detect new entities based on context, even if those entities were not explicitly included in the training dataset. This is particularly important in dynamic environments where new terms and identifiers frequently emerge. LLMs leverage their extensive pre-trained knowledge to recognize and anonymize these new entities without the need for additional training. This flexibility makes LLMs highly adaptable to various domains and evolving data landscapes.
Challenges of using LLMs and the case for smaller models
While Large Language Models (LLMs) offer impressive capabilities for tasks like data anonymization, deploying them effectively presents significant challenges, particularly when choosing between on-premises and cloud-based solutions. On-premises deployment offers key advantages, such as enhanced control over data privacy and security, which is often a critical concern for organizations. By keeping LLM operations in-house, companies can mitigate risks associated with data exposure, which is a common concern when using cloud-based services or paid APIs like those offered by OpenAI.
However, running LLMs on-premises comes with its own set of difficulties. These models are inherently large, often comprising billions of parameters, and require substantial computational resources for both training and inference. The need for powerful hardware, such as high-performance GPUs, can be a major hurdle for many organizations. Unlike cloud infrastructure, which can easily scale to meet these demands, on-prem solutions often require significant upfront investment in hardware and ongoing maintenance, making it challenging for some organizations to justify the costs.
Fine-tuning LLMs for anonymization
Fine-tuning allows us to adapt pre-trained LLMs for specific tasks, such as anonymization, without the need for training from scratch. Really large models such as GPT-4o, Llama 3.1-405B and others don’t really need any fine-tuning for such tasks, as their performance is already at a very high level. When we start to experiment with smaller models, such as mentioned Llama 3.1-8B, we can notice that those models make mistakes, they won’t always deliver a consistent output format, sometimes they don’t stop generation at appropriate place, and the performance gets even worse if not working with English language. That’s where the process of fine-tuning shines.
This process involves:
1. Selecting a Base Model: Choose a smaller pre-trained model like Llama 3.1-8B
2. Defining the Task: Frame anonymization as a specific task, such as “Rewrite the following text, removing all personal identifiable information while preserving context.”
3. Preparing Training Data: Create a dataset of original texts paired with their anonymized versions (more on this in the next section).
4. Fine-tuning Process: Use techniques like PEFT (Parameter-Efficient Fine-Tuning) or LoRA (Low-Rank Adaptation) to efficiently adapt the model to the anonymization task. To further optimize the training process, we can use QLoRA – approach for fine-tuning quantized models
5. Evaluation: Regularly assess the model’s performance on a held-out validation set to ensure it’s learning the task effectively.
Datasets for LLM fine-tuning
The quality and diversity of your training dataset are crucial for developing effective anonymization models. Here are three approaches we’ve found successful:
1. Transforming Existing Datasets
– Utilize well-established datasets like CONLL (Conference on Natural Language Learning)
– Transform these datasets into question-answer pairs using capable models
– Use these pairs to train smaller, more specialized models for anonymization tasks
2. Large-scale Data Collection and Labeling
– Collect a substantial amount of diverse, real-world data
– Use a capable model to label this data for anonymization tasks
– This approach can capture a wide range of real-world scenarios and edge cases
3. Synthetic Dataset Generation
– Leverage powerful LLMs in combination with libraries like Mimesis and Faker
– Generate fully synthetic datasets that cover a broad spectrum of anonymization scenarios
– This method allows for the creation of large, diverse datasets without privacy concerns
All the mentioned approaches rely on using large, capable models for dataset generation. By doing this, we are in a way “distilling” the knowledge and capabilities from the large models into the smaller ones by providing specific training data.
Evaluation – not the easiest part
Evaluating the performance of a LLMs, regardless of fine-tuning, can seem like a complicated task. Unlike traditional models for token classification, which can be evaluated using automatized metrics such as accuracy and F1, LLMs must be evaluated with a combination of automatized and manual (human) evaluation.
If we decide to work with the rewrite approach, automatized evaluation can be achieved with another capable LLM which can be prompted to give us a score or some other type of evaluation. The other approach, which carries more weight and produces reliable results, is using human-in-the-loop assessments where experts can review the anonymized output and compare it to the initial text to make sure that it is free of personal data, but that it also contains all the relevant information.
It is also important to think about consistency across the outputs, as the LLMs are known to produce different results for very similar inputs, especially when dealing with small models. Edge cases, such as unusual names, foreign words or data formatted in unexpected way are often a place where models make most mistakes. We must make sure that evaluation data consists of as many as edge cases as possible, to minimize the chance that the model has a problem with a particular situation.
Conclusion
As LLM development continues to advance, we will undoubtedly see more use cases where these models replace traditional methods across various processes, and in some instances, even take over entire workflows. While LLMs offer a remarkable set of capabilities, it’s essential to consider other business factors beyond simply solving a specific problem. Scalability, cost, and performance are crucial aspects that need to be weighed carefully.
| LLM’s | Token-classification models | |
|---|---|---|
| Versatility | Can handle a wide range of tasks with minimal adjustments | Reliable, stable performance but may not match the latest advances |
| State-of-the-art performance | Can achieve cutting-edge results in many NLP tasks | Token-classification models |
| Cost | High computational and financial costs for training and inference | Generally, more cost-effective, especially at scale |
| Scalability and speed | Slower inference times, requiring large infrastructure | Faster inference, much smaller infrastructure requirements |
| Specialization | Can be overkill for simple tasks | Highly efficient and effective for specific, well-defined tasks |
In our experiments with anonymization, we’ve found that while LLMs are highly effective for the task, traditional methods still hold significant value. These methods often deliver faster results and are more cost-effective compared to LLMs. It’s vital to stay informed about new trends and experiment with emerging technologies, but it’s equally important to recognize that newer isn’t always better. Balancing innovation with practicality ensures that we choose the right tool for the job.



