

Building on that, we want to further improve data governance inside such pipeline because it enables us to quickly solve data related problems by setting internal standards on how to gather, store, validate and process data. Furthermore, we want this functionality to be inherent to the data pipeline so it cannot function outside the defined rules and agreements.
The answer to our problems can be found in the data contracts which are currently well known as part of the data mesh architecture.
Data governance with data contracts
Data governance is the process of managing availability, quality, integrity and security of data and it is based on agreed upon standards and policies. It usually also covers different roles and responsibilities.
The governance process can often be seen as just paperwork which makes data stakeholders not willing to always read and track every part of it. This is why it is preferable to make these standards and policies part of how the system works – to ensure that data important to us is of good quality.
Data contracts help us formally arrange our understanding of what the data quality, ownership, roles, and other fundamentals should be. Also, they are human readable (most often in YAML or JSON format) and can be implemented as part of a data system. Because of this they are an excellent choice for enforcing data governance rules and policies.
A data contract is a document that defines the structure, format, semantics, quality, and terms of use for exchanging data between a data provider and their consumers.
Data contract formatting standards
Standardization is important because it gives us a common language and enables easier interaction. Two of the more popular and recognized standards are the Open Data Contract Standard and the Data Contract Specification.
# Open Data Contract Standard # Fundamentals and demografics datasetDomain: generated data quantumName: Generated data in SCD2 format userConsumptionMode: Analytical version: 1.0.0 status: current uuid: 53581432-6c55-4ba2-a65f-72344a91553b description: purpose: Example data for Data Contract. # Getting support productDl: [email protected] productFeedbackUrl: https://test.webhook.office.com # Physical parts / GCP / BigQuery specific sourcePlatform: null sourceSystem: Example system datasetName: Generated example data type: tables # Physical access server: croz.example.server.hr database: dc-test # Tags tags: [example, test, generated] # Dataset, schema and quality dataset: - table: GeneratedSCD2TestTable physicalName: dc_generated_scd2 description: Generated dataset for testing purposes of data contract authoritativeDefinitions: - url: https://www.example_url.com/test type: businessDefinition tags: [TestTag] dataGranularity: Raw columns: - column: index isPrimary: true primaryKeyPosition: 1 businessName: Id logicalType: int physicalType: int isNullable: false description: Index of data in table. quality: code: IndexCheck condition: expect_column_values_to_be_unique('index') - column: gen_id isPrimary: false primaryKeyPosition: -1 businessName: Generated id logicalType: string physicalType: string isNullable: false description: Generated id of data. - column: created isPrimary: false primaryKeyPosition: -1 businessName: Creation date logicalType: string physicalType: string isNullable: false description: Date of creation. - column: word_sign isPrimary: false businessName: Word sign logicalType: string physicalType: string isNullable: false description: An example of a string. sampleValues: - word.E - column: number_sign isPrimary: false primaryKeyPosition: -1 businessName: Number sign logicalType: int physicalType: int isNullable: false description: An example of an integer. quality: code: NumberSignCheck condition: expect_column_values_to_be_between(column='number_sign', min_value=6, max_value=20) - column: confirmation isPrimary: false primaryKeyPosition: -1 businessName: Confirmation flag logicalType: bool physicalType: bool isNullable: true description: Generated confirmation flag quality: code: ConfirmationCheck condition: expect_column_to_exist('confirmation') - column: start_date isPrimary: false primaryKeyPosition: -1 businessName: SCD2 start date logicalType: timestamp physicalType: timestamp isNullable: false description: Date when data was inserted into SCD2 table. - column: end_date isPrimary: false primaryKeyPosition: -1 businessName: SCD2 end date logicalType: timestamp physicalType: timestamp isNullable: false description: Date when data was no longer valid. - column: is_active isPrimary: false primaryKeyPosition: -1 businessName: Is active logicalType: bool physicalType: bool isNullable: true description: Is it currently active data. quality: code: SlaTimeCode condition: expect_queried_column_value_frequency_to_meet_threshold(column='is_active', value=True, threshold=0.3) # Stakeholders stakeholders: - username: po role: Product Owner dateIn: 2024-01-01 email: [email protected] - username: ba role: Business Analyst dateIn: 2024-01-01 email: [email protected] - username: sm role: Solution Manager dateIn: 2024-01-01 email: [email protected] - username: do role: DataSet Owner dateIn: 2024-01-01 email: [email protected] - username: da role: Data/SW Architect dateIn: 2024-01-01 email: [email protected] - username: de role: Data/SW Engineer dateIn: 2024-01-01 email: [email protected] - username: ip role: Interested Party dateIn: 2024-01-01 email: [email protected] # SLA slaProperties: - property: generalAvailability value: 2022-05-12T09:30:10-08:00 - property: endOfSupport value: 2032-05-12T09:30:10-08:00 - property: endOfLife value: 2042-05-12T09:30:10-08:00
# Data Contract Specification
dataContractSpecification: 0.9.3
id: croz:datacontract:batch:scd2
info:
title: Generated Dataset
version: 1.0.0
description: |
Data contract for generated dataset stored in scd2 used for data contract.
owner: Data team
contact:
name: name
url: https://www.croz.net/test-url
servers:
postgres:
type: postgres
host: localhost
port: 65114
database: dc-batch-test
schema: public
terms:
usage: Used only for testing purposes.
limitations: Not suitable for production.
models:
dc_generated_scd2:
description: Data set in SCD2 format stored for data contract testing.
type: table
fields:
index:
description: index of data in table
required: true
unique: true
type: numeric
gen_id:
description: generated id of data
required: true
type: varchar
maxLength: 22
created:
description: date of creation
type: varchar
required: true
word_sign:
description: An example of a string.
type: varchar
minLength: 1
maxLength: 10
required: true
number_sign:
description: An example of an integer.
type: numeric
required: true
confirmation:
description: An example of a boolean.
type: boolean
start_date:
type: timestamp
required: true
end_date:
type: timestamp
required: true
is_active:
description: Is it currently active data.
type: boolean
quality:
type: SodaCL
specification:
checks for dc_generated_scd2:
- invalid_percent(is_active) <= 60:
valid values: [True]
How did we incorporate a data contract into a standard ELT pipeline?
The following example describes an Airflow DAG that implements the ELT pipeline shown in the image:
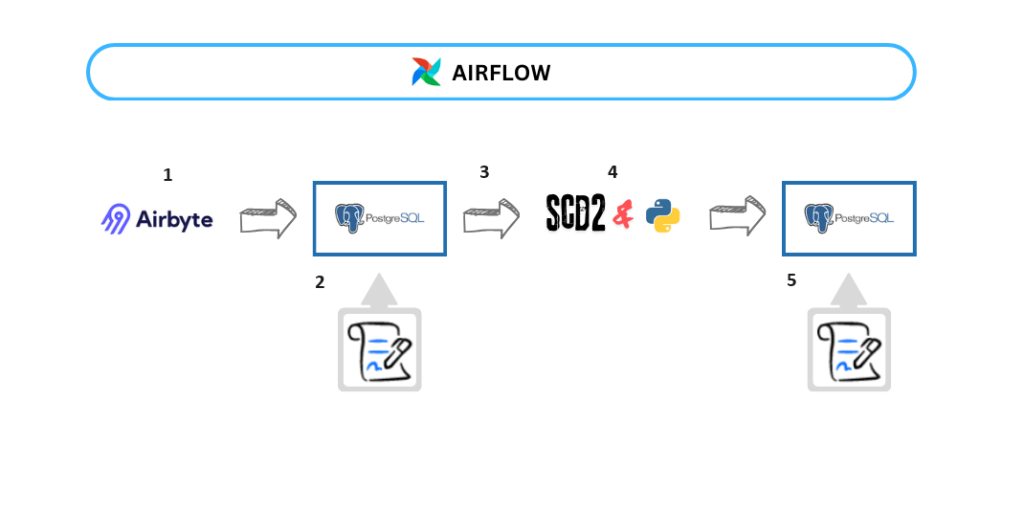
The DAG tasks are:
- airbyte_load_data: takes an Airbyte connection and starts a process of transferring data to the Postgres table. To run this task, it is necessary to add an Airbyte provider to Airflow project,
- dc_test_loaded_data: tests if data loaded by previous job into Postgres table adheres to the data contract,
- branch: if all the data contract tests run successfully, navigates the pipeline into the next phase, otherwise stops further execution,
- scd2_task: executes a Python script that stores data to a Postgres table in SCD2 format,
- dc_test_scd2_data: tests if data stored in SCD2 format adheres to the data contract.
We were trying to achieve good data quality and SLA satisfaction throughout the pipeline by using data contracts. To enforce rules defined in a contract, we created a reader class that implements these functionalities:
- reads data contract written as a YAML file into a Python program,
- provides all necessary data contract information,
- checks data for agreed-upon data quality,
- checks data for SLA,
- sends notifications about bad data to people responsible for it.
In our implementation we opted for ODCS in formatting a data contract. The quality rules and SLAs were written as expectations from the Great Expectations library and later used in code as an enforcement mechanism. Here is an example of such a rule:
quality:
code: NumberSignCheck
condition: expect_column_values_to_be_between(column='number_sign', min_value=6, max_value=20)
The decision to write rules as expectations was influenced by reflection that the contract will be written and used by data engineers in our company. If you would like to enable non-technical employees to be part of writing a contract, you can opt for a more human readable data quality rule language like SodaCL.
Registering data sources and data assets, executing expectations, and saving them to suit are part of different class methods and are an important part of our data contract implementation.
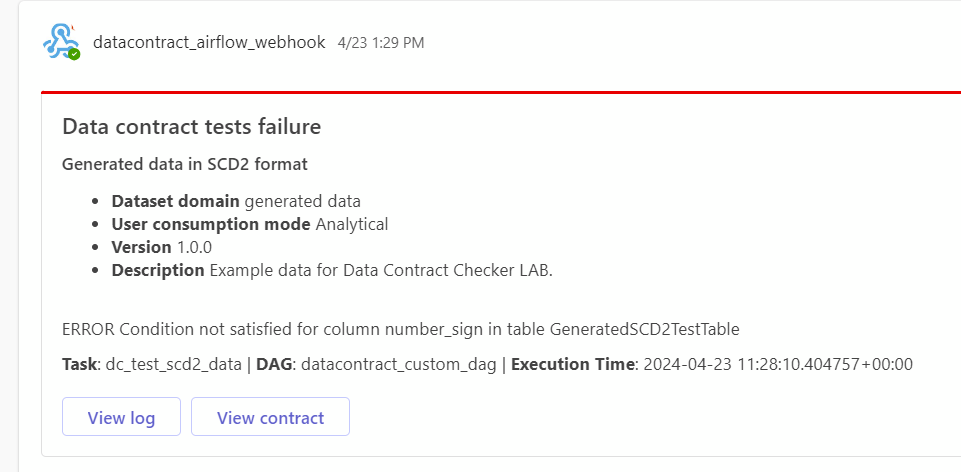
Notifications are sent via e-mails and Microsoft Teams webhook. E-mail sending is configured trough a Google server for which an App password is used.
def send_email(self, title: str, log_uri: str, additionalInformation: str = None, email_info: EmailInformation = None):
try:
if EmailInformation is None:
raise RuntimeError("ERROR No email information given.")
validate_email(email_info.sender)
for receiver in email_info.to:
validate_email(receiver)
htmlText = self._email_message_payload(title, log_uri, additionalInformation)
msg = MIMEText(htmlText, "html")
msg['Subject'] = email_info.subject
msg['From'] = email_info.sender
msg['To'] = ', '.join(email_info.to)
smtp_server = smtplib.SMTP_SSL(email_info.host, email_info.port)
smtp_server.login(email_info.username, email_info.password)
smtp_server.sendmail(email_info.sender, email_info.to, msg.as_string())
smtp_server.quit()
except EmailNotValidError as e:
print("ERROR sending email. Email not sent.", str(e))
Microsoft Teams webhook sends messages to a Teams channel. The message payload is formatted as message card through JSON formatting. The webhook URL is written in the productFeedbackUrl field of the ODCS data contract whose value provides the reader class.
def ms_teams_webhook_send_message(self, title: str = None, log_uri: str = None, additionalInformation: str = None):
if self.data_contract is None:
return None
json_payload = self._ms_teams_webhook_json_payload(title, log_uri, additionalInformation)
response = requests.post(
url=self.data_contract["productFeedbackUrl"],
headers={"Content-Type": "application/json"},
json=json_payload
)
return response.status_code
Data Contract CLI
The same example was also achieved using the Data Contract CLI. It is an open-source data contract implementation that came out of the Data Contract Specification. The CLI can be used in Python code (the way we use it), but it is more oriented towards usage in a terminal. Furthermore, it is agnostic towards surrounding technologies inside a data pipeline which we see as an advantage.
Data checks are performed in an Airflow task that uses CLI’s in-built methods. Quality rules can be written in multiple, human readable, specification languages among which we decided to use SodaCL. For a contract to be able to connect to a Postgres database you need to set the required environment variables for username and password. The check results are used to determine further task execution.
Contact information is gathered from the data contract specification (you can obtain it through a getter method of the DataContract class). Notification sending is not implemented by the client and it is achieved using a custom function for sending e-mails and an Airflow MS Teams callback function. This is the reason we emphasized the methods for sending notifications in the description of our implementation.
There are similarities between our solution and the CLI – both products can be used in a Python environment and are agnostic towards surrounding technologies, but also differences – contract standards and choices for quality rules specification languages.
The Data Contract CLI is a good implementation of a data contract, and it has a growing community. We intend to keep an eye on it in the future. More about it can be found here.
Conclusion
As you can see, a data contract is not just another piece of paper! It is a useful tool to carry out data governance, put order into a data system and ensure good data quality. The example we have given you shows that our custom data contract implementation, which is based on the ODCS, was successfully incorporated into an Airflow pipeline, and used for notifications about data inconsistent with the data contract.
We conclude that it is possible to easily incorporate data contracts into the existing data pipelines and ETL jobs and with it increase data quality, clearly determine data ownership, and contribute to the overall data governance.
In the next blog post we will talk more about data products, federated governance, and a data contract role in them.



