As we all know, serverless apps can scale app instances to zero when there is no incoming traffic. The problem is, when the traffic is restored, an application can take seconds or even tens of seconds to start (a term called cold starting). That makes the application unresponsive in the given time frame.
One solution proposed is using native compiling and distributing serverless functions as a native binary. It works, but we lose memory management and a lot of other cool stuff that JVM brings. Things like reflection, dynamic class loading, etc. But still, native compiling is good solution to make JVM apps start faster.
But what if there is a solution to reduce cold starting? What if we could have a “magic button” that would enable fast start-up for applications without changing anything in our typical Java coding workflow?
Against all odds, it appears that something like this is possible. It was just introduced by AWS at Re:invent 2023 and it is called “SnapStart”. We all know that behind magic there is always a lot of engineering work and smarts.
So, how SnapStart works?
Let me compare SnapStart to hibernation in operating systems. An OS function that most of us have used. When we want to save the state of applications we have opened, we choose to stand-by or hibernate the computer. At hibernation operating system saves the memory state (a snapshot) to hard disk drive. It is safe to turn off computer after that. Later, when we want to resume with work, operating system will check if there is a hibernation file. If there is a memory snapshot it will restore it’s content to memory (RAM). Then we can continue to work and all of our applications will still be running as we have left them.
This same approach takes SnapStart. The difference is that initial snapshot of the JVM memory is taken when a new version of Lambda function is deployed. So, all of that time-consuming work of loading classes, initializing objects is done on new function deployment. Once deployment is completed and initialization of the function is done, snapshot of the memory and disk state is taken. It is encrypted (for security) and put into cached storage (for improved read speed).
Once there is a need for a new instance of the Lambda function, snapshot is read from (fast) cache and restored. So, instead of doing initialization on cold start, Lambda (JVM) is restored (just as in hibernation). This is a-lot-faster. Like in milliseconds instead of seconds.
And all of this we get for free. Indeed, SnapOn is a completely free feature to enable on AWS Lambda functions. Where is the catch, there must be a catch?
Well, there are few things to consider. First SnapOn feature is only available on Java 11 runtime and in selected AWS locations. Also, in development, we must plan that application will be resumed and that if we need to maintain network connections, we can’t have them cached whilst application is starting up. The same is with temporary data. There are some other topics as randomness but nothing that is not already solved.
Let’s test this setting on.
Following article available in here, we can clone Git Hub Repo.
Using tool SAM, we can deploy application with SAM deploy command and curl the endpoint.
In our test timing curl command time curl https://<id>.execute-api.eu-west-1.amazonaws.com/pets we got response in 7.2 seconds for cold started Lambda function.
In Console we see the following report:
REPORT RequestId: e9d9490c-afbe-4ad6-af0c-56bd8d69cf6d Duration: 152.22 ms Billed Duration: 153 ms Memory Size: 1512 MB Max Memory Used: 171 MB Init Duration: 6075.89 ms
Now, imagine waiting for results on the page for more than 7 seconds. Most users would leave the page or try to refresh it in the mean time.
Not so good. Also, this is a simple application and results for JVM running large Spring Boot application would be almost always worse.
Response time is primarily affected by cold start, ie. initialization of the Lambda function.
After the cold start, we can see responses come with a response time of around 220 ms. Which is OK given there is about 50 ms in latency (package single way).
Let’s turn on SnapStart by adding the SnapStart block in the template.yml for the function.
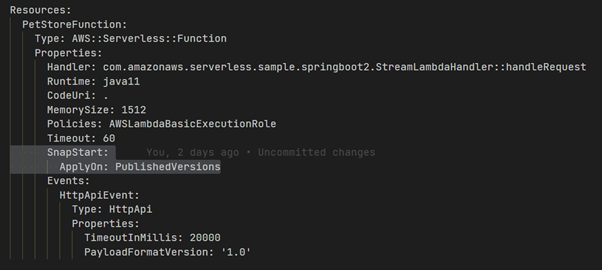
We deploy a new version using the SAM deploy.
But beware there is one Gotcha! Before using this feature, we need to make sure that we are invoking the function by using Qualified ARN.
To use qualified ARN first we need to create a new version of a function. We can do this in AWS Console UI or via CLI. With UI we can create a new version with the “Publish new version” button and give it an identifier such as 1.
Now that we have the version, we can go to the API Gateway page. At the page “API Gateway > Integrations > Edit” we must make sure that we are using the version in the Lambda Function ARN.
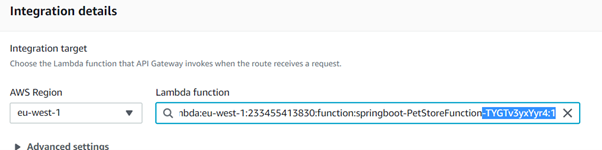
Now, with Qualified ARN , we can make the same timed curl call. We get the response in 1.351s.
In AWS Console we see the following report:
REPORT RequestId: 28079980-32a3-4f40-b85a-754f5e48b288 Duration: 280.56 ms Billed Duration: 468 ms Memory Size: 1512 MB Max Memory Used: 145 MB Restore Duration: 273.03 ms
If we compare the duration without the SnapOn feature (6 seconds) to one with the SnapOn (273 ms) we can see that startup time has decreased 22 times!
So, we can conclude that SnapOn feature is a gamechanger for a JVM serverless apps. For a lot of use-cases now we can write serverless JVM applications without resorting to native compilation. I’m sure that SnapOn feature has a bright future and that we will have opportunity to learn more about it as it matures.
For now, I wish you happy (serverless) coding!