Does this title seem right? How can you work more and spare time at once? At first, it seems as hot air, but you’ll see that it actually makes a lot of sense.
I will not quite yet discover what that extra work is. To begin with, let’s examine the following situations:
-
-
- My co-worker is leaving their job and I am inheriting their tasks
- I have to continue a half-finished task after several months pause
- There are many different short tasks I have to do tomorrow
- My co-worker is ill and I have to take over their task and finish it as soon as possible
- I am taking over maintenance and/or development of a project I haven’t been associated with before
-
These are not very pleasant circumstances. I must cope with long forgotten or half-done work. Here is one more detailed example: My colleague has been working on a data warehouse project. He has done analysis, data cleansing, dimensional model, and a portion of ETL jobs, but then he got ill, and I have to continue his work. The last ETL job he was doing is not finished and it is quite knotty. Several more ETL jobs and BI reports need to be developed and tested. Deadline for deployment to production is in ten days, and waiting for him to get better is too precarious.
What is necessary to resolve this without many difficulties and as fast as possible? It would be terrific if I were already familiar with the project, at least at high level, if there were specified rules for developing jobs and reports, if task progress were noted down, and if there were descriptions and explanations of complicated parts of jobs. In my case, all of the conditions are met, which makes this task trouble-free, less time-consuming and less stressful, and therefore – faster to bring to a close. Luckily, I work in a fantastic data engineering team in CROZ, which is, among many other outstanding qualities, always prepared for unexpected and sudden changes. How? By doing more. In this case, “more” means continuous agile documenting and knowledge transferring.
Writing documents isn’t really an engineer’s job description, but it is quite important and saves time in long term. Documenting your work doesn’t have to have an official form, but it must be accessible and readable to your team colleagues. Sometimes, comments inside your code are enough – a simple explanation of how a piece of logic works saves a great deal of time to someone who has to work on it afterwards. Tools for keeping track of projects that we find most effective and useful, are platforms for project planning, code management, and issue tracking, such as GitLab, Trac and Confluence. Beside repository, these applications provide issue boards where we can categorize and organize all our tasks. Writing short comments and updates on task progress requires a few minutes a day, but saves endless hours of decoding someone else’s job or report. Portion of time saved is significant, which is in most cases crucial for every project.
How do we do it?
The important thing is that project team comes to an agreement about the structure of documenting work. Which tool should be used, Trac or GitLab? How should we organize tasks on our issue board, by business area of a project or by an individual subtask? How should we comment our ETL jobs, in a job description area or each transformation individually? How should we name jobs and tables? There are many more questions to answer, but once there is a standardized method, keeping track becomes much simpler. There are no strict rules about this structure – each team should decide which methods suit them best.
What about details? What is the level of precision we should apply in our notes? Most of us would think the more detailed a description is, the easier it is to understand a task. The truth is, too many details are likely to suffocate us. Of course, not everyone has the same optimal level of exactitude, but the focus should be on enough. After all, we don’t need step by step instructions to do our job. So what does “enough” mean? To not let this become a philosophical matter, I’ll give an example from real life.
Our team works at client’s on several subprojects regarding data warehouse and data integration. There are several different business areas and source systems. It is a long-term project, which means it involves constant development and maintenance of the data warehouse system. We agreed on using GitLab for issue tracking, and decided to create a ticket for each subproject and source system separately. We created an issue board with four categories: open, to do, doing and done; as well as labels to mark issues by task status, business area and source system. Every issue must have a clearly specified name to be obvious which area of a project it relates to. It is also necessary to write a short description about what the requirement for the task is. Task progress should be simple and straightforward: notes about requirement analysis results, questions for customers and answers they provide, sketch of a data model, list of database, ETL objects and reports that need to be created, etc. If I develop several ETL jobs for testing some data, I should explain which data does each test concern, how does it work – is it an except test or it compares row count, and are there any problems developing it. I don’t have to describe every line of SQL code these jobs are based on. Too many notes make you reach for a highlighter – so write down only the things that should be highlighted!
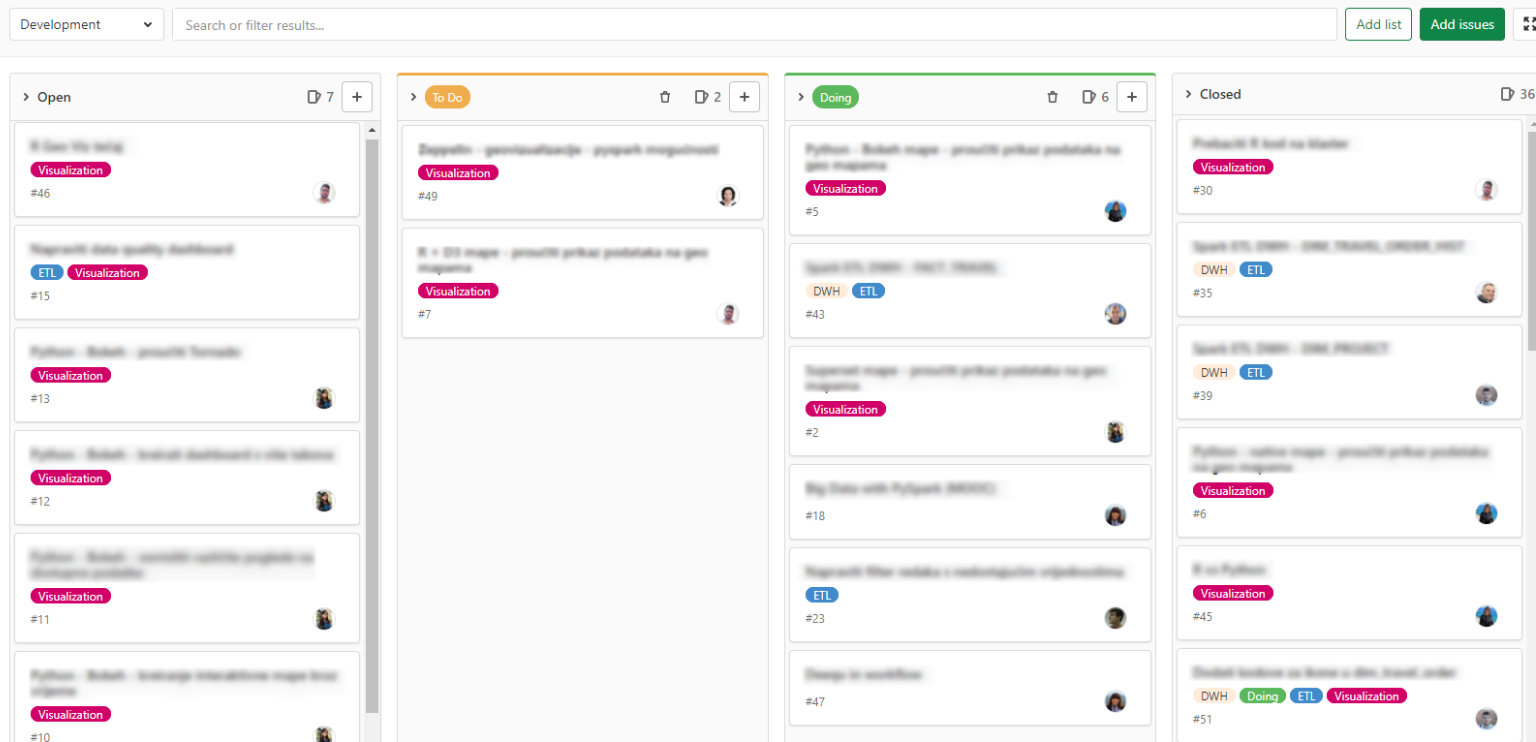
ETL tool used on the project is IBM DataStage. Great thing about DataStage is that you can use transformation objects (stages) called annotation and description annotation, designed for writing descriptions of a job or its parts. We use these stages to explain complicated parts of ETL, to logically separate parts of a job, or to emphasize parts of jobs that we should be careful about during testing or rollouts to another systems. Annotations should contain short notes and descriptions, such as shown in the figure below:
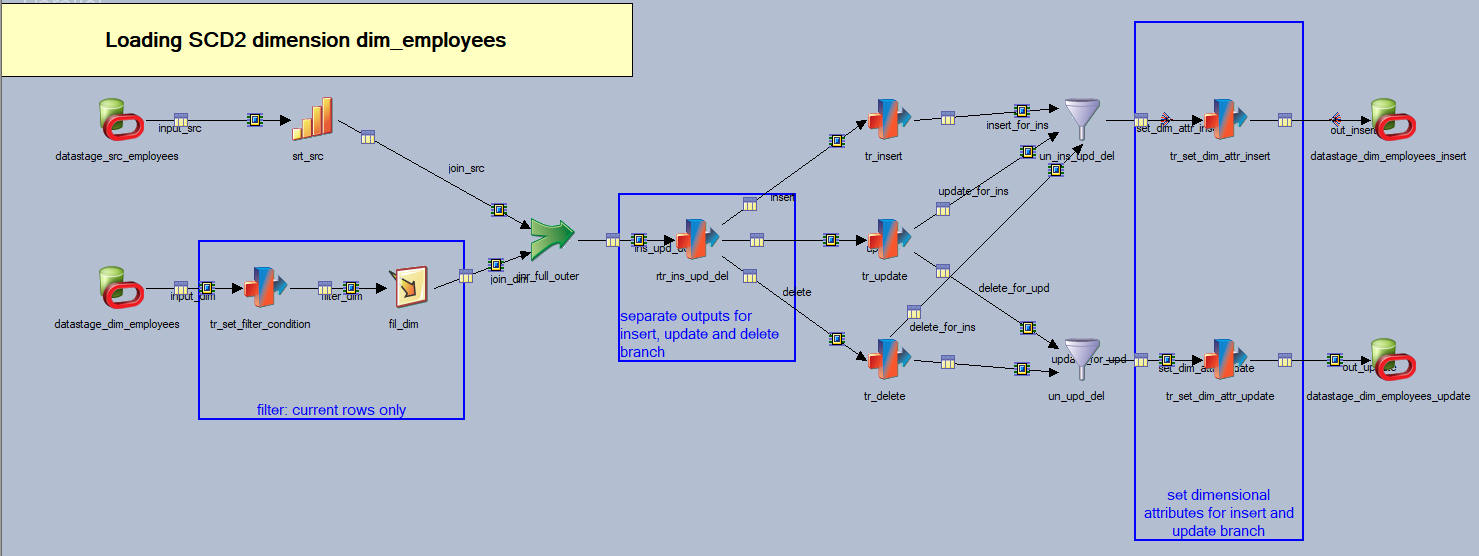
The job is explained in one short note that tells us what the job does. As you can see, all the stages and links have names that give us hints what the transformation’s about. There are three other annotations that concisely refer to logic inside framed stages. It’s not necessary to make annotation for every stage, for example source connector. The name of this connector shows which table is data read from, and that is enough. Describing connector properties is unnecessary and too much information. When ETL developer opens a job documented as this one, they know what it is about and where to look if it requires certain changes. We write these comments to a job as we develop it: it’s much faster to do it right away, than to recall our thoughts tomorrow. Not only this type of documentation eases comprehending a job, but it is simple to maintain and refresh, as well as to keep under version control.
If we look at the principles that describe agile development, we see that what we are talking about has a basis. Delivery, the code we write to, is more important to us than exhaustive documentation. Documentation is created within the framework required for delivery. It is a misinterpretation that in agile development documentation is not important. On the contrary, it is important, but not a primary delivery. With agile DW / BI development approach, we create documentation for the entire system, and focus on the most important and specific components.
What we definitely want to strive for is to have up-to-date documentation. How to achieve this? When developing new functionality as part of the sprint and agreed delivery, we will want to deliver valid and production-ready software support. The documentation falls into the background. Therefore, we should be guided by the principles of proper documentation of program code and ETL process, because by applying such a way of working we create a self-documenting DWH / BI system.
Documenting doesn’t have to be a toil. It can be fast and easy, yet extremely effective and useful. If team members communicate and make a note of their work on daily basis, the team is more productive, unleashed from irreplaceability, and headed for success.
Authors:
Jelena Lončarević
Stjepan Lukšić



