If you’re interested in receiving interviews with thought leaders and a digest of exciting ideas from the world of DevOps straight to your inbox, subscribe to our 0800-DEVOPS newsletter!
###
A couple of years ago we were in the middle of a huge project that required hefty processing capacity. We were relying on Red Hat OpenShift as a container platform (we still do :), and as capacity demand grew, we had to periodically add new worker nodes.
Adding new worker nodes was a breeze but more often than not our applications failed miserably on these new nodes for various reasons which all boiled down to something stupid like missing some configuration properties. Very soon it became clear to us that we needed a mechanism for establishing the Desired state. And that’s where the concept of Infrastructure as Code fits perfectly.
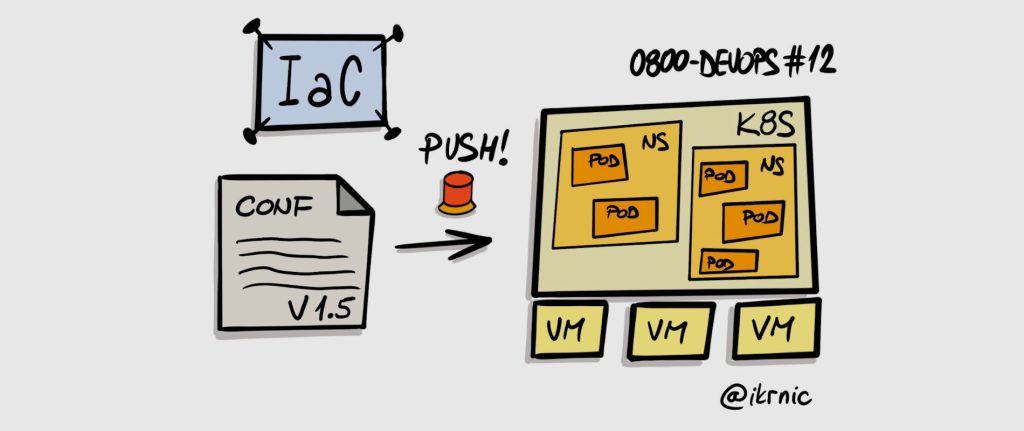
Infrastructure as Code is a mechanism for creating and maintaining runtime infrastructure based on a definition usually stored in a version control system.
The main idea here is that runtime infrastructure can be defined via machine-readable files that can be stored and versioned, much like regular source code. If you can build a specific application version based on the source code in a version control system, why wouldn’t you be able to do the same with your infrastructure – provision specific infrastructure based on the definition files in your version control system.
How we hit rock bottom…
Before Infrastructure as Code, our nodes (although meant to be identical) were rather unique because configuring nodes was a human task. With configuration documentation scattered over several Wikis and Word files, and humans not being shell scripts (therefore forgetting things), every now and then somebody dropped the ball and forgot to set some properties. In effect, our nodes ended up being snowflakes – each one very unique and with subtle configuration differences that were not visible to the naked eye, but nevertheless were causing our applications to fail on specific nodes… for no particular reason at all… at least it seemed so.
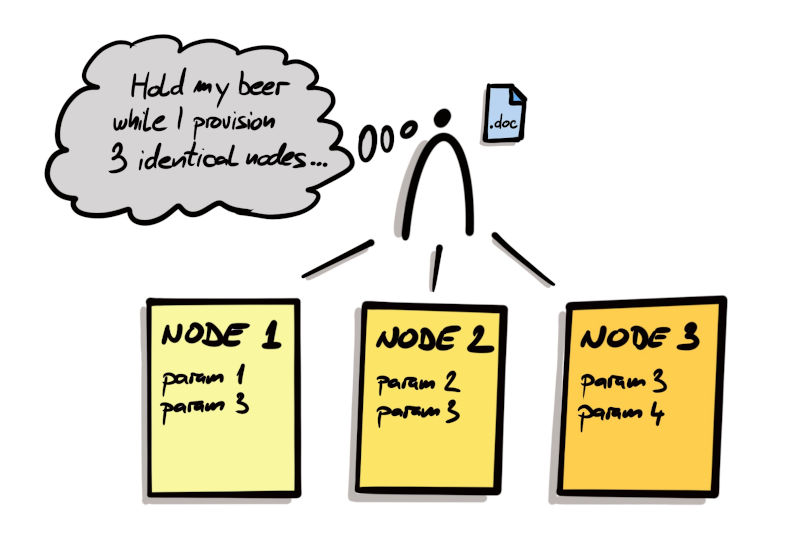
Manual server provisioning. Completely hypothetical situation. Never happened.
Infrastructure as Code takes care that infrastructure configuration is clearly defined in the version control system and consistently applied to infrastructure. Changes to infrastructure are done exclusively through pull requests in the version control system. Need additional CPU for your application? No worries, just make that change in the configuration file and make a pull request. When somebody approves a pull request, the change will be merged to trunk and the process will be initiated to provision new infrastructure configuration – new Desired state.
Cool IaC features
In order for Infrastructure as Code to work there has to be a way to fully automate tasks. This is where various tools come handy. Every public cloud has its own flavor: AWS CloudFormation, Azure Resource Manager and Google Cloud Deployment Manager, to name some. Other popular tools include Terraform, Ansible, and so on.
Additionally, automated tasks need to be idempotent which means that they can be executed multiple times with the same effect as they were executed only once. This ensures that complete configuration can be applied over and over again without fear of breaking something. Idempotent operations dramatically simplify implementation since we don’t need to take care of state (i.e. recording which changes/scripts were already executed and should be omitted from future execution).
Infrastructure as Code is such a powerful concept that enables us to add new cluster nodes that are identical to others as well as to create whole new environments that are the spitting image of the production. And when something goes terribly wrong, clusters can be automatically recreated with identical configuration as the old ones. Remember that analogy with pets and cattle? A proper restore-from-backup operation takes a lot of time. It’s usually easier and much faster to just drop the whole cluster and rebuild it from scratch. This is, to be honest, what we would do with full-fledged application servers and other heavy-weight runtime environments if we had a fast and reliable rebuild process.
And then GitOps came along…
Historically, Infrastructure as Code pattern dealt only with managing infrastructure in data centers, like servers and network parameters. But, two things happened in the meanwhile: Git became prevailing version control system, and second, with the rise of the cloud, an additional level of abstraction surfaced in the form of container orchestrator, most notably Kubernetes.
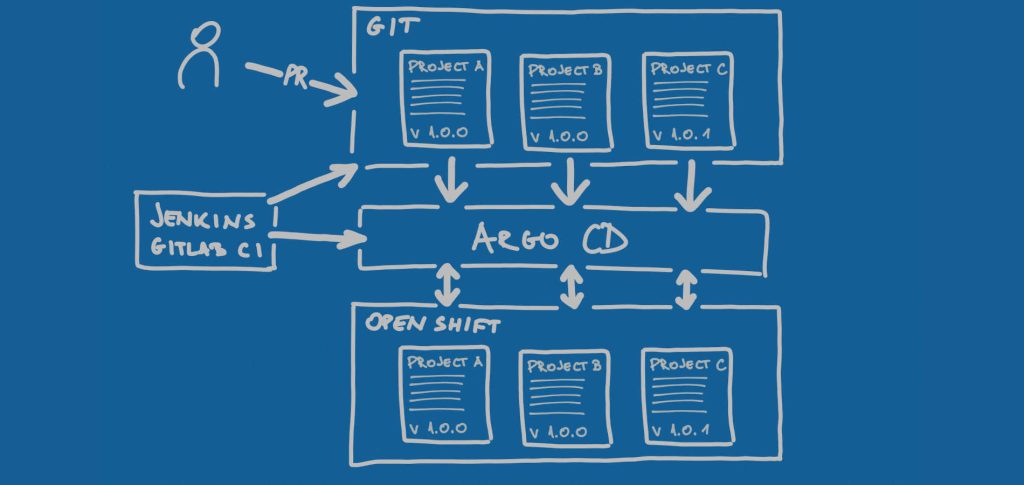
Since IaC was such a useful pattern, wouldn’t it be cool to extend it in a way that it uses Git as a version control system and manages not only underlying servers but also Kubernetes instance? And, voila, GitOps emerged.
Much like IaC is a pattern that manages infrastructure, GitOps is a pattern that manages Kubernetes instance and handles tasks such as setting namespaces, limits, and quotas, controlling the number of container instances and so on. As the name says, GitOps uses Git as a single source of truth for Kubernetes instance management. Being container- and cloud-native-aware, GitOps is ideal for modern architectures and modern technology stack. Using GitOps you can recreate your Kubernetes cluster, set up all namespaces, limits, and quotas, and redeploy all containers. On a push of the button, you can tear everything down and recreate an identical state as before.
IaC vs GitOps mess… #”$%$#
People often ask what is the difference between IaC and GitOps. It’s not an easy question. IaC is version control system agnostic. GitOps, on the other hand, uses only Git. IaC deals only with the underlying infrastructure. GitOps focuses on managing Kubernetes instance above. Does that mean that GitOps shouldn’t also manage infrastructure? No, why wouldn’t GitOps also manage infrastructure?
We can look at GitOps as “doing Ops” while using Git for storing configurations. Notice here how “doing Ops” is not limited only to managing servers or only to managing Kubernetes instance. We can look at it holistically as managing whatever it takes. In that sense, we can look at GitOps as a more specific implementation of IaC pattern.
Why you should seriously consider IaC and GitOps?
Infrastructure as Code and GitOps work best together! Benefits are huge:
- Speed, since installing and configuring Kubernetes instance can be automated.
- Consistency, since all instances are always built and configured using the same procedure and same input parameters.
- Audit, since all changes are done through configuration stored in a version control system it is easy to find out who did particular change.
- Traceability, again since all changes are done through configuration stored in a version control system it is easy to figure out how the system ended up in the current state.
- Self-service and developer-centric, since changes to infrastructure can be done even by developers… as opposed to only by Operations. On the other hand, we don’t want anarchy… that’s why we use pull requests that somebody needs to approve.
- Developers can develop (and later troubleshoot) in an environment identical to production. Developers love this.
- Feedback loops are shorter since QA can be done in an environment identical to production. Problems are caught before production.
- Performance and stress tests also make sense only when done in an environment identical to the production.
If you’re interested in receiving interviews with thought leaders and a digest of exciting ideas from the world of DevOps straight to your inbox, subscribe to our 0800-DEVOPS newsletter!
###