

The hype around artificial intelligence is present for some time now. Many products that we use daily are already leveraging machine learning to enhance existing products (e.g., personalized applications) or solve problems that were very hard to solve without machine learning (e.g., detecting objects on the road). On the other hand, in most enterprise companies, half of the machine learning projects never see the light of day in production. Typical reasons are poorly defined goals and lack of quality data, not having the right skills to proceed with building, integrating and automating ML systems into complex enterprise environments, or slow iteration cycles due to a high degree of manual and one-off work.
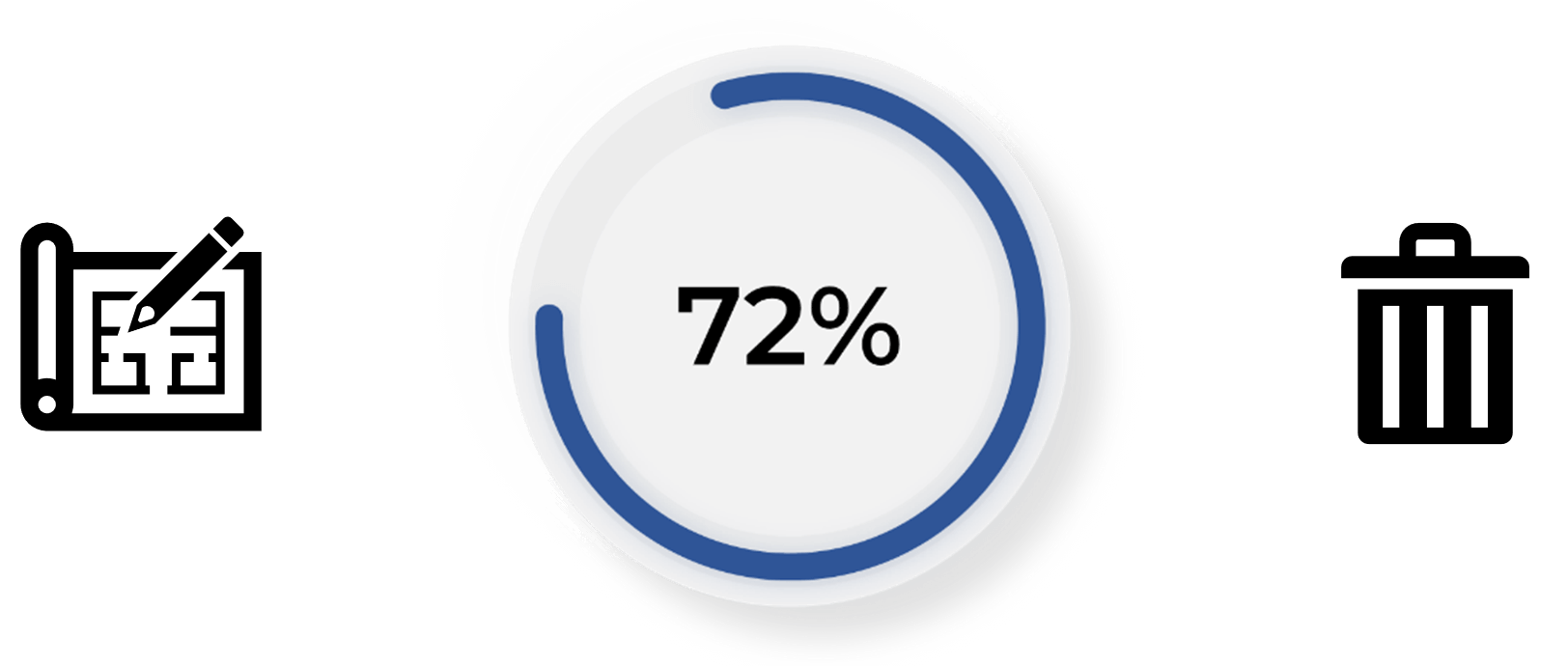
*72% of organizations that began AI pilots before 2019 have not been able to deploy even a single application in production
Parts of ML factory
Just like a regular factory that creates physical products, reliably at scale and speed, automating ML Factory should be used to create meaningful ML solutions for a business – reliably at scale and speed. Similar to the physical factories, ML factories also need materials, processes, and people to produce products.
Every ML factory is powered by data – the key raw material. And just like in a physical factory, we need to understand the whole supply chain of materials that we use. Understanding the quality of the data, available trusted sources, data security, or how and where to store the data – these are all the questions that need to be addressed before production begins. As with physical factories, some questions may require more planning depending on the industry or use case, but usually, there are a lot of blueprints that we can reuse on different projects.
Once raw materials are ready, we can start designing the process that will transform raw materials into a product. A typical machine learning project consists of multiple steps such as:
- Data acquisition, preparation and exploratory analysis
- Orchestrated ETL & Feature engineering
- Model training and tuning
- Model inference and serving
- Model monitoring and periodic retraining
As seen from the list, producing and automating ML products is a complex process that involves different engineering and business expertise. During this process, multiple different stakeholders are involved and are relying on each other – like Systems Architects, Business Stakeholders, Data Engineers, Data Scientists, or DevOps Engineers. Even though each ML product is different, machine learning projects usually involve all these activities and multidisciplinary teams are needed.
As companies are discovering more and more opportunities related to automating ML within their organizations, the need for building ML factories is increasing. Once the first iteration of the ML factory is built, the need for automation and a more streamlined machine learning process is increasing. And this is where Machine Learning Operations or MLOps comes in.
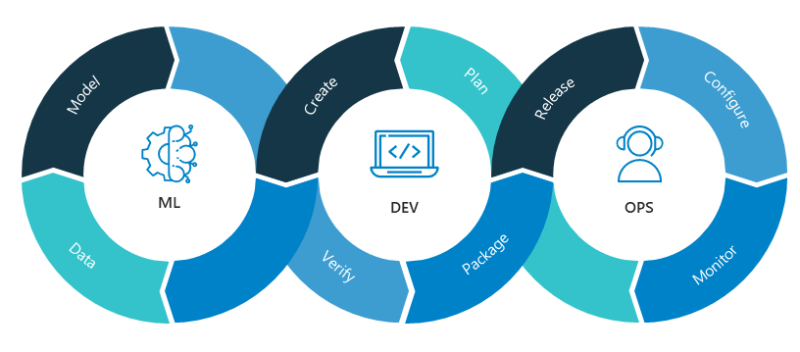
**MLOps combines machine learning, applications development and IT operations
MLOps is a core function of Machine Learning engineering, focused on streamlining the process of taking machine learning models to production and then maintaining and monitoring them. It can also be seen as the extension of DevOps methodology to include machine learning and data science assets as a first-class citizen within the standard CI/CD practices of the organization. MLOps, like DevOps, grew out of the realization that separating ML model development from the process that delivers it – ML operations – reduces the quality, transparency, and agility of all intelligent software.
Automating ML factory
Once we know which task we are solving, what data we can use, and what is the key evaluation metric, we can start with experimentation and prototyping.
To train the first models, a dataset with features is needed. Datasets can be large, and they can contain features that might be expensive to calculate for every experiment, so we usually store them in a feature repository. Experimentation is an iterative process, so the key success aspects are experiment tracking, reproducibility and collaboration. Data scientists need to try different models and configurations, compare evaluation metrics of different experiments, and understand the factors that lead to changes in the model’s predictive behavior.
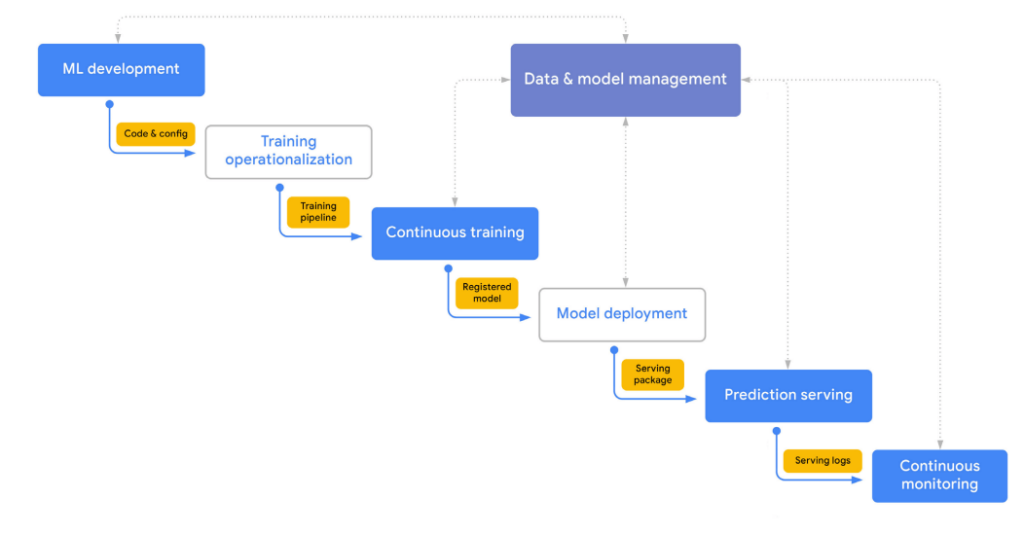
***A high level overview of MLOPS process
Usually, our ML factory needs to produce ML products that adapt to changes in the data, so models need to be retrained periodically. In this case, the factory needs to have an implementation of continuous training pipeline that can be periodically turned on. All building blocks of such pipelines, like development artifacts, data versions, source code and configurations, should be version-controlled to allows for building of a CI/CD workflow.
Once the model is trained and added to the model registry, it is ready for deployment. The deployed model serves predictions and produces serving logs so we can monitor ML service and measure data drift. Continuous monitoring is an important step, as it can trigger model retraining in case the performance of the model starts to degrade.
How to effectively implement MLOps practices?
Building a scalable and automatized ML factory is not an easy task. To effectively implement key MLOps practices, organizations need to establish a set of core technical capabilities. These capabilities can be provided by a single integrated ML platform or a combination of tools best suited for a particular task.
Building on top of CROZ’s general experience in DevOps and automation, CROZ AI can help clients design and build MLOps practices for their specific projects and needs. If you’d like to find out more about how to build or upgrade your ML factory, let’s get in touch.


