Part 2: Implementation, Results and Business Value
Welcome to the second part of our exploration of how fine-tuning Large Language Models with QLoRA can revolutionize document processing. In Part 1, we covered the foundational concepts of LLMs, the innovative QLoRA approach, and our comprehensive benchmark dataset creation.
Now, we’ll dive into the practical aspects: the technical implementation, the impressive results we achieved, and the significant business value this approach delivers. We’ll also discuss challenges, limitations, and key insights from our experience.
Technical Implementation
In this section, we’ll examine the implementation approach for fine-tuning large language models using Unsloth, a library that significantly improves training efficiency without compromising performance.
Configuration Setup
A key design decision was to separate configuration from implementation code. Rather than embedding parameters within the codebase, we centralized all settings in a structured YAML configuration file:
config_path = "config.yaml"
with open(config_path, "r") as f:
docs = list(yaml.safe_load_all(f))
config = docs[0]
This approach is quite effective for experimentation. When you want to try different learning rates or batch sizes, you simply update the YAML file, no need to modify the code itself.
Getting Our Data Ready
Next up is our data loader. This is a straightforward function designed to load the ChatML files:
import glob
from datasets import Dataset
def load_chatml_dataset(path_pattern: str)-> Dataset:
txt_files = sorted(glob.glob(path_pattern))
examples = []
for fpath in txt_files:
with open(fpath, "r", encoding="utf-8") as fh:
examples.append({"text": fh.read()})
return Dataset.from_list(examples)
In our config, we simply point to where our data lives:
data:
train_pattern: "/your/path/train/.txt"
eval_pattern: "/your/path/validate/.txt"
test_pattern: "/your/path/test/*.txt"
Loading Our Model with Unsloth
Here’s where the significant improvements begin. Unsloth enables efficient loading of large models with manageable GPU memory requirements:
from unsloth import FastLanguageModel, is_bfloat16_supported
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=config["model"]["name"],
max_seq_length=config["defaults"]["max_seq_length"],
dtype=config["defaults"]["dtype"],
load_in_4bit=config["defaults"]["load_in_4bit"],
device_map={"": f"cuda:{cuda_device}"},
)
Our config simply tells it what model to use and how to load it:
defaults:
max_seq_length: 8192
dtype: null
load_in_4bit: true
model:
name: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
Setting Up LoRA for Parameter-Efficient Fine-Tuning
Now for the coolest part – LoRA. This technique allows us to fine-tune a 7B parameter model with reasonable computational resources.
lora_cfg = config["lora"]
model = FastLanguageModel.get_peft_model(
model,
r=lora_cfg["r"],
target_modules=lora_cfg["target_modules"],
lora_alpha=lora_cfg["lora_alpha"],
lora_dropout=lora_cfg["lora_dropout"],
bias=lora_cfg["bias"],
use_gradient_checkpointing=lora_cfg["use_gradient_checkpointing"],
random_state=lora_cfg["random_state"],
use_rslora=lora_cfg["use_rslora"],
loftq_config=lora_cfg["loftq_config"],
)
The LoRA config is a bit detailed, but basically we’re telling it which layers to fine-tune:
lora:
r: 16
target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
lora_alpha: 16
lora_dropout: 0
bias: "none"
use_gradient_checkpointing: "unsloth"
random_state: 3407
use_rslora: false
loftq_config: null
Putting It All Together
Finally, we setup the training process:
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
train_dataset = load_chatml_dataset(config["data"]["train_pattern"])
eval_dataset = load_chatml_dataset(config["data"]["eval_pattern"])
tf_args = config["training_args"].copy()
tf_args["fp16"] = not is_bfloat16_supported()
tf_args["bf16"] = is_bfloat16_supported()
training_args = TrainingArguments(**tf_args)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text",
max_seq_length=config["defaults"]["max_seq_length"],
dataset_num_proc=2,
packing=False,
args=training_args,
)
trainer.train()
output_dir = config["output"]["model_dir"]
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
Our training config gives us fine control over the whole process:
training_args:
per_device_train_batch_size: 5
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 10000
learning_rate: 0.0002
logging_steps: 1
logging_dir: "runs"
optim: "adamw_8bit"
weight_decay: 0.01
lr_scheduler_type: "linear"
seed: 3407
output_dir: "outputs"
report_to:
- "tensorboard"
eval_strategy: "steps"
eval_steps: 100
save_strategy: "steps"
save_steps: 100
output:
model_dir: "final_model"
Why This Approach Works So Well
A few key takeaways from our implementation:
- Configuration-First: Keeping everything in a YAML file makes experimentation more systematic.
- Memory Efficiency: The combination of 4-bit quantization and LoRA significantly reduces GPU memory requirements.
- Precision Flexibility: The code automatically selects the optimal precision for the available hardware.
- Regular Checkpoints: We implement frequent model saving to preserve training progress. An important advantage is that this approach doesn’t require specialized hardware. A standard consumer GPU can effectively run this pipeline, thanks to the implemented optimizations.
Impressive Results and Performance Gains
Let’s examine the results of our approach. The performance improvements were substantial when we put our fine-tuned model to the test.
How We Measured Success
Our evaluation approach recognized that document extraction has inherent complexity, some fields require exact matches (like invoice numbers), while others can tolerate slight variations (like addresses). We developed a specialized evaluation system:
- For strict fields like IDs, dates, and money amounts, we required perfect matches (after normalizing formats).
- For text fields, we used a Levenshtein ratio to handle minor variations.
- Before comparing anything, we normalized everything: stripped currency symbols, standardized dates, and cleaned up white space.
- We weighted each document’s fields equally, so one complex document wouldn’t skew our results.
The Quantitative Results
Comparing our fine-tuned model to the original revealed significant improvements:
- The average accuracy increased from 0.40 to 0.81 (representing a 102% improvement).
- The median accuracy improved from approximately 0.40 to 0.92, indicating consistently high performance across most documents.
- The distribution pattern shifted dramatically. The original model showed widely dispersed accuracy, while our fine tuned version clustered most results at the high end of the scale (above 0.75).
- Statistical validation through Welch’s t-test produced a p-value of effectively zero (p < 0.0001), confirming the statistical significance of these improvements.
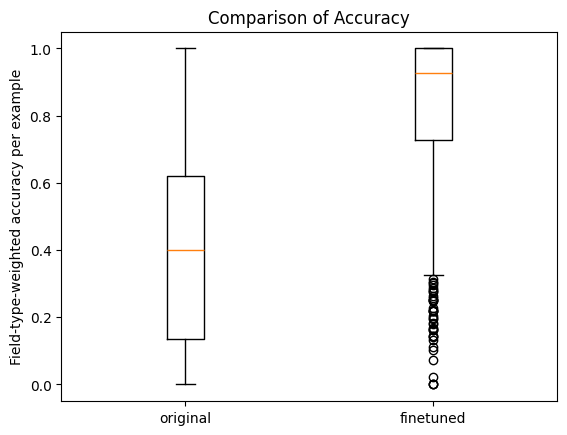
Comparison of field-type-weighted accuracy before and after fine-tuning. The box plots show median (orange line), interquartile range (box), and distribution (whiskers and outliers). The fine-tuned model demonstrates substantially higher and more consistent accuracy across the test dataset.
The box plots visually demonstrate this transformation. The dramatic upward shift represents a substantial reduction in documents requiring manual correction.
Efficient Model Size with Strong Performance
A notable additional benefit: while the base Mistral-7B model requires approximately 4GB in its quantized form, our LoRA adapter weights occupy only 240MB, a 16:1 compression ratio. This efficiency has practical deployment advantages. The model can be implemented across diverse environments without extensive infrastructure requirements, from edge devices to lightweight cloud instances, or alongside other applications with minimal resource competition. The combination of substantially improved accuracy and compact deployment footprint makes this approach particularly practical for production environments.
Practical Considerations
Business Applications
Having established the technical performance of our approach, let’s examine how it translates to practical business applications:
- Invoice Processing: Automates extraction of vendor information, dates, amounts, and line items from diverse invoice formats, allowing accounts payable teams to focus on exception handling rather than manual data entry.
- Insurance Claims: Reduces processing time from days to minutes by efficiently extracting relevant information from medical records, incident reports, and policy documents, accelerating assessment while maintaining accuracy.
- Contract Analysis: Automatically identifies key terms, dates, parties, and obligations from agreements, eliminating time-consuming information gathering while complementing (not replacing) legal expertise.
- Customer Onboarding: Streamlines KYC processes by efficiently extracting and verifying information from identity documents and proof of address, reducing onboarding time while maintaining regulatory compliance.
Challenges and Limitations
While our approach offers substantial benefits, it’s important to acknowledge several challenges:
- Quality of OCR Input: The extraction accuracy remains dependent on OCR quality. Poor-quality scans, handwritten notes, or unusual fonts can significantly impact performance.
- Handling Novel Document Types: Despite improvements, the model can still struggle with document formats dramatically different from those in the training data. Periodic retraining with expanded datasets remains necessary.
- Complex Multi-page Documents: Performance tends to decrease with very long or complex multi-page documents that exceed context window limitations.
- Maintaining Privacy Compliance: When fine-tuning with sensitive documents, ensuring GDPR and similar regulatory compliance adds implementation complexity.
- Version Management: As base models evolve, determining when to upgrade and retrain adapters requires careful consideration of performance benefits versus stability.
- Integration Challenges: While the model itself is efficient, integrating it into legacy document management systems often requires additional engineering effort.
These challenges highlight that while our QLoRA fine-tuned approach significantly advances document processing capabilities, it represents a step in an evolving journey rather than a complete solution. Organizations implementing this technology should plan for continuous improvement cycles as both the underlying models and fine-tuning techniques advance.
Conclusion and Key Insights
Key Achievements
Through this implementation, we’ve achieved several significant outcomes:
- Transformed document processing from error-prone manual work to highly accurate automation.
- Accomplished this with modest computing resources rather than specialized infrastructure.
- Created a solution with compact adapter files suitable for diverse deployment scenarios.
- Developed an approach that adapts effectively to new document formats without extensive
reconfiguration.
This represents more than an incremental improvement to traditional document processing, it introduces a fundamentally different approach with superior scaling characteristics and complexity handling.
Valuable Insights
This project has yielded several noteworthy lessons:
- QLoRA effectively democratizes AI fine-tuning, making it accessible with standard com
puting resources. - Separation of configuration from code substantially improves the experimentation workflow.
- Well-structured training data produces superior fine-tuning outcomes.
- Standard GPU hardware with moderate VRAM is sufficient for excellent results.
- Optimization libraries like Unsloth significantly enhance training efficiency.
These techniques go far beyond just document processing—they show how LLMs and QLoRA can be practically applied to a wide range of specialized language tasks, enabling powerful domain adaptation even within tight resource limits. So there you have it; a practical guide to supercharging document processing with LLMs and QLoRA. I hope you found this two-part series useful for your own projects!