Artificial intelligence (AI) is moving fast, and the biggest challenge for many isn’t just building models, it’s quickly testing, refining, and putting AI to work in day-to-day business. Traditional AI projects often require heavy coding and infrastructure, which can slow down innovation or keep teams from experimenting at all.
Platforms like n8n can help us in rapid testing and experimenting. For business users, consultants, and business analysts (BAs), n8n is particularly valuable: it offers a low-code/no-code approach that makes advanced AI concepts accessible, even if you aren’t a full-time developer. This opens the door for business users and citizen developers to quickly prototype ideas, automate tasks, and try out AI use cases without waiting for IT resources.
Why n8n? Low-Code, High Flexibility
AI Workflow automation platforms let you visually design workflows that connect data sources, APIs, AI models, and business processes, with minimal or no code. This means you can quickly build and iterate on ideas, whether you’re processing documents, building chatbots, or generating content.
Plus, n8n is based on the fair-code model and can be self-hosted, giving you extra control over integrations and data privacy.
Let’s see how you can try common AI tasks, like search, analysis, summarization, and Q&A on documents – using n8n workflows.
Building a RAG agent in n8n
Most AI workflows begin with the same challenge: handling large amounts of information. For example, building a chatbot on a big knowledge base can lead to context limits, irrelevant answers, or so-called “hallucinations.”
A common solution is Retrieval-Augmented Generation (RAG). In RAG, you split documents into smaller chunks, turn those chunks into numeric vectors (embeddings) that capture their meaning, and store them in a vector database for fast, meaning-based search. When a question arrives, the system finds the most relevant chunks and uses an AI model to generate an answer from those exact facts.
Here’s how we can use n8n to quickly build and test a simple RAG app.
Document Chunking
Large language models have limits on input size, so they can’t process very long texts all at once. To handle this, you split documents into smaller “chunks.” n8n provides built-in tools for this. For example:
- Fixed-size splitting: Break documents into equal-sized segments (e.g., 2000 characters each), using Character Text Splitter node.
- Recursive splitting: Split document data recursively while trying to keep sentences and paragraphs together, using Recursive Character Text Splitter node.
Text Embedding
After chunking, convert each piece of text into an embedding: a numeric vector that captures its meaning. This makes the text searchable by meaning, not just keywords. n8n can call different models to create embeddings:
- OpenAI Embeddings: Well-supported and reliable for general business documents and multiple languages.
- Google Gemini Embeddings: Good for specialized use cases, especially when you need support for particular languages or domains.
- Hugging Face Embeddings: By using the Hugging Face Inference node, you can choose from a wide variety of open-source models, allowing you to tailor embeddings to your specific needs, including industry-focused or multilingual models.

Embedding Models Supported by n8n
Note: If your content is very technical or in a niche language, try multiple embedding models to see which works best.
Vector Database Integration
Once you have embeddings, you need to store them in a specialized database for fast similarity search – a vector database. Pinecone, MongoDB, Qdrant, PGVector are all supported out-of-the-box in n8n.
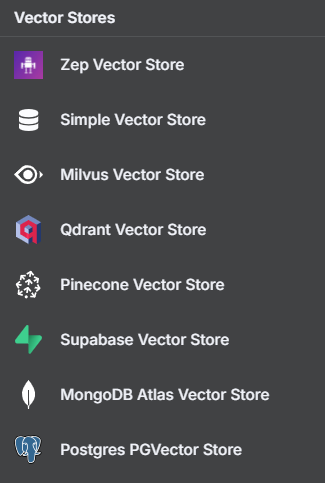
Vector Stores Supported by n8n
Workflow Example: You can set up a workflow to monitor a Google Drive folder for new files, automatically chunk and embed each document, and update your vector database. This way, your knowledge base updates itself with each new file.
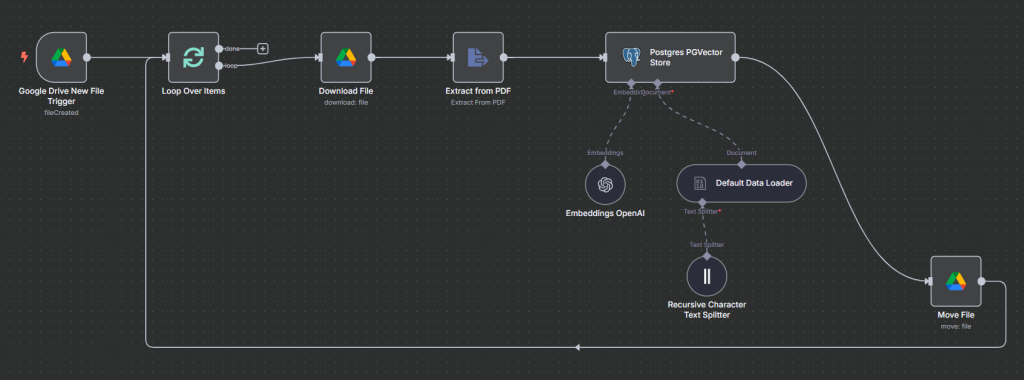
Document Chunking Workflow Example
From Retrieval to Answers: RAG Workflow
Now that we’ve prepared our documents and stored their data in a vector database, we can move on to the next step – building an AI agent that searches and retrieves the most relevant information whenever you need it.
Here’s what you need to build a simple RAG workflow in n8n:
- A vector database: Stores your document embeddings and allows you to fetch the most relevant chunks of information in response to a user’s question.
- Embedding model: You’ll use the same model you used to create the document embeddings. This ensures that the search for relevant information works correctly, as the “language” of the vectors needs to match.
- Vector Store Retriever: Searches the vector database for the document chunks most similar to the question being asked.
- Chat model (LLM): Takes the retrieved information and uses it as context to generate a clear, helpful answer for the user.
With these building blocks, you can create an AI agent that responds to business questions based on your own documents, not just generic LLM knowledge.
Important: Always use the same embedding model for retrieving data as you used for vectorizing the data. Mixing models can lead to inconsistent search results.
Workflow Example: You can set up a workflow to monitor incoming emails, automatically analyze the sender’s intent, and if the email is a request for specific information, activate an AI agent. The agent searches your vector database and retrieves the most relevant answer to send back.
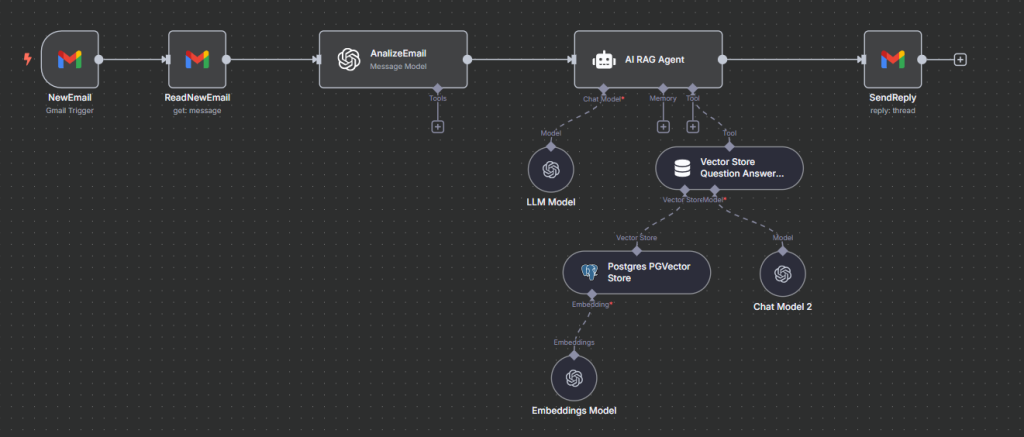
RAG Agent Workflow Example
Other AI Use Cases
n8n’s AI features let you automate a wide range of tasks.
Sentiment Analysis
You can automatically monitor input channels (like social media, emails, chats or support tickets) for sentiment. For example:
- Flag and escalate negative customer reviews.
- Track brand sentiment over time.
- Prioritize urgent support requests.
Here’s what you need to build a simple sentiment analysis workflow in n8n:
- LLM node to analyze sentiment: Processes incoming text (such as emails, support tickets, or social media messages) and determines whether the sentiment is positive, neutral, or negative.
- A switch node: Routes the workflow down different branches – one for “angry” or negative sentiment, another for calm or neutral/positive sentiment.
- A second LLM node to generate escalation details: If the sentiment is negative, this node prepares a clear, business-ready summary or recommended action to be attached to the escalation ticket.
- A ticketing system node: Takes the escalation details and creates a new ticket in your helpdesk or incident management system, ensuring urgent cases get prompt attention.
Workflow Example: You can set up a workflow that triggers whenever a new email arrives. The workflow analyzes the sentiment of the email using an LLM node. If the message is identified as angry or negative, the workflow prepares a summary of the user’s concern and automatically creates a GitLab ticket for escalation, ensuring that urgent cases are handled promptly.
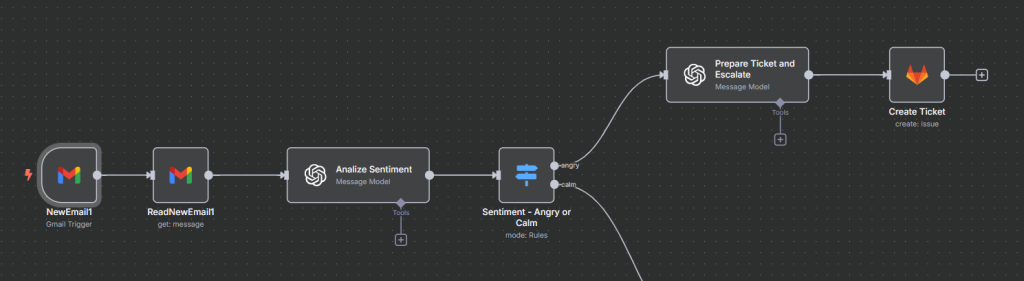
Sentiment Agent Workflow Example
Other AI-Powered Use Cases
In similar fashion, you can use n8n to experiment with use cases like:
- Content generation: create drafts for blog posts or social media from trending topics.
- Summarization: automate meeting notes or report summaries with LLMs.
- Data classification: sort incoming documents or emails into categories (spam, priority, etc.).
- Sales enablement: score or prioritize leads using AI-based scoring.
- Media analysis: integrate AI for image or video analysis (e.g., OCR, object recognition).
- Predictive analytics: connect to ML models for forecasting tasks (customer churn, maintenance needs, etc.).
How to Get Started
- Pick a simple use case: For example, chunking and embedding documents.
- Build the workflow: Use n8n’s visual editor to connect a data source, a text splitter node, an embedding node, and a vector store.
- Test different settings: Experiment with different chunk sizes and embedding models; see how the results change.
- Add retrieval and AI nodes: Build a mini RAG chatbot, and test queries on your data.
- Iterate and expand: Once you’re comfortable, try adding more steps like content generation, sentiment analysis, routing steps or other integrations.
Resource tip: Check the n8n documentation and community templates for examples you can adapt.
Key Takeaways
- No-code AI: n8n makes AI workflow automation accessible for business users and citizen developers – no advanced coding or expensive software required.
- Data prep is key: Breaking documents into parts, creating embeddings, and storing them in a vector database are essential steps for building practical tools like chatbots and smarter search systems.
- Integrate with existing tools: n8n connects easily with the platforms you already use including CRMs, ERPs, databases, helpdesk tools, and cloud storage, making it simple to integrate AI into your daily business processes.
- Prototype: The AI automation platforms work for full-scale solutions but also for fast prototypes. Self-hosting gives you extra flexibility and control.
- Learn by doing: Hands-on experimentation is the best way to learn. Start with small projects, see what works, and build up from there.
Conclusion
In my experience, using a tool like n8n can dramatically shorten the path from an AI idea to a working prototype. It’s quick to set up and lets you focus on the concept instead of infrastructure.
Whether you’re a developer or a business analyst, you can build powerful, AI-driven workflow, today.
If you’re looking to automate, prototype, or just experiment with AI, I recommend giving n8n (or a similar tool) a try.