

Breaking a monolith is very easy. Easy as 1-2-3 or in our case as 1-2-3-4-5.
Here are the 5 steps you need to make in order to succeed, as learned from our latest complex project:
1. Identify all logical subsystems
2. Find out which subsystem is owner of what data
3. Expose access to data trough service based (API) operations
4. Establish API governance
5. Introduce orchestration layer between new applications and legacy monolith APIs
And there you are – you are now ready to start breaking the monolith!
If only it were that easy, I hear you say and I know how you feel so read on if you’d like to hear about CROZ’s recent experience of modernising existing IT system.
We did it by developing several new UIs for existing system capabilities and developing new applications to enable support for some new business processes on top of existing services.
Learn more how CROZ can help you overcome your System Integrations challenges.
Do not break anything!
The IT system we were to extend and modernise was not a small bite to chew. The core of the system was developed during the early 1990s on top of IBM Mainframe (z/OS) platform. Since then the whole system has gone through countless changes driven by technological advances (in lesser extent) and ever evolving rapid business changes.
While it solved some issues, each and every change brought some new ones. Something had to be done in order to preserve system ability to provide services to organisation and adapt to changes in a more rapid way.
It became quite obvious very early that we needed to build new application and services on top of existing subsystems because everything was connected to everything else in the most creative way imaginable.
Changing one part meant changing something else and nobody wanted to throw away 20+ years of institutional knowledge encoded into the system in order to do a total rewrite (nor did we have the budget ). So we opted to build layer(s) of indirection between new applications we were adding and existing code. Henceforth The Bus was born. (Important sidenote! Not to be confused with ESB concepts from previous decade.)
API Centric Approach
Initial talks with stakeholders responsible for existing system revealed that we need structured information on who owns which piece of IT system and what business data are managed within it.
Since the system was basically one big database there was already in place a system of logical division into business units. What didn’t exist in a sufficient matter was distinction between public and private subsystem data. Essentially most of integrations between systems were done on a data layer directly through database.
So first key decision was that new application will be integrated using service based approach. Especially we proclaimed that each application (read subsystem) is responsible for its own data and none is allowed to mess with it in any way excepts subsystems itself.
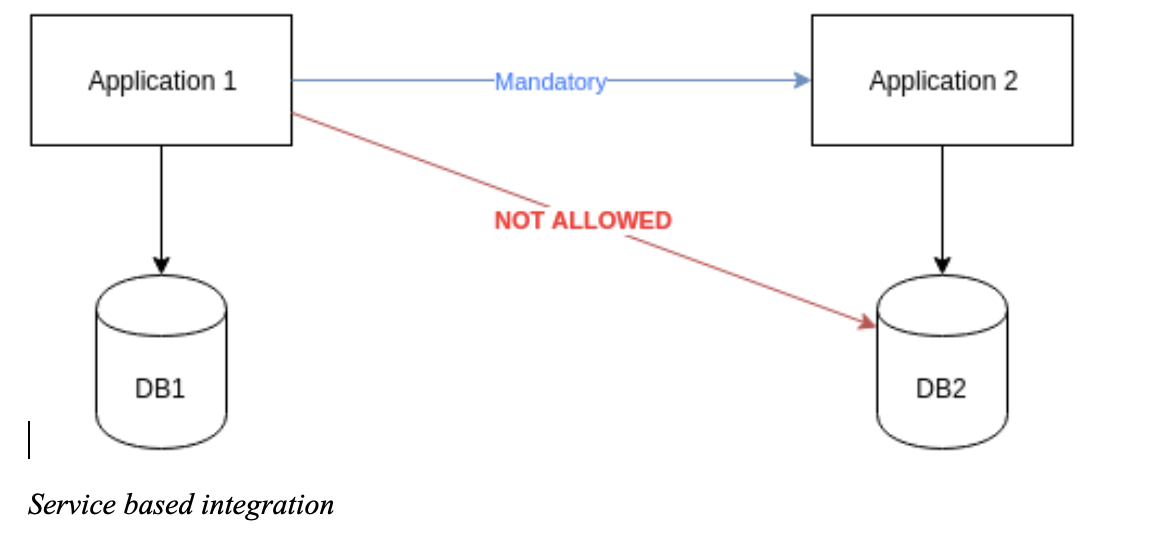
Service based integration
That way internal data models are decoupled from service(integration) interfaces.
Although client started developing REST and SOAP services for some parts of the system the core (read mainframe applications) was still only accessible through CICS, CTG (CICS Transaction Gateway) and/or direct DB access (JDBC). For new applications it was a good fit to build and expose REST APIs, the real question was what to do with existing subsystems mentioned above.
We decided to expose existing store procedures that encapsulate distinct business operation (transaction) using DB2 REST services subsystem, and when not possible we opted to develop custom REST or SOAP endpoints.
We identified more than 25 distinct subsystems with some having more than 20 distinct API operations (REST endpoints) so total number of endpoint necessitated some kind of structured API management solution. Since client already had IBM DataPower gateways it was an obvious choice to use IBM API Connect product.
API Orchestration
Once we got all of the existing subsystems exposed and got interfaces that we could talk to there was another problem to solve.
Sheer number of exposed subsystem and endpoints resulted in cases where applications needed to call a lot of different endpoints just to get all the data needed to perform new business operations. Further analysis of subsystem data-models, flow logic and specific requirements meant that invoking, parsing, performing datatype conversion would result in non trivial logic inside new application that would deal with legacy systems.
We wanted to reduce and push out that kind of complexity out of application code into separate architectural layer in order to prepare whole system to migrate functionalities of existing legacy systems into future applications isolating changes into that separate layer in charge of orchestrating interactions with existing legacy subsystems.
That way service interface contracts of new applications are tailored based on their business requirements and not changes in legacy system interfaces while they undergo process of modernisation.
Orchestration layer is implemented using IBM Integration bus product alongside IBM MQ used internally for implementation of async flows in order to parallelise internal API invocations where possible.
Putting it all together
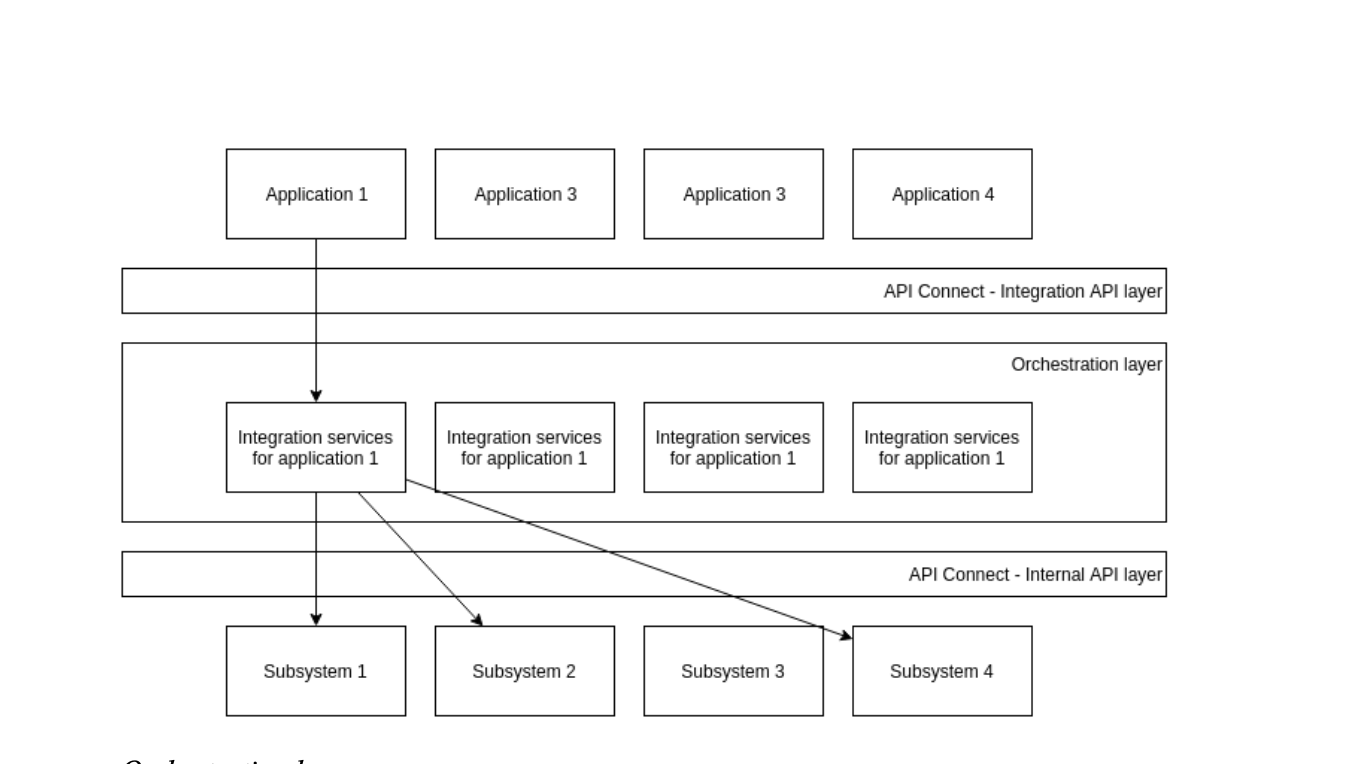
Orchestration layer
Implementing APIs and orchestrating them to tailor application specific integration services we ended up with following solution.
We wrapped IIB into APIC sandwich so that applications see the rest of the system as a set of tailored API endpoints enabling us to change and remodel integrated systems independently.
All in all, it was a complex but challenging and satisfying process. And we have set the stage for next part of modernization journey.
System integrations are not necessarily evil. Learn more how CROZ can help you overcome your System Integrations challenges.
Photo by Carl Nenzen Loven on Unsplash


