

Huge and complex integration projects take an organization out of its comfort zone. If you have issues dealing with challenges, our engineers can help!
I like Nassim Nicholas Taleb’s work. A couple of years ago, I got hooked on his Incerto series, and somehow, the Antifragile part provoked the majority of a-ha moments. Reading through it I felt it makes me better equipped for dealing with challenges that float around in the technology-driven business. And I keep coming back to it very often.
There was one particular, very short paragraph in Antifragile about strength training – deadlifting, more specifically. It talks about how your body can’t be ideally trained with specific and local muscle exercises only. Trying to lift a heavy object, you engage every muscle in your body. The heavier the weight, the higher the number of muscles involved.
And speaking of lifting heavyweights… We’ve recently lifted one that made us pull everything from our toolboxes and engage every muscle in our organizational body. Not surprisingly, this story from Antifragile somehow popped up as a good metaphor for the story about our project. I’ll leave out the names (the client, country, project…) as those are irrelevant for the story here.
The project we were faced with was huge and rather complex technically (also complex in every other way – politics, contracting, etc., but again – those are irrelevant here). In a nutshell, we needed to provide a new UI to a 20+ years old monolith (you name it, we have it: Cobol, PL/I, DB2, zOS, …), reusing its business logic by building a new API layer on top of it. Not every monolith is the same. This one, you had to admire in a way, for its complexity, and the fact that it serves its clients for more than 20 years, in a very sensitive (read: money, auditing) and ever-changing (read: heavy regulation) business environment. On top of that, we also needed to deliver several completely new business apps, relying on data from the same monolith. And then, we needed to put all of that into the private cloud environment based on RedHat OpenShift. Historically, there were several occasions where we’ve chosen to introduce new tech into our mainstream stack (after thoroughly trying it out through PoC’s, labs, hackathons…) in a big and complex project. One might argue that it’s a risky strategy, and that wouldn’t be a completely false claim. But, being a technology professional services company, we constantly need to balance between keeping up the right pace with tech innovation, and not putting our projects delivery in jeopardy. Also, the drive for using new technologies comes from our engineers, and that means engagement and motivation. That’s crucial for a company like ours. And we’ve been keeping a good balance here for 15 years already, pretty successfully. Big projects can give you enough time and space (and budget?) to properly and carefully examine and roll new technology out. Caution is still required, as well as good communication, expectation management and transparency with your customer, of course.
So, no surprise, we took the riskier road with technology in this big project. But that doesn’t mean that we deviated from general good software engineering practices. We thought about architectural patterns and styles that might be appropriate for the project. For endeavors of this size and complexity, you simply need to do that. Otherwise, you’re doomed. There were several important patterns and styles we chose to use, to make the whole story sustainable even with a lot of new tech.
Breaking the monolith
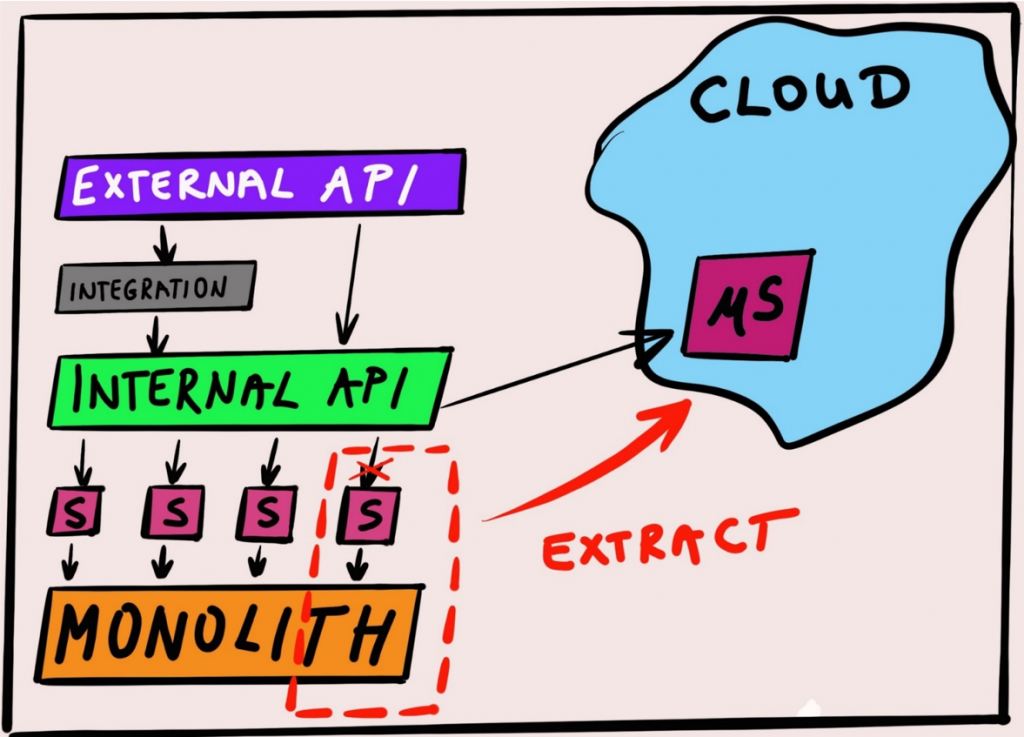
First, since there was an obvious modernization and “breaking-the-monolith” context involved, we decided that applying the Strangler pattern would be a good approach here, given the specifics of the monolith we had in front of us. It was there and throwing it out through the window was not an option. We had to use its existing business logic from the new UI, but keeping the new UI decoupled and safe from future changes that will happen to the monolith itself. So, using the Strangler concepts („…gradually create a new system around the edges of the old, letting it grow slowly over several years until the old system is strangled“), we built some glue code and grown some API’s on top of the monolith, exposing its business logic to the new UI, and at the same time creating a very flexible policy enforcement points (the same business logic needed to be available to many other external and internal client apps). We’ve used some integration magic here, with IBM API Connect, IBM Integration Bus and IBM DataPower. Here is a blog post describing detailed tech deep dive on breaking the monolith, so read that after if you’re interested.

CQRS and Event Sourcing with Axon Framework
Next up, we had to deal with the new apps we were supposed to build. Each of them was supposed to handle one specific sub-domain of the general business context. But the interesting part here were the patterns of interaction between those sub-domains, and very specific requirements related to auditability and tracking over time.
The nature of those made us consider treating the changes in business entities as discrete events, rather than preserving the entire state of entities. The traditional way of capturing the current state of entity and storing it in relational database does not provide an easy way of figuring out how that current state was reached. And this particular thing was very important in our requirements. Event Sourcing is an architectural approach in which an application’s state is stored through the history of events that have happened in the past. The current state, at any point in time, is then reconstructed based on the full history of events, each event representing a discrete change in the application. This is very handy for systems that need to be able to easily provide a full audit log for a review, and that was us.
Another specific of the business processes we had in front of us was an obvious disproportion in the frequencies of different task types that are being executed by the users. For a business user, a typical flow through the process means doing mostly various searches and fetching specific data about business domain entities. And then, at some point within a process – they execute a command of some kind (mostly creation of new entities, or update of some existing ones). With large number of business users active in the system, and with an unknown number of external systems that might integrate in the future, it was reasonable to think about the design that would enable architecturally isolating those two. The isolation would enable us to build just the right amount of flexibility into the design to enable future scaling where it is most needed.
This is where an architectural pattern known as CQRS (Command-Query Responsibility Segregation) comes into play. We have already been experimenting with CQRS and Event Sourcing in our labs and pet projects for some time. The project context that was in front of us sounded just like the right kind of problem to be solved with these two. And Axon Framework was the weapon of choice in this case, giving us both the CQRS and Event Sourcing infrastructure to build upon.
We did a couple of workshops with Allard Buijze form AxonIQ, discussed the requirements and expectations, the specifics of the runtime environment that we needed to fit in with our solution, and finally decided to go on and start building the MVP with Axon Framework. There’s a deep dive blog coming about this too, so I won’t go into further details here.
Private cloud with RedHat OpenShift
Finally, there was one more thing to decide… do we go cloud-native, containers and Kubernetes or stay traditional? The whole project started back in late 2016, early 2017. At the time, the customer’s runtime environment had two options for us to choose from.
First one – use the mature and very well-tuned, and hardened IBM WebSphere Application Server environments. Second one – use the freshly created, mostly experimental, RedHat OpenShift cluster environment. At the time, no real business applications were running in this second environment. I already mentioned the fact that this project had a somewhat implicit “modernization” flavor around it. So, we chose to go cloud-native way, and decided to use the OpenShift as our runtime environment. Looking at the broader picture, it made every sense to do so.
From customer’s perspective – they were slowly starting a transition from mainly IBM mainframe-based environment towards a distributed and private-cloud-like strategy. And experimenting with RedHat OpenShift was just a piece in that whole puzzle.
From our perspective – we already had (again, this was late 2016, early 2017) substantial skills with Docker, Kubernetes and OpenShift, and were running a lot of our own dev environments on OpenShift cluster. Therefore, it only made sense to take it as a mainstream, and continue widening our experience and skills portfolio with this project.
And one more, very important thing… Remember the Strangler story from the beginning? With Strangler in place, and OpenShift being used as the de-facto runtime environment for new things built as a part of this project, we effectively put in place a strategy for moving the (strangled) parts of the monolith into the private cloud environment as microservices. The dots connected well.
So, was it deadlifting after all?
And now, back to Mr. Taleb… In Antifragile, he talks about how systems learn from extremes, and, for preparedness, calibrate themselves to be more able to withstand possible large shocks in the future.
To some extent, this project was an extreme for us. Trying to strangle the monolith (remember, the giant Cobol/PL/Db2/zOS thing from the beginning), while building a couple of new non-trivial business apps with CQRS and EventSourcing, and making it all flow well through pipelines towards OpenShift clusters… with roughly 50 people in 6-8 teams working in coordinated delivery cycles over 2 years… Sure, that was an extreme that we learned a lot from! Extremes like this one take an organization out of its comfort zone. For us that’s a good thing, and we know that we need to do this from time to time, to be able to keep learning and improving.
To stay with Taleb’s analogy, this form of organizational deadlifting made us push our limits, while building a certain amount of additional strength, just in case we need to do something similar in the future. In the organizational context, “additional strength” means that the bonds between teams have grown stronger, our decision making techniques have improved, and, finally, the way we are able to manage expectations, technical decisions and politics around such a complex project has reached a whole new level.
As an example of a new muscle grown, we’ve learned the true value and meaning of productizing our DevOps environment and policies. We had a non-production OpenShift environment in CROZ, used by teams during this project. Initially, we handled it on a first-come-first-serve basis. Optimistically, we assumed that each and every configuration request that came from teams will somehow magically end up being in line with everything else running on that environment. Not breaking anything. We were wrong. Large number of interdependent microservices, developed by several teams, with deployment pipelines built by teams… That was gonna blow up on us eventually. So we productized the whole thing. Standardized the pipelines, built a system for provisioning environments in a consistent way (based on a desired state). With central team owning the DevOps environment, syncing all the time with their liaisons in teams. That muscle ended up working extremely well. And finally, the central DevOps team grew into a very capable, heavy-battle-tested group of consultants. A long term benefit that truly counts.
A similar thing happened with API management. Several hundreds of different API’s were built for this project. Many of them being used by various client systems. Which, of course, requires different policies applied. So we ended up with a non-trivial logical architecture of API Connect, capable of providing multiple different governance policies for unique services (exposed from mainframe through glue code magic).
But, these things will be covered in more details in follow up blogs by my colleagues, so I’ll stop here.
To wrap things up, here’s another nice one from Antifragile: “Work on the maximum, spend the rest of the time resting and splurging on mafia-sized steaks.”. But, that’s the one we can’t really follow in its entirety, at least not for now.

