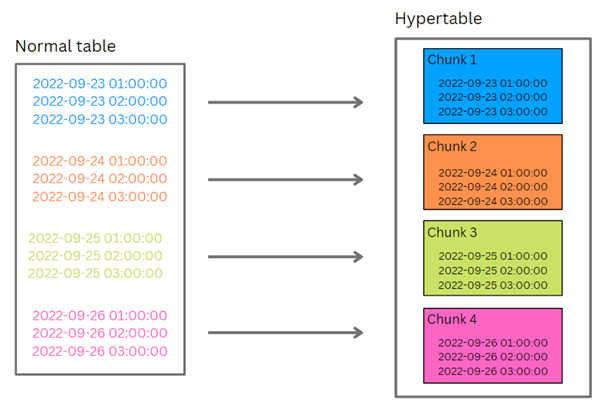
In the first part, we talked about the basics of TimescaleDB – how it works and what it’s all about. In this part, we will discover some neat little tricks you should have in mind while working with TimescaleDB and we will also see how it compares to regular Postgres regarding standard database operations… So, let’s get started.
Tips and Tricks
Some important things aren’t described or featured very well in the official TimescaleDB documentation. That is why we will feature a few tips and tricks you should have in mind while working with TimescaleDB.

- The table needs to be empty in order to transform it into a TimescaleDB table – otherwise, the transformation is not possible
- One chunk should fit into 25% of the computer memory – then the search and insertion into the table will be at its maximum efficiency
- It’s best to compress chunks only if you are not going to change them anymore – otherwise you have to decompress them before making the changes you wanted to make
- Continuous aggregate stores partial results – they are stored by intervals defined with the time_bucket
- The smaller the continuous aggregate intervals are, the more time it will take for the query to execute which means that sometimes it’s better to perform a query on the raw data than using continuous aggregate
Benchmark Testing
This section offers insight into TimescaleDB’s performance compared to the performance of PostgreSQL.

This is the description of the table used during the benchmark testing. Below are the results of the performed testing.
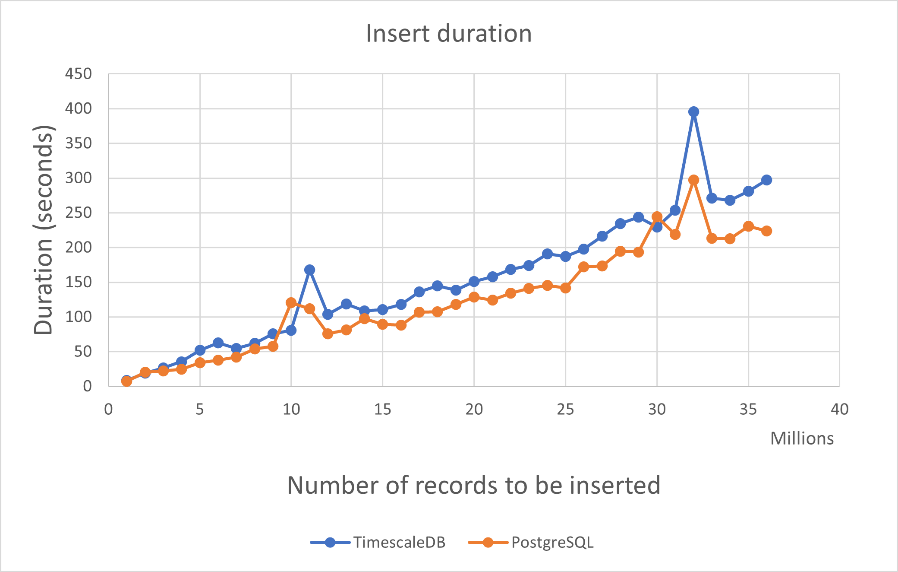
As you can see, TimescaleDB and Postgres are relatively similar when it comes to insertion durations. The TimescaleDB inserts take a little bit longer because TimescaleDB needs to insert the record into the right chunk depending on the record’s timestamp.
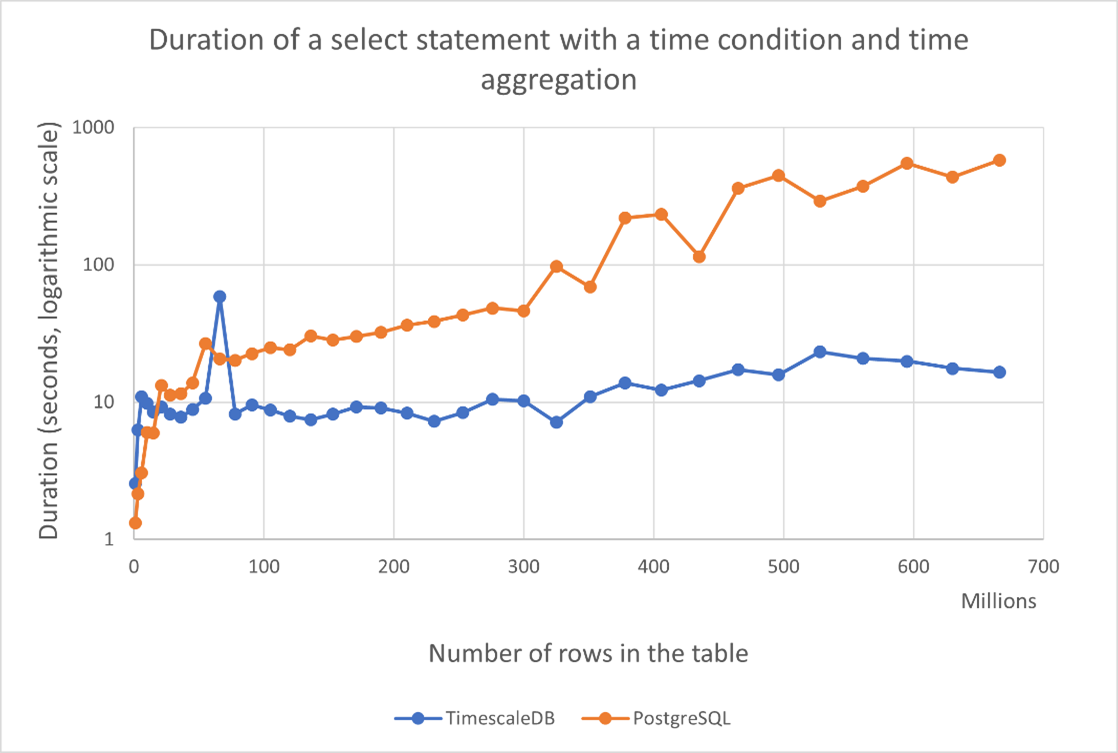
This graph is what it’s all about! It compares the duration of a SELECT statement with a time condition and time aggregation of TimescaleDB and Postgres and it shows that TimescaleDB is incredibly ahead in that regard. Although TimescaleDB is a bit slower when the record number isn’t that high, after a few million records it basically needs the same amount of time to do the operation no matter how many rows the table contains. Postgres is ten times slower than TimescaleDB when we are working with a few hundred million rows and when the row count is close to a billion, then Postgres becomes a hundred times slower than TimescaleDB. And that difference only increases with the number of records!
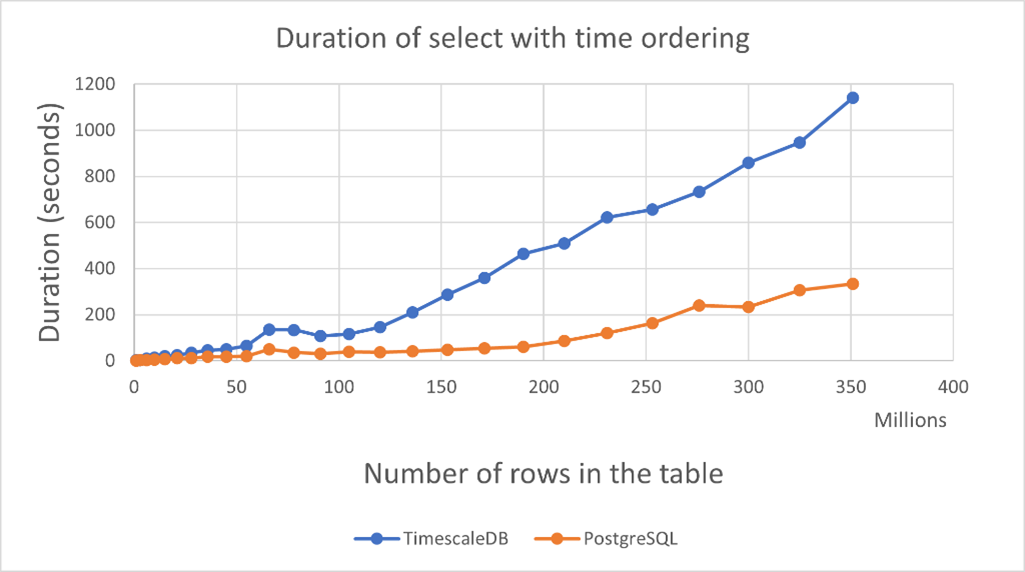
On the other hand, this graph shows the difference between TimescaleDB and Postgres when we have a SELECT with time ordering. We can see that TimescaleDB doesn’t handle ordering by time very well and Postgres is very much ahead in that regard. Although ordering by time isn’t as crucial of an operation as selecting with a condition and aggregation, it is definitely something that should be taken into account when working with TimescaleDB.
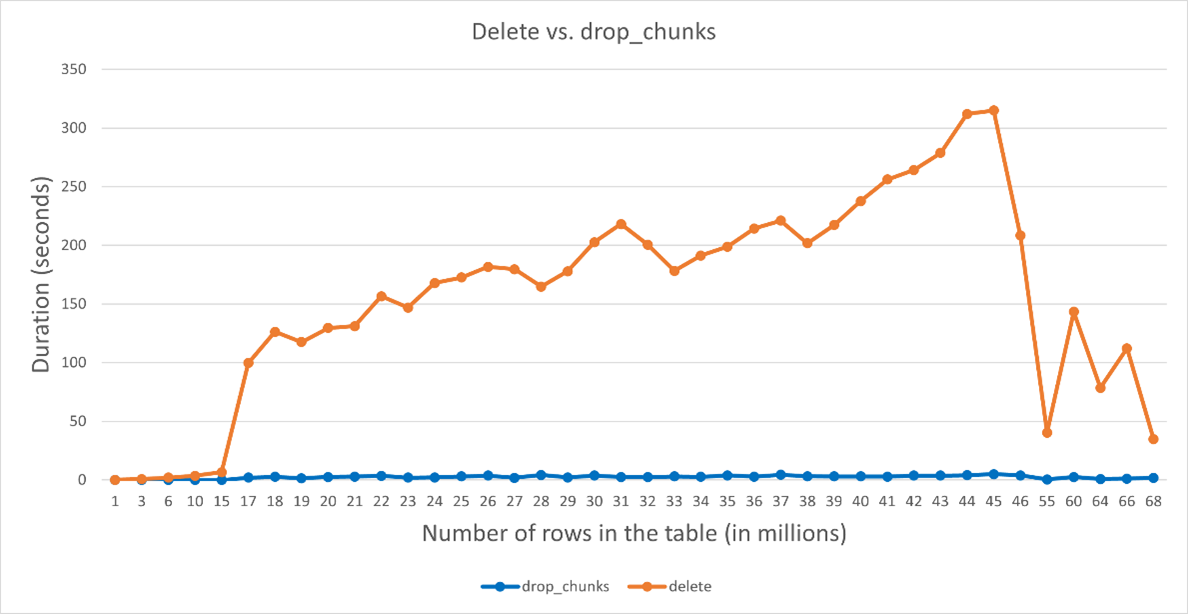
The standard DELETE statements are equally as fast in both Postgres and TimescaleDB. The true difference comes when comparing the DELETE statement with the TimescaleDB DROP_CHUNKS statement. The DROP_CHUNKS statement is a few hundred times faster than the standard DELETE statement. The reason for that lies in the fact that DROP_CHUNKS instantly deletes all the chunks that match the specified condition, while the DELETE statement needs to compare all the times in the table until it finds the ones that are a match.
Pros and Cons
Let’s check out a few pros and cons of using TimescaleDB.
Pros:
- Offers additional analytical functions specialized in working with time series data
- Has an open-source version
- Offers efficient data retention capabilities
- Continuous aggregates can ensure faster query execution
- Hypertables take care of partitioning and indexing all by themselves
Cons:
- Inserting data is slower than with standard Postgres and uses more memory
- Extremely weak if there are going to be a lot of updates to the table
- Ordering data takes a lot longer than with standard Postgres
- Time columns used in partitioning aren’t allowed to be NULL
When Would You Use TimescaleDB?
Since TimescaleDB is a Postgres extension, it can be used for exactly that – extending Postgres’ capabilities. You can use a standard Postgres relational table and a TimescaleDB hypertable in the same database which offers a few neat possibilities like using hypertables for storing and working with logs and relational tables for working with the rest of the database data. Besides that, TimescaleDB is great when you have to work with any sort of time-series data, especially when there is going to be a lot of it.
You have reached the end of the blog. But before you go, we encourage you to try TimescaleDB out for yourself, to have some fun with it, and gain some valuable hands-on experience with this incredible tool. And in case you need any help or you want to get started and you don’t know how, we are at your disposal. We want you to become a real TimescaleDB Tiger like us!
Literature