Introduction to vLLM
This is a “short” series describing our findings during the optimization of serving open-source autoregressive LLMs with the vLLM library for inference and serving. vLLM is one popular option for serving your own LLMs at scale.
The purpose of this series is not to explain all the great and fascinating details of vLLM library although some explanation is unavoidable if proper argumentation of engine configuration is given.
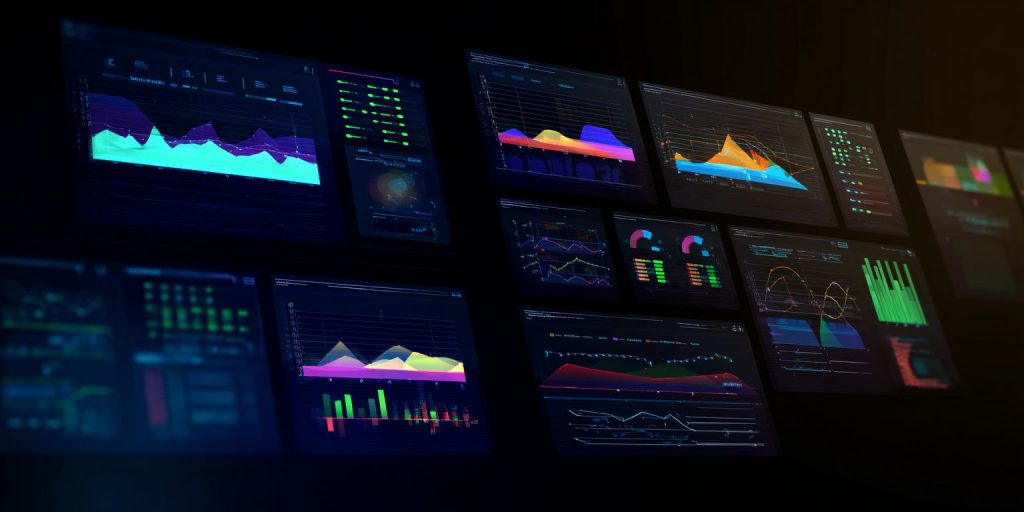
We will just leave here a beautiful schema of vLLM taken from this paper explaining the marvelously elegant PagedAttention algorithm that sits in the core of vLLM soul.
Hardware used
For the purpose of our benchmarking, we used a single server node with 8 GPUs NVIDIA A100 SXM4 80 GB.
With this configuration we have 640 GB of vRAM total on our node. The server uses NVLink and NVSwitch technology enabling bandwidth of 600 GB/s.
Dataset used
We used a dataset created by merging four existing coding datasets and filtering dataset entries related to Java, Spring, JavaScript, and React.
Data samples from the following existing datasets were used to create our own datasets for benchmark testing:
- https://huggingface.co/datasets/Crystalcareai/Code-feedback-sharegpt-renamed
- https://huggingface.co/datasets/MaziyarPanahi/Synthia-Coder-v1.5-I-sharegpt
- https://huggingface.co/datasets/Alignment-Lab-AI/CodeInterpreterData-sharegpt
- https://huggingface.co/datasets/adamo1139/m-a-p_CodeFeedback_norefusals_ShareGPT
We made this dataset publicly available on our HuggingFace profile
- https://huggingface.co/datasets/crozai/croz-infbench-sharegpt
- https://huggingface.co/datasets/crozai/croz-coding-sharegpt
- https://huggingface.co/datasets/crozai/croz-combo-sharegpt
Basically, we wanted a relevant benchmarking test set for the use case of coding with LLM.
Related topic: If you want to learn about using LLMs for data anonymization, check out this blog.
The model used and model architecture
For the purpose of benchmarking, we used the deepseek-ai/DeepSeek-R1-Distill-Llama-70B model which is a model distilled from DeepSeek-R1 but based on meta-llama/Llama-3.3-70B-Instruct model.
Basically, a Llama-3.3-70B enhanced with reasoning capabilities from DeepSeek-R1
deepseek-ai/DeepSeek-R1-Distill-Llama-70B characteristics:
- Parameter number – 70.6B parameters
- Parameter precision (Precision) – BF16 (bfloat16) == 2 bytes
- Number of layers (L) – 80 layers
- Hidden dimension (H) – 8192
- Grouped Query Attention mechanism
- (n_kv_heads) 8 KV Heads
- (n_q_heads) 64 Query Heads
- Max context length (max_position_embeddings) 131072 tokens
Benchmark used
For performing benchmark tests we used benchmark_serving.py available in the vllm GitHub source code repo
git clone https://github.com/vllm-project/vllm.git cd vllm/benchmarks
For the purpose of our testing, we refactored benchmark_serving.py with 2 additional parameters (min-tokens and max-tokens) so that during our test runs we can control the size of test sequences (prompt tokens) very precisely.
Each test run was performed locally on a node hosting the model by invoking benchmark script with the same parameters every time.
python vllm/benchmarks/benchmark_serving.py --backend openai --base-url http://localhost:8000 --dataset-name hf --dataset-path crozai/vllm-benchmark-coding --hf-split train --max-concurrency 10 --request-rate 10 --num-prompts 50 --model deepseek-ai/DeepSeek-R1-Distill-Llama-70B --metric-percentiles 25,50,75,99 --percentile-metrics ttft,tpot,itl,e2el --seed 42
In our tests, we used vLLM v0.7.3. with V0 engine.
Memory Hunger Games – Pipeline Parallelism vs Tensor Parallelism
Pipeline and tensor parallelism in vLLM are distributed computing strategies used for scaling large language models that don’t fit on a single GPU node. Since our testing model uses 2-byte precision, the memory required to store this model weights is around 140GB. However, the memory required for a KV cache of a single max size prompt of 128K tokens is around
2(K and V cache) x Precision x H x L x Context = 2 x 2 x 8192 x 80 x 131072 ≈ 312.5 GB
Summed up together with model weights this calculation leads to around 460GB of total memory required to process maximum size batches and prompt lengths. In total, our node has 640GB of vRAM but only 80GB per GPU. Since our requirement is to support an inference of max prompt lengths of 128K tokens we must use GPU parallelism.
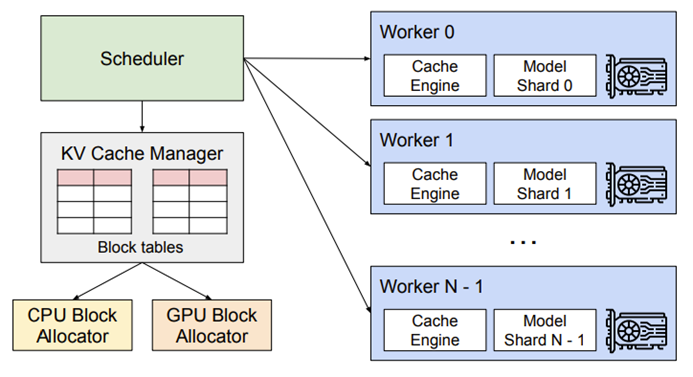
Tensor parallelism
When tensor parallelism is used model weights are distributed (sharded) across multiple GPUs. With Grouped Querry Attention models like ours sharding of parameters is performed per Query heads. Kind of logical when you think of it since calculation on each group of heads is performed independently during the forward pass in the attention mechanism. It is therefore important that the number of Query heads in a model is divisible by a number of GPUs we are sharding on. Tensor parallelism in vLLM is configured with –tensor-parallel-size parameter and it is required that:
n_q_heads / tensor-parallel-size = a whole number.
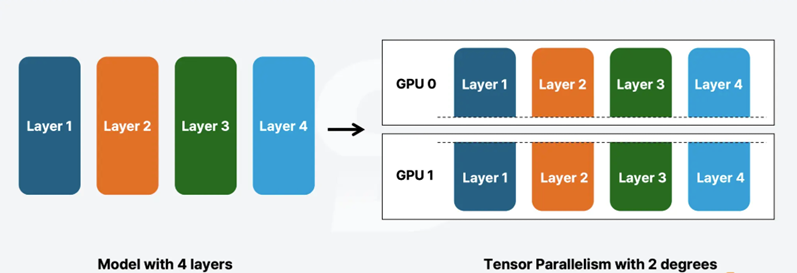
Pipeline parallelism
This parallelism option distributes model layers across multiple nodes, assigning contiguous layer groups to different devices. It is also used for enabling inference of models too large for a single GPU. It is mostly used to distribute the model across multiple nodes(servers) although it can be used to optimize single node with multiple GPUs too. Parameter controlling this parallelization is –pipeline-parallel-size.
The correlation between these two parameters that need to be respected is given with the formula:
tensor-parallel-size x pipeline-parallel-size = total number of GPUs across nodes
Since we are running the model on a single node with multiple GPUs we will test tensor parallelism against pipeline parallelism on a single node.
Requirements:
Utilize all 8 GPUs in the most optimal way to achieve optimal throughput, inter-token latency, and time to first token.
Tests:
We performed 2 test runs on a single sequence(prompt) of length 16K tokens.
First test run with –tensor-parallel-size=8
command: --model=deepseek-ai/DeepSeek-R1-Distill-Llama-70B --trust-remote-code --device=cuda --disable-log-requests --gpu-memory-utilization=0.95 --tensor-parallel-size=8
============ Serving Benchmark Result ============ Successful requests: 1 Benchmark duration (s): 54.52 Total input tokens: 15781 Total generated tokens: 2815 Request throughput (req/s): 0.02 Output token throughput (tok/s): 51.63 Total Token throughput (tok/s): 341.06 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 18.73 Median TPOT (ms): 18.73 P25 TPOT (ms): 18.73 P75 TPOT (ms): 18.73 P99 TPOT (ms): 18.73 ---------------Inter-token Latency---------------- Mean ITL (ms): 18.73 Median ITL (ms): 18.59 P25 ITL (ms): 18.50 P75 ITL (ms): 18.71 P99 ITL (ms): 21.00
Second test run with –tensor-parallel-size=2 –pipeline-parallel-size=4
command: --model=deepseek-ai/DeepSeek-R1-Distill-Llama-70B --trust-remote-code --device=cuda --disable-log-requests --gpu-memory-utilization=0.95 --tensor-parallel-size=2 --pipeline-parallel-size=4
============ Serving Benchmark Result ============ Successful requests: 1 Benchmark duration (s): 148.18 Total input tokens: 15781 Total generated tokens: 1940 Request throughput (req/s): 0.01 Output token throughput (tok/s): 13.09 Total Token throughput (tok/s): 119.59 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 73.57 Median TPOT (ms): 73.57 P25 TPOT (ms): 73.57 P75 TPOT (ms): 73.57 P99 TPOT (ms): 73.57 ---------------Inter-token Latency---------------- Mean ITL (ms): 1169.36 Median ITL (ms): 1170.36 P25 ITL (ms): 1159.91 P75 ITL (ms): 1179.33 P99 ITL (ms): 1200.82
Conclusion
Pipeline parallelism on a single node is not usable. We observed much worse output token throughput (13.09 tok/s vs 51.63 tok/s) and a huge difference in inter-token latency (1170 ms vs 18.59 Median ITL). We will use tensor parallelism set to 8 since we have 8 GPUs and we are using model with 64 Query Attention heads. 64 is divisible by 8 so we are good.
Multiple requests and Large prompts vs Small prompts.
Two key features in vLLM’s inference scheduling are token batching and prompt chunking, controlled by the –max-num-batched-tokens and –enable-chunked-prefill settings.
Token batching refers to how vLLM groups multiple sequences (requests/prompts) into a single forward pass on the model. Instead of processing one sequence at a time, vLLM can batch-process multiple sequences together to better utilize the GPU. –max-num-batched-tokens sets an upper limit on the total number of tokens that can be processed in one iteration (one scheduler step).
Prompt chunking refers to splitting a long prompt (input context) into smaller chunks that can be processed in pieces rather than all at once. In vLLM, this feature is called chunked prefill and is enabled by the flag –enable-chunked-prefill. When a new request comes in with a prompt of N tokens, the model must perform a prefill (prompt processing) step. It processes all N input tokens to build up the key/value cache (e.g. KV cache or internal state) before it can start generating the output tokens. This prefill step can be expensive and take a lot of time if N is large (scenarios like a long chat history or large application codebase in a context).
After the prefill, the model generates output tokens one by one (this is also called the decode stage). Each decode step uses the cached context(KV cache) and appends one new token. By default, without chunked prefill, vLLM prioritizes prefill requests and does not mix prefill and decode in the same batch. When chunked prefill is enabled, vLLM changes its scheduling to allow mixing prompt processing with token generation by breaking up the prompt into chunks. This way it prioritizes decode requests (ongoing generations) first.
Requirements:
- Achieve optimal throughput for both small and large prompts
- Support max size prompts of 128K
- Prioritize ongoing requests
- Support multiple request processing
Tests:
We performed 4 test runs on a sampled set of 20 sequences each of length 16K tokens.
All tests were run with benchmark_serving.py set to –max-concurrency 20 –request-rate 20. Basically, we allowed all 20 sequences to be processed in parallel.
We used —max-model-len=131072 setting value for all test runs. In each test run we tested –max-num-batched-tokens against different values, respectively 16K, 32K, 64K, and 96K.
First test run with –max-num-batched-tokens set to 96K
command: --model=deepseek-ai/DeepSeek-R1-Distill-Llama-70B --trust-remote-code --device=cuda --disable-log-requests --gpu-memory-utilization=0.95 --tensor-parallel-size=8 --max-model-len=131072 --max-num-batched-tokens=98304 --enable-chunked-prefill
============ Serving Benchmark Result ============ Successful requests: 20 Benchmark duration (s): 447.16 Total input tokens: 315611 Total generated tokens: 130634 Request throughput (req/s): 0.04 Output token throughput (tok/s): 292.14 Total Token throughput (tok/s): 997.95 ---------------Time to First Token---------------- Mean TTFT (ms): 20543.10 Median TTFT (ms): 20673.87 P25 TTFT (ms): 13596.82 P75 TTFT (ms): 28828.00 P99 TTFT (ms): 37430.83 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 32.94 Median TPOT (ms): 30.84 P25 TPOT (ms): 27.11 P75 TPOT (ms): 37.83 P99 TPOT (ms): 50.15 ---------------Inter-token Latency---------------- Mean ITL (ms): 28.79 Median ITL (ms): 25.68 P25 ITL (ms): 24.64 P75 ITL (ms): 30.02 P99 ITL (ms): 38.08
Second test run with –max-num-batched-tokens set to 64K
command: --model=deepseek-ai/DeepSeek-R1-Distill-Llama-70B --trust-remote-code --device=cuda --disable-log-requests --gpu-memory-utilization=0.95 --tensor-parallel-size=8 --max-model-len=131072 --max-num-batched-tokens=65536 --enable-chunked-prefill
============ Serving Benchmark Result ============ Successful requests: 20 Benchmark duration (s): 251.08 Total input tokens: 315611 Total generated tokens: 68630 Request throughput (req/s): 0.08 Output token throughput (tok/s): 273.34 Total Token throughput (tok/s): 1530.38 ---------------Time to First Token---------------- Mean TTFT (ms): 21543.10 Median TTFT (ms): 23673.87 P25 TTFT (ms): 14596.82 P75 TTFT (ms): 30828.00 P99 TTFT (ms): 36430.83 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 34.05 Median TPOT (ms): 34.38 P25 TPOT (ms): 30.14 P75 TPOT (ms): 38.29 P99 TPOT (ms): 43.77 ---------------Inter-token Latency---------------- Mean ITL (ms): 32.14 Median ITL (ms): 29.92 P25 ITL (ms): 26.03 P75 ITL (ms): 30.61 P99 ITL (ms): 38.16
Third test run with –max-num-batched-tokens set to 32K
command: --model=deepseek-ai/DeepSeek-R1-Distill-Llama-70B --trust-remote-code --device=cuda --disable-log-requests --gpu-memory-utilization=0.95 --tensor-parallel-size=8 --max-model-len=131072 --max-num-batched-tokens=32768 --enable-chunked-prefill
============ Serving Benchmark Result ============ Successful requests: 20 Benchmark duration (s): 406.29 Total input tokens: 315611 Total generated tokens: 110435 Request throughput (req/s): 0.05 Output token throughput (tok/s): 271.81 Total Token throughput (tok/s): 1048.62 ---------------Time to First Token---------------- Mean TTFT (ms): 20615.49 Median TTFT (ms): 20655.26 P25 TTFT (ms): 12061.69 P75 TTFT (ms): 29124.67 P99 TTFT (ms): 37890.36 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 33.46 Median TPOT (ms): 32.77 P25 TPOT (ms): 29.64 P75 TPOT (ms): 36.62 P99 TPOT (ms): 47.91 ---------------Inter-token Latency---------------- Mean ITL (ms): 28.79 Median ITL (ms): 26.80 P25 ITL (ms): 21.67 P75 ITL (ms): 30.22 P99 ITL (ms): 38.57
Fourth test run with –max-num-batched-tokens set to 16K
command: --model=deepseek-ai/DeepSeek-R1-Distill-Llama-70B --trust-remote-code --device=cuda --disable-log-requests --gpu-memory-utilization=0.95 --tensor-parallel-size=8 --max-model-len=131072 --max-num-batched-tokens=16384 --enable-chunked-prefill
============ Serving Benchmark Result ============ Successful requests: 20 Benchmark duration (s): 963.98 Total input tokens: 315611 Total generated tokens: 113794 Request throughput (req/s): 0.02 Output token throughput (tok/s): 118.05 Total Token throughput (tok/s): 445.45 ---------------Time to First Token---------------- Mean TTFT (ms): 21486.56 Median TTFT (ms): 21359.92 P25 TTFT (ms): 11339.18 P75 TTFT (ms): 31346.85 P99 TTFT (ms): 41434.74 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 62.54 Median TPOT (ms): 61.36 P25 TPOT (ms): 59.25 P75 TPOT (ms): 65.65 P99 TPOT (ms): 73.02 ---------------Inter-token Latency---------------- Mean ITL (ms): 60.15 Median ITL (ms): 61.20 P25 ITL (ms): 45.70 P75 ITL (ms): 62.73 P99 ITL (ms): 92.18
Conclusion:
Across our four test runs, we observed that the smallest setting of max-num-batched-tokens=16384 clearly yielded the worst overall performance. Likely because it nearly matches the 16K prompt size for all our 20 sequences in the test sample and thus vLLM cannot effectively batch multiple sequences at once. As max-num-batched-tokens increased we saw small improvements, culminating in the best results at 98304. Key metrics such as output token throughput and inter-token latency showed consistent gains with larger batch settings.
In short, if the system has enough available GPU memory, setting max-num-batched-tokens as high as possible yields better throughput and lower latency, improving overall serving performance.
We can observe the vLLM metrics during all of our 4 test runs on the following vLLM Grafana dashboard.
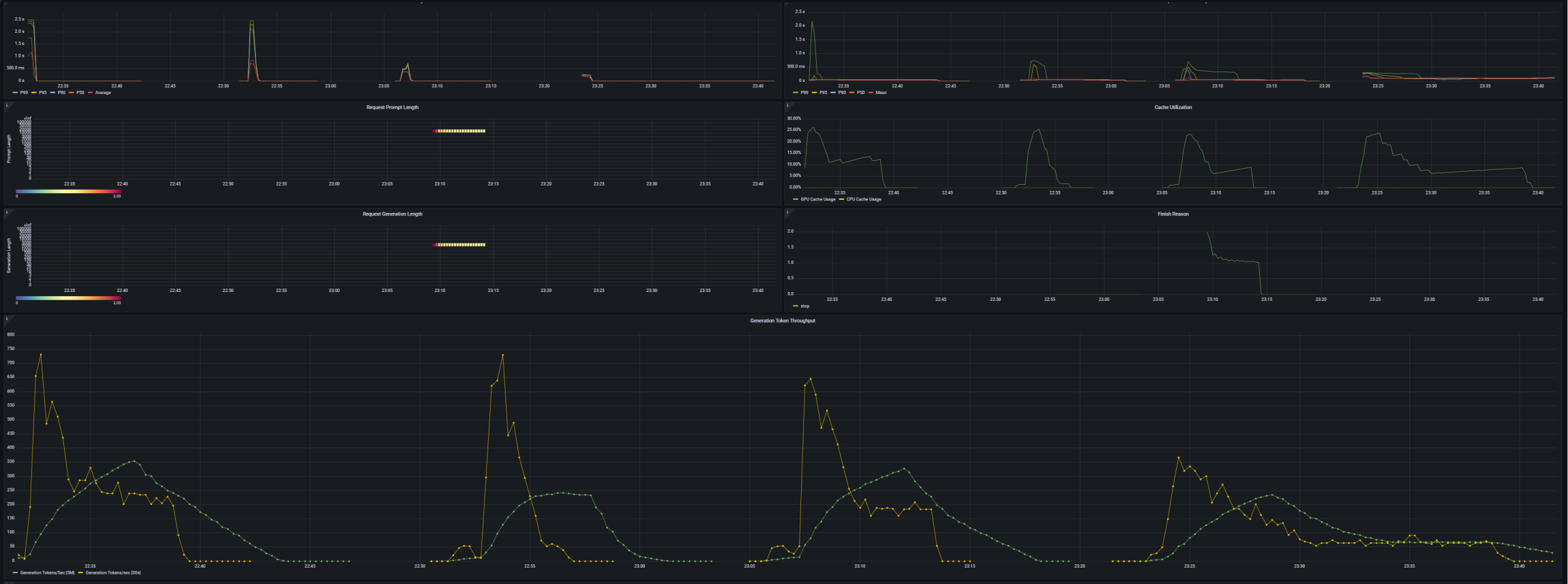
There are also other parameters that also influence prompt chunking, but we will not go into details about those for now and use defaults. Those are –max-num-partial-prefills, –max-long-partial-prefills, –long-prefill-token-threshold
We continue vLLM optimization in the next blog post.