

It’s been over a month since Spark 3.0 came out and we decided that it would be beneficial for our readers to learn what changes it brought. As it is custom with all major releases, the list of changes is pretty hefty. In this blog we will cover, what we think are, the most important changes.
Find out:
- How to benefit from setting up adaptive query execution to re-optimize and adjust query plans based on runtime statistics collected in the process of query execution
- How to use dynamic partition pruning to set up query condition for an out-of-the-box optimization in order to significantly increase performance
- What are the benefits of accelerator-aware scheduling
- How to enable ANSI compatibility and what benefits it brings
First of all, let us talk about adaptive query execution (AQE). Spark SQL is being used more and more every day so having a great execution plan for that query is crucial. Basically, what happens when we write a SQL query for Spark in our preferred language, Spark takes this query and translates it into a logical plan of execution. During this phase Spark optimizes the logical plan by applying a set of transformations (column pruning, filter push-down and others). Next step is the physical planning phase, where it generates an executable plan (in essence, it decides how the computation is distributed along the cluster). Having all this in mind, it is understandable how important it is to choose the best plan for running a query. This is where adaptive query execution shines looking to re-optimize and adjust query plans based on runtime statistics collected in the process of query execution. We will not discuss technical details any further because there is a lot of stuff happening beneath the surface but the concept can be seen in the picture below. AQE is disabled by default in Spark 3.0, but it can be easily enabled by setting SQL configuration spark.sql.adaptive.enabled to true. However, any query that wants to benefit from AQE needs to meet 2 criteria:
- It must not be a streaming query
- It has to contain at least one exchange (usually when there is a join, window operator or some aggregation)
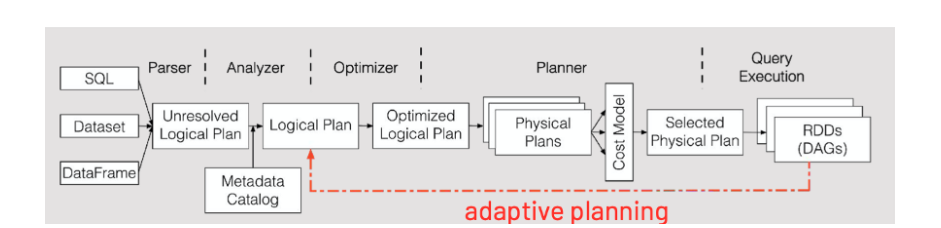
Figure 1 Adaptive query execution
Next change we are going to highlight is dynamic partition pruning. Since Spark is a data analytics framework, it is crucial to detect and avoid scanning data irrelevant to the executed query in order to improve speed. This technique is known as partition pruning (if it is done at compile time it is also known as static partition pruning). Dynamic partition pruning occurs when the optimizer is unable to identify at parse time the partitions it has to eliminate (it is activated during execution time). This especially comes into play when we consider a star schema which consists of one or more fact tables referencing any number of dimension tables. In such join operations we can prune the partitions join reads from a fact table by identifying those partitions that result from filtering the dimension tables. This optimization is worked out-of-the-box, so there is no need to change any configurations as long as our query meets the following conditions:
- Data needs to be partitioned and join must be based on the partition key (eg. data must be partitioned by dimension key)
- This optimization is only triggered when the join is planned as broadcast-hash join
- It works only with equi-joins (a=b)
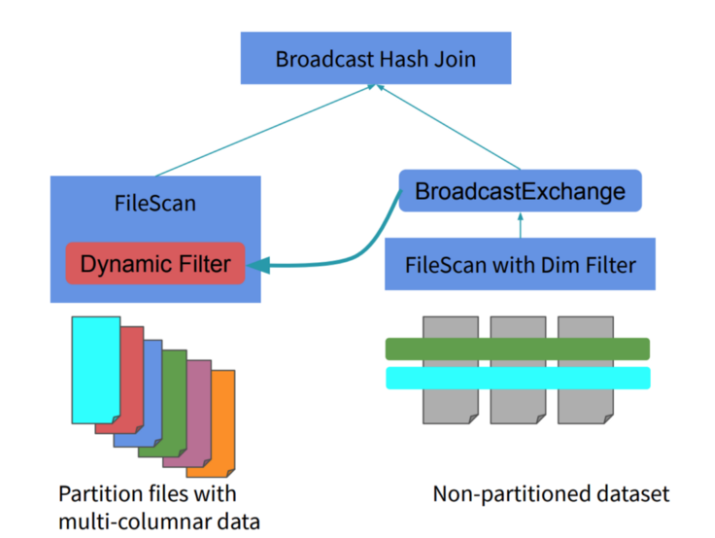
Figure 2 Dynamic partition pruning
Performance of Spark 3.0 with dynamic partition pruning compared to performance of a previous version of Spark was tested using TPC-DS queries. The results showed that 60 out of 102 queries show a significant speed up between 2 and 18 times (as seen in the picture below).
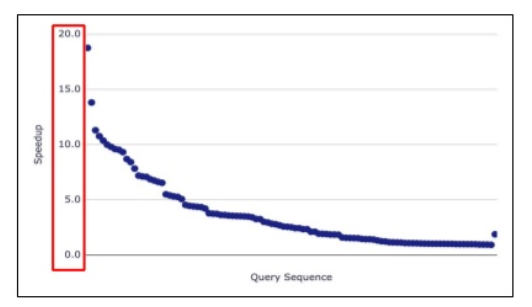
Figure 2 Dynamic partition pruning
Spark 3.0 also brings accelerator-aware scheduling, which means GPUs are now a schedulable resource (for all of you data scientists out there – this is a part of Project Hydrogen initiative to help the engine succeed in deep learning context). This allows resources to be discovered on the nodes and to determine what resources were assigned to tasks and to the drivers. The amount of resources assigned to tasks/drivers are dependent on the configuration we pass to them. With it also comes an API to easily check the assignments and an UI hooked into Spark UI. The accelerator-aware scheduler can work with Standalone, YARN and Kubernetes cluster managers.
The change we like the most is the ANSI SQL compliance. SQL is the undisputed ruler of the world of data, so it makes us extremely happy to see that Spark adopted the ANSI standard. To enable ANSI compatibility, all that needs to be done is to set configuration spark.sql.ansi.enabled to true (disabled by default). This change added checking for overflows for numeric types, type conversion (explicit casting by CAST throws a runtime exception for illegal cast patterns) and SQL keywords.
Some other changes that are also worth mentioning are:
- PySpark enhancements (with Python being the number one language used with Spark, changes were made to Pandas package)
- Java 11 support
- connector enhancements (optimizations for CSV, Parquet/ORC, Kafka, Hive)
- new Structured Streaming UI
- native support for Prometheus monitoring
- Hadoop 3 support
- and many more…
For a full list of changes check out the link.

