

In the previous blogs, we discussed MLFlow and Kubeflow, two powerful components that enable efficient experiment tracking, model packaging, and deployment. Today, we continue our journey by diving into another tool in the MLOps ecosystem: data and model versioning.
As organizations increasingly adopt MLOps practices to streamline machine learning operations, a crucial need emerges for a robust framework for versioning and managing data, ensuring reproducibility, and enabling efficient collaboration and pipeline automation. We will delve into the world of data and model versioning to explore its vital significance to MLOps, revolutionizing the way machine learning workflows are orchestrated.
Why version data and models?
In the world of data science and machine learning, managing and tracking data and models can be a challenging task. Data scientists often work with massive datasets, multiple iterations of models, and various experiments. As these projects get more complex over time, different teams and contributors often grapple with version control issues, struggling to keep track of data changes, reproduce results, and collaborate seamlessly. And it is widely known that one should never use Git for storing large files.
Storing your data in Git is not the best solution because:
- Git is designed primarily for storing text files
- Git-LFS, a built-in file system, requires a server and has a size limit
It is crucial to have a robust system in place to ensure collaboration, reproducibility, and version control. So, the question is, how should you track your data and models, if not with Git? Let me introduce you to Data Version Control – DVC.
What is Data Version Control (DVC)?
Data Version Control (DVC) is an open-source version control system designed specifically for managing data science projects. It works in tandem with Git, a popular distributed version control system, to extend version control capabilities to large files such as datasets, models, and intermediate results. It enables data scientists to track changes made to data and models over time, collaborate with team members, and reproduce experiments reliably.
DVC tracks versions of your data or models by generating a lightweight text file containing metadata that points to a specific version of your data or model. These small files are stored on Git with our code, and they are used every time we want to fetch a specific version of our dataset from remote storage. This means that in the end we have our code and DVC metafiles tracked with Git, while the actual data and models are persisted in the remote storage.
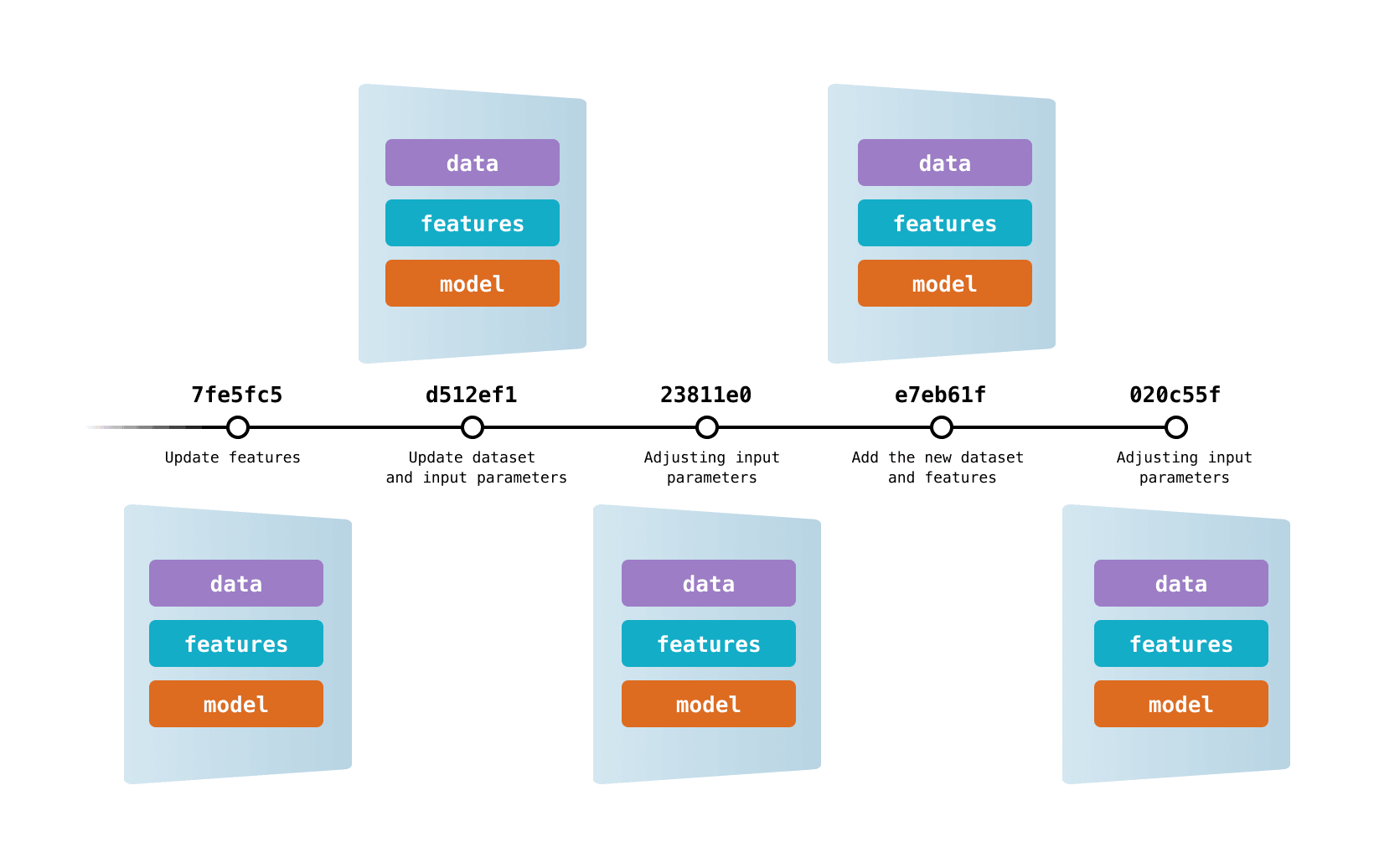
Version Control with DVC: www.dvc.org/doc/use-cases/versioning-data-and-models
Getting started
To begin using DVC, you need to install it on your system. It can be installed with pip or conda, depending on your preferences. It also requires Git to be installed as it uses Git for tracking metadata. Run the following command:
$ pip install dvc
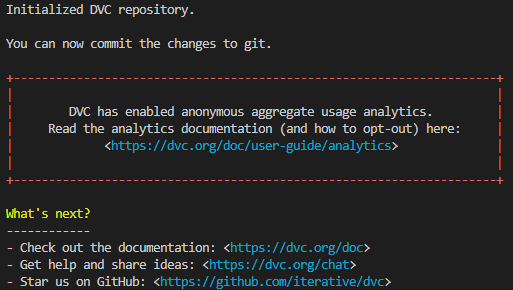
Once DVC is installed, navigate to your project directory and initialize DVC repository. This command creates a new directory called .dvc, which stores the DVC configuration and metadata.
$ dvc init
If everything goes smooth, you should see the following message.
Next, you need to specify a remote storage. DVC supports different types of storages, some of which are Google Drive, Amazon S3, file server, HDFS or even your local machine. In general, you can setup a remote storage using the following command:
$ dvc remote add –-default <storage_name> <path_to_remote>
With DVC initialized and remote storage setup, you can start tracking your data and models. DVC uses the dvc add command to track large files such as datasets, models or any files relevant to your project. This command creates a placeholder file which points to the actual data or model in your remote storage.
$ dvc add <file_path>
This command will create a .dvc file corresponding to the tracked file. The actual file will be stored outside of the repository, while the .dvc file will contain the metadata necessary for DVC to manage the file.
Now that you have added and tracked your data or model files, you can commit changes to your Git repository. By committing the changes, you are effectively saving the state of your project along with the tracked data or model files. Remember, alongside with your code, you should also commit every DVC generated file.
$ git add . && git commit –m “Added files to DVC"
The last thing left is to push your data to remote storage. To do so, run the following command:
$ dvc push
Now, team members can collaborate on the project by cloning the Git repository to their local machine and fetch the latest changes, including the metadata and the pointers to the actual data and models. This ensures that everyone works with the same versions of files.
To fetch data and models metafiles point to, run:
$ dvc pull
After pulling the changes, team members can reproduce experiments by using the exact versions of data and models that were used during the original experiment. This ensures reproducibility and eliminates any inconsistencies due to missing or mismatched dependencies.
Data pipelines
DVC provides a powerful interface for defining and managing complex data pipelines. A data pipeline consists of a sequence of data processing steps that transform raw data into a processed format suitable for training models or conducting analysis. DVC’s pipeline functionality allows you to define and automate these steps, making it easier to reproduce and share data preprocessing and transformation workflows.
To create a pipeline using DVC, you need to define different stages involved in your processing workflow. Create a dvc.yaml in your project directory to define the pipeline stages. This YAML file will serve as a configuration for your pipeline. Note the following example:
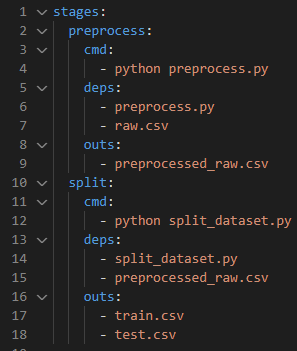
In this example, we have defined two stages: preprocess and split. The cmd field specifies the command to execute for each stage, while the deps field lists the input dependencies required for the stage. The outs field lists the output files generated by each stage.
To run the pipeline, execute the following command:
$ dvc repro
This command runs the pipeline stages in the specified order, automatically tracking dependencies and ensuring that each stage is executed only if its dependencies have changed.
After the pipeline has run successfully, only thing left is to commit all code and DVC generated files to Git and to push your data and models to DVC remote storage with dvc push (there is no need to dvc add each file because pipeline does it all for you, for all stage outputs).
One of the main advantages of using DVC’s pipeline feature is the ability to easily reproduce your data processing workflow. If any changes occur in the input dependencies, running the pipeline again ensures that all the stages are re-executed in the correct order, leading to updated output files.
Conclusion
DVC fills a crucial gap in the data science workflow by extending version control capabilities to large files, enabling data scientists to manage and track their datasets, models, and experiments effectively. By providing features such as data and model versioning, reproducibility, collaboration, pipeline creation, and integration with existing tools, DVC empowers data scientists to work more efficiently, ensure reproducibility, and accelerate their research and development efforts in the field of data science and machine learning.


