

More than 50 years have passed since data warehousing (a.k.a. DWH) was born and it’s still playing a key role in data analysis and business intelligence reporting for many organizations. Data warehousing wouldn’t be possible without a data preparation process in which data is Extracted from source databases, then Transformed and finally Loaded into data warehouse database. Such a process is commonly known as ETL process.
Of course, during these 50 years a lot of new and cool stuff was invented in the data engineering field: NoSQL databases, Hadoop and other big data technologies like Spark, distributed systems/databases, data lakes, cloud technologies, just to name a few. And all these share one thing in common, they need some sort of ETL (or ELT which we will explain later) to be performed.
This blog post is the first in a series of five blogs in which we will focus on ELT with modern data technologies like Airbyte, Airflow, dbt and Python. Since ELT is just one subset of data processing, after ELT series, in three more series, we will cover other parts of data pipeline:
- Data governance
- Analytics and visualization
- Data store
Some of the most important technologies we are using on projects or R&D are shown in the figure below. Most of those, but not all, technologies will be covered in this and following blog series. If you’re interested in some of the technologies that are not covered in blogs, reach out to us, we’d be glad to help. There are a lot of technologies like Hadoop, Cognos, Informatica, DataStage, Azure Data Factory, Azure Synapse or AWS Glue which we are using on our projects but we didn’t put on this figure because the goal of this blog series is to demonstrate how traditional data integration can be challenged with modern technologies and approaches.

Traditionally organizations have used well known and established commercial ETL tools like IBM DataStage or Informatica, but lately in some organizations we see a shift towards open-source ETL tools (such as Keboola) and the rise of ELT process.
So, let’s start by quickly explaining the main difference between ETL and ELT. In traditional ETL, data is extracted from source systems into staging database where data is transformed and then loaded into target schema. With ELT we get rid of the intermediate ETL server by first loading data directly from source systems into target system and then performing needed transformations on the data.
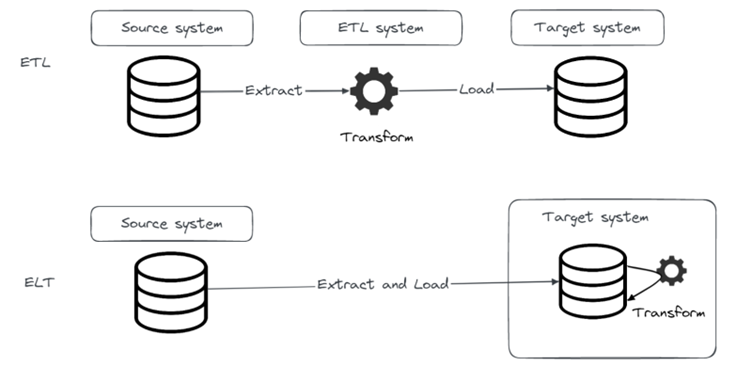
ELT concept started gaining popularity during the big data and data lake hype. Which makes sense because with EL data is immediately available for processing for different consumers. Also, modern systems have enough processing power to handle the T part on huge amounts of diverse data. The problem with that approach is that it got us used to thinking in a way “I’ll just throw data into the lake and think about processing later”. That led to a number of problems including the birth of data swamp and forgetting about the T part of ELT. But it also made data available for consumption to much more users like data scientists that need to explore data first before doing any T.
ETL and ELT will both continue to live, but in this blog series we will focus on demonstrating some ELT related technologies and approaches.
Great, so how do we do ELT?
There are a lot of different approaches to data integration, and the number of tools and frameworks present today is astonishing. At CROZ, we are constantly keeping an eye on new technologies and testing them in internal pilot projects to provide informed recommendations to clients seeking to modernize their data platforms.
Technologies and approaches that we will demonstrate in this series are:
- EL with Airbyte
- SCD2 with Airflow, Python, S3 and Postgres
- T with dbt
- Data quality with great_expectations
This series of blogs will go deeper into the implementation details and how specific use cases can be solved with those technologies.
Learn about Airbyte in our next blog post that’s coming out in two weeks. Besides the introduction, we will demonstrate some examples of its usage including more advanced features like loading data in slowly changing dimension (SCD) fashion.
Stay tuned!
Data blog series (1 of 5):


