Find out more about query execution in Trino and the results of the performance testing of Trino on Hive data, Hive, and Hive-interactive. For those just starting with Trino, we suggest reading the blog “Where is the future of querying disparate systems – Trino.”
Query execution
When a client submits an SQL statement, the coordinator takes that as a text, parses it, and analyzes it. Then, it creates a plan for execution by using an internal data structure called a query plan. This flow is shown in figure 1.
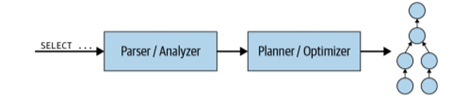
Figure 1. Processing a SQL query statement
Query generation plan uses the metadata SPI (Service Provider Interface) and the data statistics SPI to create a query plan. The coordinator uses the metadata SPI to gather information about tables, columns, and types used to validate that the query is semantically valid. The statistics SPI is used to obtain information about row counts and tables sizes to perform cost-based query optimizations during planning. Then, the data location SPI is used in the generation of logical splits of the table contents.
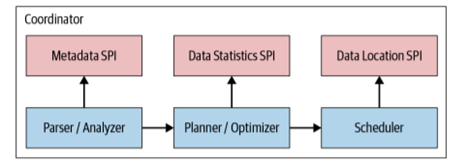
Figure 2. The service provider interfaces for query planning and scheduling
The coordinator breaks up the plan to allow processing in parallel to speed up the overall query. That creates more than one stage and results in the tree of stages. The number of stages depends on the complexity of the query.
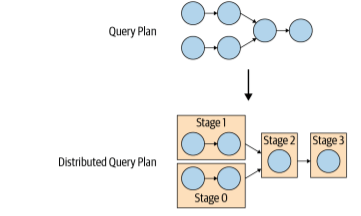
Figure 3. Transformation of the query plan to a distributed query plan
Further, the coordinator uses the distributed query plan to plan and schedule tasks across the workers. As said earlier, each stage consists of more tasks, out of which each processes a piece of data. The tasks are assigned to the workers in the cluster, as shown in Figure 4.
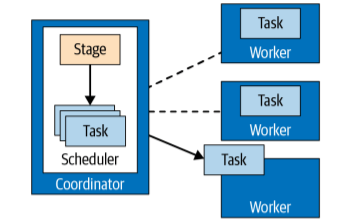
Figure 4. Task management performed by the coordinator
The unit of data task processes is called a split. A split is a descriptor for a segment of the underlying data that can be retrieved and processed by a worker. Tasks at the source stage produce data in form of pages that make a collection of rows in columnar format. Pages are transferred between stages by exchange operators. Operators process and produce pages according to their semantics. For example, filters drop rows, and projections produce new derived columns.
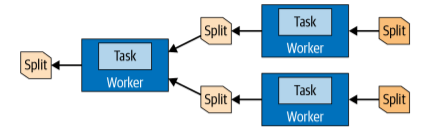
Figure 5. Data in splits being transferred between tasks and different workers
A task is a runtime incarnation of a plan fragment when assigned to a worker. After the creation of the task, it will instantiate a driver for each split. Each driver represents a pipeline of operators and performs the processing of the data in the split. Once all drivers in a task are finished and data passed to the next split, the drivers and the task are destroyed.
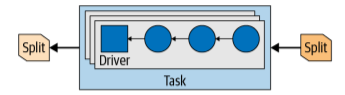
Figure 6. Parallel drivers in a task with input and output splits
Once all splits are processed, all data is available, and the coordinator can make the result available to the client.
Trino federated queries
select
a.symbol,
max(b.d_date)
from
postgres.crypto.crypto_data a,
tpcds.sf1.date_dim b,
hive.crypto.crypto_data c
where
a.date = b.d_date
and c.date_hive = b.d_date
group by
a.symbol
order by
a.symbol desc ;
This is an example of a Trino federated query when using multiple heterogeneous sources, like Postgres, Hive, and TPC-DS. Before writing this kind of federated query, the only thing you need to set up is to create a catalog for each of these sources for Trino. After this step, we can start writing our SQL queries as explained above in the Trino clients section.
Hive over Trino vs Hive
At its very core, Hadoop consists of the HDFS and application software, such as Hadoop MapReduce, to interact with the data stored in HDFS. Originally, data processing was performed by writing MapReduce programs. Coding was a bit cumbersome for data analysts doing the analysis. It also does not transfer well for existing infrastructure and tooling.
As an alternative for using MapReduce, Hive plays its role. It was created to provide a SQL layer of abstraction on top of Hadoop to interact with HDFS. Hive stores data as files in HDFS in various formats such as ORC, Parquet, Avro, and others. Hive metadata describes how data stored in HDFS is mapped to schemas, tables, and columns for use in SQL. This metadata is stored in a database such as MySQL or PostgreSQL and accessed by Hive Metastore Service (HMS). The Hive runtime provides the SQL-like query language and distributed execution layer to execute the queries. The query is translated into a set of MapReduce programs that run on a Hadoop cluster.
To conclude, we can say Hive is a combination of three components:
- Data files in varying formats that are typically stored in HDFS or S3
- Metadata about how the data files are mapped to schemas and tables – this data is accessed via the HMS
- A query language called HiveQL
Trino uses only the first two components – the data and the metadata. It does not use any part of Hive’s execution environment. Hive connector works a bit differently than other RDBMS as it does not use a source engine to process the query. Instead, it simply uses the metadata in HMS and accesses the data directly on HDFS. It also assumes the Hive table format in the way the data is organized in the distributed storage.
Comparison of Hive, Hive-interactive, and Trino
A Hive connector is added to Trino to query the data through Trino and measure the query execution speed. Also, the query execution speed of Hive and Hive-interactive is measured on the same queries. For those who never heard of Hive-interactive, it consists of a long-lived daemon that replaces direct interactions with the HDFS DataNode, and a tightly integrated DAG-based framework. Shortly, it is a performance booster for Hive queries. Time taken by a single query won’t be as much affected, but when many queries are running simultaneously, they should be handled much better.
Two datasets were used for testing:
- Crypto data which consists of 3807 rows
- 2 GB of TPC-DS data
In the following table, we can see the results of queries ran on crypto data:
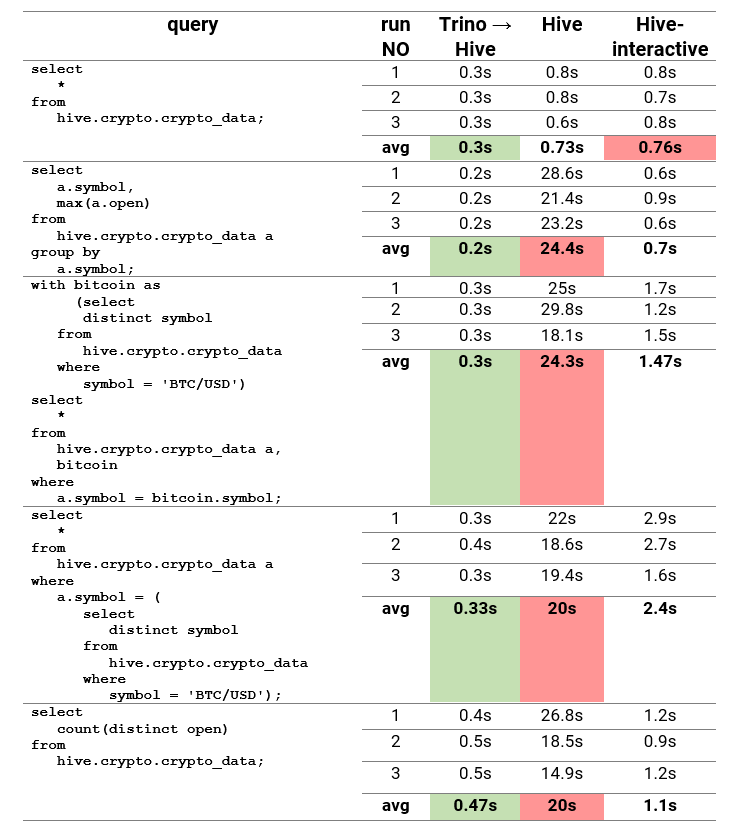
In the second table, we can see the results of queries ran on TPC-DS data:

Due to these results, it is visible that Trino is a lot faster than Hive, even Hive-interactive on pretty much all kinds of queries. The only time Hive-interactive is faster is when we need to re-execute queries. As a result, Trino should be used when supporting polyglot persistence and when you want to run fast queries against HDFS. If the plan is to re-execute queries, Hive-interactive should also be considered as its speed greatly increases after running the same query again.