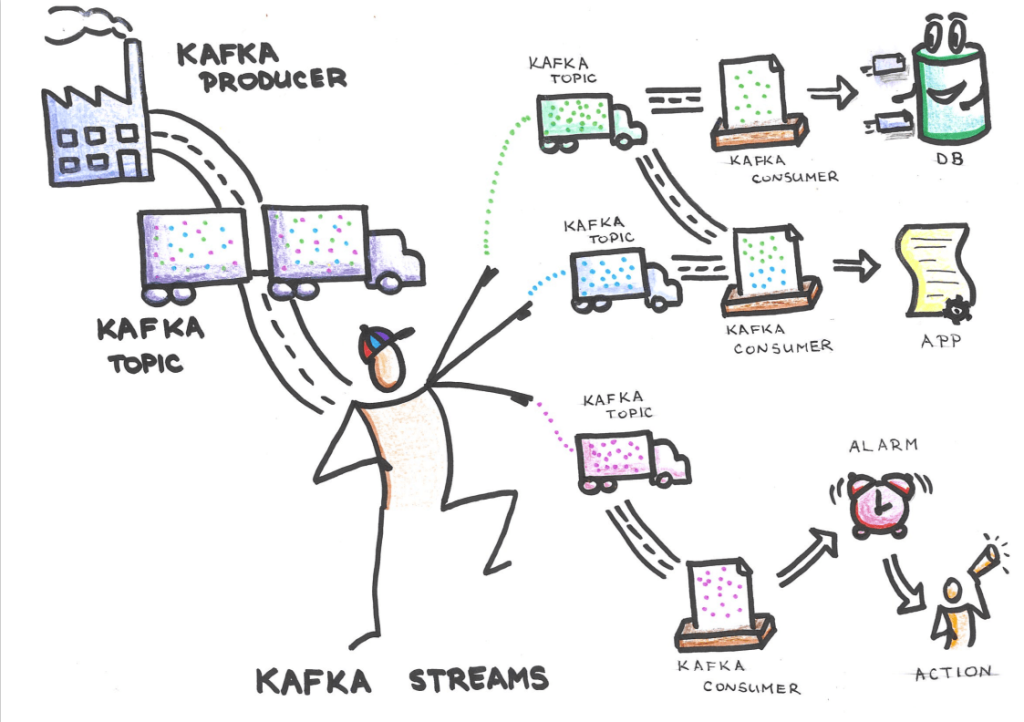
Last time we introduced you to the concept of Streaming Governance. If you missed the first part, check it out here. In this blog, we will give you a more technical insight on how to setup up Streaming Governance using open-source tools alongside a custom application that we developed to enable the whole process.
Let’s take a look at the high-level architecture of the system.
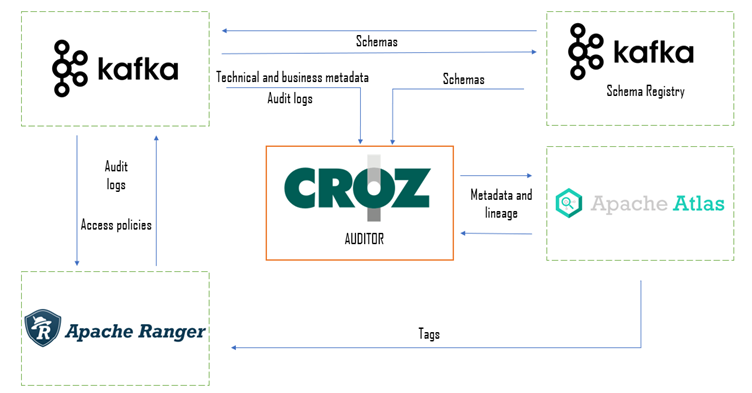
From the picture above we can identify several key components:
- Apache Atlas
- Apache Ranger
- Apache Kafka and Schema Registry
- CROZ Auditor
Each of the listed components plays an important role in the functioning of the whole system. Apache Atlas serves as the core metadata storage. It offers several functionalities: Data Catalog, entity classification and business glossary. Tightly connected to Atlas is Ranger. Using Ranger we secure each entity and restrict access to selected users/roles. Kafka is used both as a target system for the Streaming Governance platform and as audit storage for Atlas. Every change to Atlas metadata is saved as a message to Kafka. The last component is also the most exciting one: a custom metadata audit application that connects all the other components and enables us to get a deep view of the lineage and the metadata that each entity in the streaming system is associated with.
Let’s take a deeper look at the CROZ Auditor. The application, which is based on Java and Spring Boot, is the heart of our system since the Streaming Governance concept isn’t available for Kafka out of the box. To create a catalog of entities and the lineage graph of everything that exists in our Kafka cluster we had to develop a solution that will be incorporated seamlessly into the whole system. Ranger has a key role in achieving this goal. It tracks everything that is happening in our Kafka cluster in form of audit logs. Every action is logged by Ranger and stored as a new message in a dedicated Kafka topic. That allows us to consume this topic and find out all the changes that happened in real-time. After that, the application uses the REST API to communicate with Apache Atlas. Depending on the type of action that has been logged by Ranger, the application will use the appropriate API endpoint to create, update or delete entities in the metadata catalog in Atlas. What is great, is that those entities in Atlas will contain both business and technical information about topics.

Alongside that, new elements will be added to the lineage graph for a given topic each time a new producer or consumer is logged. Another functionality of the application is that it will fetch the schema of every new or updated topic from the Schema Registry and create or update them in Atlas. In the end, that is exactly what we wanted to achieve: real-time streaming governance on top of Kafka, supported by a metadata catalog containing topic and schema information together with a lineage graph that offers a concise view of each topic and how it is used by different processes, people or departments.
The CROZ Auditor plays a big part, but the other components aren’t any less important, so let’s see what needs to be done on that part.
The first step in building the whole system was to install Apache Atlas. Atlas uses Apache HBase and Solr as storage systems. HBase is used as a metadata store, while Solr is used as an index store. When installing Atlas, you can choose if you want Atlas to manage HBase and Solr on its own, or you can install HBase and Solr separately. One key component that works in the background is Zookeeper. Zookeeper’s role is to act as a centralized coordinator that maintains naming and configuration information while providing group services and distributed synchronization. Both HBase and Solr have the option to start their Zookeeper instance on startup. It is better to install Zookeeper separately and simply configure HBase and Solr to use that instance. That way, we will have one Zookeeper instance used by all services. Keep in mind that before starting the services, it is necessary to create 3 different collections in Solr that will be used by Atlas. Without that, Atlas won’t be able to start successfully.
Now it’s time to install Apache Ranger. The installation process of the core application has a few important steps. First, it is necessary to install Postgresql as metadata storage for Ranger. That step includes creating a few databases and users, setting up the JDBC connection and running the setup script that will prepare the databases for usage. Ranger also needs to be connected to Solr. That is because all the audit logs will be stored in Solr, in a separate collection. Apart from the core application, Ranger requires the installation of 2 plugins and 2 smaller components. The components in question are Ranger Tagsync and Usersync. Usersync is used to sync users from a few different possible sources: Unix, LDAP or AD. With users synced to Ranger, it’s possible to grant permission to them over resources. On the other hand, Tagsync is used to sync tags from Atlas. Tags allow users to classify entities based on their importance, type or some other attribute. When Tagsync is enabled, Ranger can be used to restrict/allow access to entities based on their classification. For example, it’s possible to allow only a selected group of users to access entities in Atlas classified as Confidential, all from within Ranger using Tag Based Policies. But to control access to Atlas from Ranger, the first of two plugins must be installed: the Ranger Atlas plugin. This plugin must be installed on the host machine where Atlas is running and it must be configured to connect to Ranger and both Solr and its Zookeeper instance. One property must also be configured in Atlas that will dictate which authorizer is used. In this case, it’s Ranger.
The second plugin is for Kafka. It will allow Ranger to restrict access to the Kafka cluster and its topics.
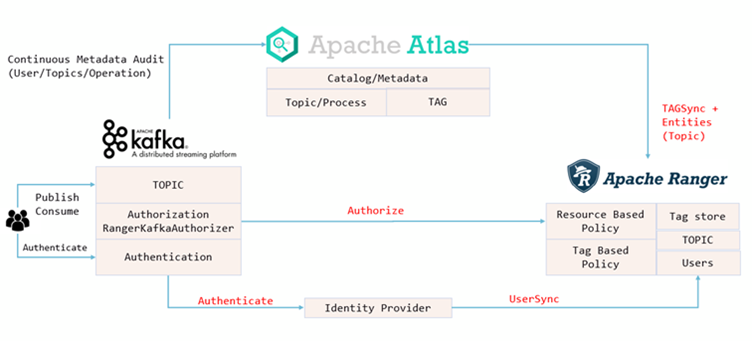
Same as for the Atlas plugin, the connection to Ranger, Solr and Solr’s Zookeeper must be established. The plugin must be installed on each Kafka broker. One crucial step in the configuration of the entire system is to enable Ranger to send audit logs to Kafka. This can be set in the plugin’s configuration. A different solution would be to use a custom logger configured within Kafka itself.
That’s it. Now you know all that it takes to create a Streaming Governance solution for Kafka. To sum everything up, by creating a custom CROZ Auditor we were able to fill the missing pieces in creating a secured and governed Kafka cluster, that provides us with all the metadata and lineage information that we need. With the approach of creating a custom solution, we will also be able to implement new functionalities in the future, as our requirements grow.