Fine-tuning these models requires access to large, representative, and high-quality datasets. If you don’t have access to these kinds of datasets, the next best way is to synthesize them using AI. However, when generating programming code or other text in rigorous formats, it is critical that the final model produces synthetically and semantically correct output. Deviation in syntax typically leads to significant issues, where a single error can reduce user’s confidence in the AI assistant, introduce hard-to-find bugs, or even render the entire solution unusable. Therefore, a methodical approach to both defining problems and generating meticulously accurate solutions is paramount.
Combined approach to Synthetic Datasets using a capable LLM and program translation
To address the challenge of generating correct and reliable code using LLMs, we developed a structured approach that synthesizes problems and solutions. Our method follows these steps:
- Define the Problem Space: We begin by defining the rules that outline the problem space we aim to address. With these rules we include the constraints and the elements that can be used to construct a solution for each of the problems.
- Curate the Core Problem Prompts: Within the defined problem space, we hand-craft a core set of well-curated problem prompts—these could be questions or tasks that represent the challenges we want to solve.
- Expand Problem Dataset Using an LLM: At this point we utilize a capable cloud LLM to expand the core set of problem prompts. The LLM takes the core problems as examples and generates a broader set of related yet novel problems.
For each of these problem statements we apply the process illustrated with the following diagram:
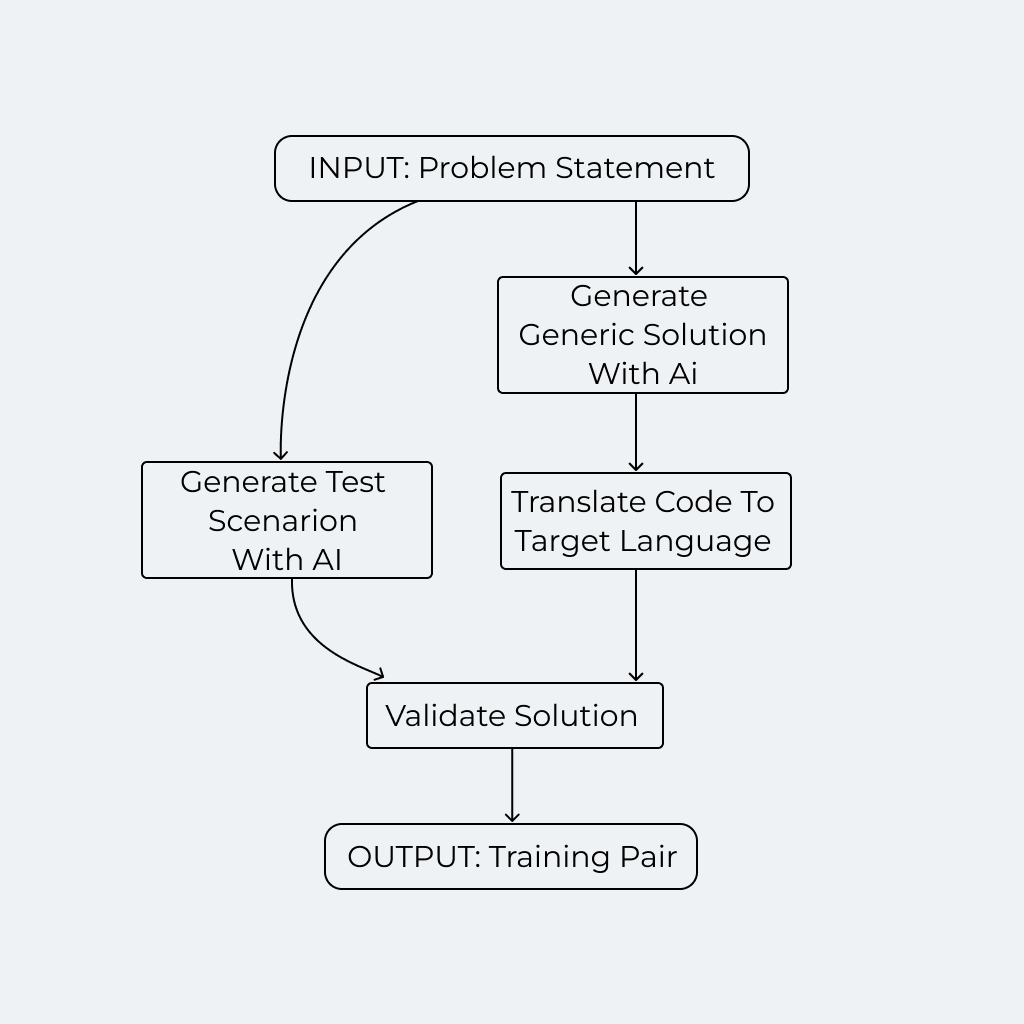
Let’s look at each step in more detail:
- Generate Generic Solutions with AI: We first use a capable cloud LLM to generate a generic solution. This solution is structured as an abstract tree using a JSON schema that outlines the key components and logic required to address the problem.
- Translate Code to Target Language: Convert the generic solution into code in the target programming language using a custom-written serializer. This step ensures that the abstract solutions provided by the LLM are translated into executable code.
- Generate Test Scenarios with AI: Use the LLM to generate test scenarios for the given problem. These scenarios are crucial for validating the correctness of the generated code.
- Validate Solution: Check the correctness of the solution code using the generated test scenarios. Only problem-solution pairs that pass all test scenarios are retained in the dataset, ensuring a high level of accuracy and reliability.
The generic solution meta model is designed to act as a bridge between different domains. It is structured in a way that is familiar to the LLM, allowing it to reliably generate abstract solutions, while also being readily translatable into the target programming language.
Use Case: support for a niche programming language
Recently, a client approached us with the challenge of fine-tuning an LLM to answer questions related to a specific, less-known programming language. This LLM should be based on an open model that would be deployed on premises. The issues were twofold: existing LLMs had poor support for this language, and there was no readily available training dataset for it.
To illustrate our approach in this article while protecting client privacy, we will use another less-known programming language, LOLCODE, as a substitute. Though LOLCODE is intentionally esoteric and humorous, it serves as a useful example to illustrate our method’s effectiveness.
Zero-shot solutions from GPT
Let’s see how this works out for an entry-level sample. Take a short problem statement:
signum of difference between two numbers
Signum function is a mathematical concept that maps any real number to zero, plus or minus one if the argument is zero, positive or negative, respectively. Neither Python nor LOLCODE have this function built in. Therefore, the LLM must first understand the intent of the problem and the work around the limitations of the generic procedural programming model we are using, as it is defined.
When using GPT-4o to generate a LOLCODE solution, the program may seem promising at first. However, upon closer inspection, it contains several critical issues.

In fact, there are three major errors in this simple program that will prevent it to execute at all (marked red on the listing):
- DIFF is a keyword in LOLCODE so naming the variable DIFF won’t work
- Syntax for subtraction is incorrect, it should be “DIFF OF NUM1 AN NUM2”
- Expression for number comparison is wrong
These are not large issues on a conceptual level, but they seem to be hard to root out without training on many examples. Also, they tend to occur in even greater numbers for problems which are more complex.
Trying out the combined approach to synthetic datasets
Instead of directly using an LLM to generate the complete code, let’s try to LLM capabilities to provide only the generic solution. One generated in JSON format by GPT-4o model (with predefined JSON schema) is shown here:
{
"steps": [
{
"type": "input",
"description": "Prompt the user for the first number",
"prompt": "Enter the first number:",
"variableName": "a"
},
{
"type": "cast variable",
"description": "Cast the first input to a float",
"variableName": "a",
"datatype": "float"
},
{
"type": "input",
"description": "Prompt the user for the second number",
"prompt": "Enter the second number:",
"variableName": "b"
},
{
"type": "cast variable",
"description": "Cast the second input to a float",
"variableName": "b",
"datatype": "float"
},
{
"type": "variable assignment",
"description": "Calculate the difference between the two numbers",
"variableName": "difference",
"assignedValueExpression": "a - b"
},
{
"type": "if-else",
"description": "Determine the signum of the difference",
"conditionExpression": "difference > 0",
"thenSteps": [
{
"type": "variable assignment",
"description": "Assign 1 to signum if difference is positive",
"variableName": "signum",
"assignedValueExpression": "1"
}
],
"elseSteps": [
{
"type": "if-else",
"description": "Check if the difference is zero",
"conditionExpression": "difference == 0",
"thenSteps": [
{
"type": "variable assignment",
"description": "Assign 0 to signum if difference is zero",
"variableName": "signum",
"assignedValueExpression": "0"
}
],
"elseSteps": [
{
"type": "variable assignment",
"description": "Assign -1 to signum if difference is negative",
"variableName": "signum",
"assignedValueExpression": "-1"
}
]
}
]
},
{
"type": "print",
"description": "Print the signum of the difference",
"stringExpression": "signum"
}
]
}
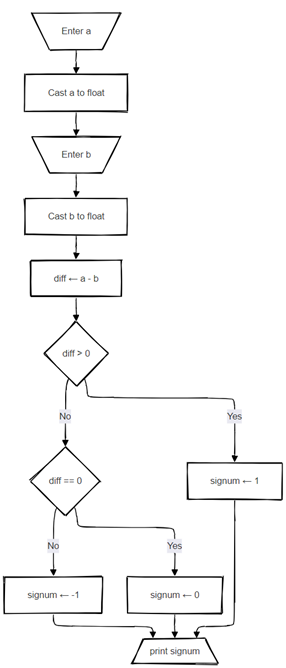
This construction represents a correct procedural solution that can be written in practically any popular programming language of today. For easier viewing, the same algorithm is drawn here in a form of a flowchart:
Code translation
To produce a working program in the target language, we implemented a translator component that converts the generic solutions generated by the LLM into LOLCODE. This process involved the development of a meta model in two key parts:
1. Statements in a Generic Procedural Language: This generic algorithm includes the basic building blocks of a programming language, such as variable declarations, assignments, input/output, and control structures like IF-ELSE statements. The translation process can check for some semantic consistencies, such as declaring all variables before referencing them.
2. Expressions in Python: This component handles simple expressions, such as arithmetic and logic operations, comparisons, and string concatenations, expressed in Python. Modern state-of-the-art LLMs are well-versed in Python, so this is an ideal choice for connecting generic procedural language with LOLCODE.
Generated hierarchical JSON structure is serialized into LOLCODE statements, while Python expressions are parsed into an Abstract Syntax Tree (AST) and then translated into LOLCODE expressions. This translation ensures that the final code is syntactically flawless:
HAI 1.2
I HAS A a
I HAS A b
I HAS A diff
I HAS A signum
VISIBLE "Enter the first number:"
GIMMEH a
a IS NOW A NUMBAR
VISIBLE "Enter the second number:"
GIMMEH b
b IS NOW A NUMBAR
diff R DIFF OF a AN b
DIFFRINT diff AN SMALLR OF diff AN 0, O RLY?
YA RLY
signum R 1
NO WAI
BOTH SAEM diff AN 0, O RLY?
YA RLY
signum R 0
NO WAI
signum R -1
OIC
OIC
VISIBLE signum
KTHXBYE
Quality assurance
The final step is running the generated LOLCODE solutions in test scenarios produced earlier by the capable LLM. For our example problem statement, GPT-4o generated these test scenarios:
| test scenario description | inputs | expected output |
| The difference is positive, so the signum is 1. | [5, 3] | 1 |
| The difference is negative, so the signum is -1. | [3, 5] | -1 |
| The numbers are equal, so the difference is zero; hence the signum is 0. | [5, 5] | 0 |
| The difference (0 – 100) is negative, so the signum is -1. | [0, 100] | -1 |
| The difference (-10 – 10) is negative, so the signum is -1. | [-10, 10] | -1 |
| The difference (10 – (-10)) is positive, so the signum is 1. | [10, -10] | 1 |
| Both numbers are equal negatives, so the difference is zero; hence the signum is 0. | [-5, -5] | 0 |
| Both numbers are zero, so their difference is zero and the signum is 0. | [0, 0] | 0 |
| Both numbers are equal floating points, so their difference is zero; hence the signum is 0. | [3.5, 3.5] | 0 |
Each solution needs to run correctly and pass all test scenarios to be included in the final training set, which validates the solution. In our example, all tests pass.
In broad terms, there are five plausible points of failure in our workflow:
- LLM fails to construct a well-formed generic algorithm.
- A well-formed generic algorithm contains a semantic error that is discoverable in serialization phase.
- The generic algorithm has a logical error that is discoverable in the testing phase.
- Some scenarios contain an error that causes a test of a correct solution to fail.
- Test scenarios and the testing process do not cover all errors present in the solution.
Note that only the last point of failure would lead to inclusion of an invalid solution into the final dataset. Even this can be ameliorated by generating larger sets of test scenarios.
Of course, any intervention that increases rigor of the quality assurance process can significantly reduce the output dataset from the number of inputs. However, the ability to synthesize an arbitrary large number of problems of varying complexity should remedy that.
Next steps
Even though we have demonstrated creating a synthetic dataset containing programming problems and solutions, formal output is not limited to programming code. Other uses cases might be XML documents conforming to a specific schema, particularly structured text formats on legacy systems, or symbolic constructs that is used as input into some formal system.
As long as automatic translation from the generic solution to a specific format is feasible, this approach can be widely applied. The potential to scale this methodology across various programming languages and formal systems opens new avenues for innovation in LLM development. By fine-tuning open models on synthetic datasets, we are paving the way for more specialized and reliable AI solutions, tailored to meet the unique demands of any organization or domain, that can be affordable to run on premises.