

Delta Lake provides great features and solves some of the biggest issues that come with a data lake. On top of all, it is easy to use! Keep reading this post for some useful tips and tricks.
To be able to do Big Data analytics you need a lot of data. Also, you need a place to store all that data. That’s were data lake comes in as a central repository system for data storage. Together with common structured data like the one in relational databases, it can also store semi-structured data (CSV, XML, JSON), unstructured data (emails, documents, PDFs) and even binary data (images, audio, video). The data lake enables us to collect every kind of data in any format, store it all, use it all and extract value from it by using data science and machine learning techniques.
One of the biggest issues with data lakes is maintaining data quality. If you collect “garbage” data, “garbage” is stored and machine learning models are producing “garbage” results. You fail to extract real value from data. This usually happens to unorganized and unstructured data lake projects, which fail to implement procedures to maintain data quality. All this leads to one thing nobody wants to see – data swamp. Data swamp is a deteriorated data lake, unusable by the intended user and it provides little to no value.
Need help with data management and architecture? Get in touch!
Let’s see how a typical data lake project looks like and what kind of challenges it brings. Suppose you collect data with Kafka (it applies to any other data source or message queue) and you are expected to implement two things:
- Streaming analytics – to see what’s going on with data in real time
- Batch data – to collect all data and store it into a data lake so that it can be used for AI and/or reporting
How to solve this problem? Let’s try to solve it issue by issue as they occur.
- Batch and streaming – fortunately, this kind of data-processing architecture already exists and it’s called Lambda architecture. It is designed to handle massive quantities of data by taking advantage of both batch and streaming-processing methods. Choose the technology you want to use to implement this kind of architecture. Well, we at CROZ may be a little biased, but we love Apache Spark. Apache Spark is a unified analytics engine for large-scale data processing. It has both streaming and batch capabilities, with many other analytics features. If you want to learn more check out our beginner and advanced Apache Spark courses.
- Messy data – what happens if messy data enters the system? “Garbage” data is stored and it is impossible to extract needed or wanted value. How to fix this problem? You can create new Spark jobs to validate the data. If some of the existing data breaks the given rules, you can forbid those values to enter the system or do some other data processing.
- Mistakes and failure – even with validation jobs there is always room for error. You need to make sure that it is possible to reprocess part of the data if any error is found. To do that you need partition data by date – that allows you to just simply delete corrupt data and start loading it again with Spark job.
- Updates – in the last couple of years data privacy regulations like GDPR have become stricter. What happens if someone wants to be “forgotten” from the existing data lake? You need to enable updates in the system. Again, that can be done with Spark. But you need to be extra careful that someone isn’t using the data you are planning to change.
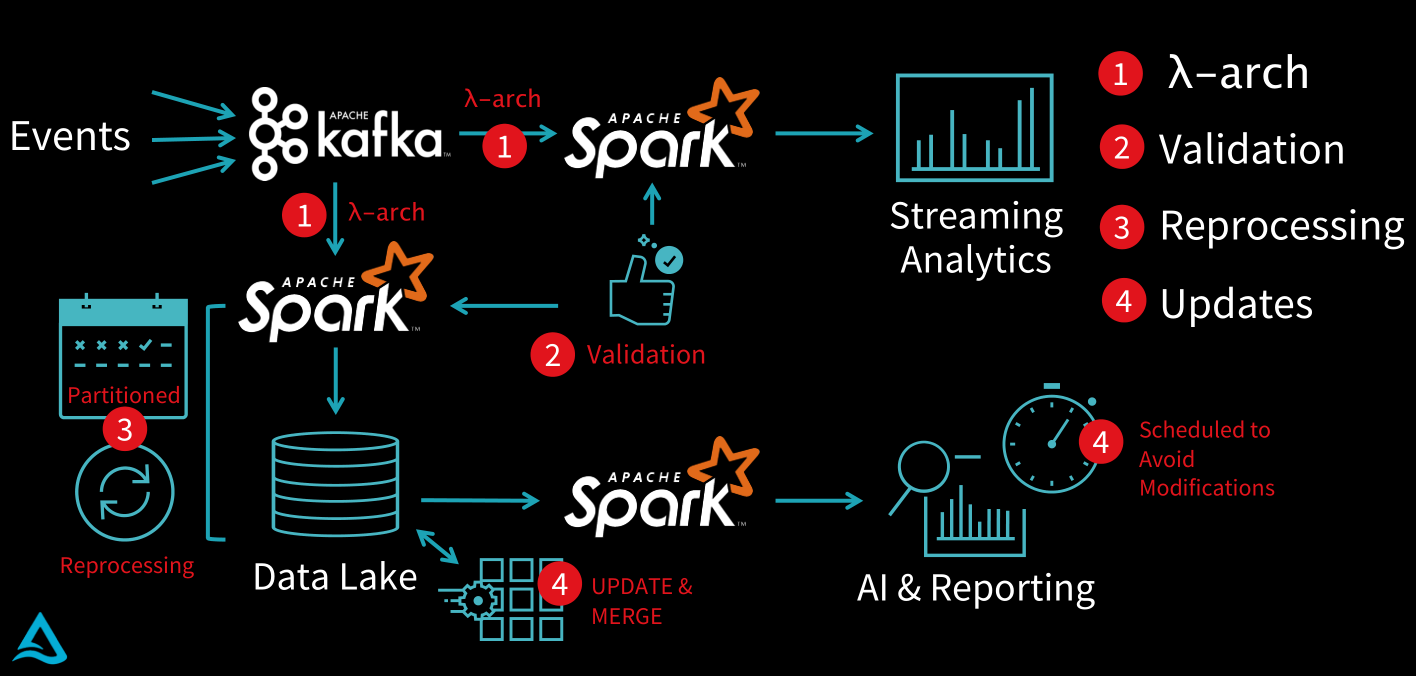
Figure 1. The thing to look out for in data lake projects, Source: Databricks [1]
- Phew, that was a lot of things to take care of. As you can see, the mentioned data lake distractions require some extra work. No atomicity means failed jobs leave the data in a corrupt state requiring tedious recovery. No quality enforcement creates inconsistent and unusable data. No consistency and isolation make it impossible to mix batch and stream. Why wasting time & money on solving system problems when instead you could have been extracting value from data. Wouldn’t it be easier if there was a technology that can help us do that?
Delta Lake to the rescue
Luckily there is a solution, and to double the luck, it is designed to be 100% compatible with Apache Spark. The technology in question is Delta Lake, an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads.
Delta Lake unifies batch and streaming source and sink, enabling you to create a single flow of data that allows users to focus on data quality throughout the process of moving the data. The idea is to create different data quality zones, improving with each step.
As mentioned, this kind of setup increases the capability of an organization to ensure that high data quality exists. The concern for this capability is a well known data management concept called data governance and its key focus areas are data availability, data usability, data consistency, data integrity and data security.
Databricks proposes example [1] consisting of three different zones: bronze, silver and gold. The bronze zone would be the dumping ground for raw data and data is stored for a long time there. The next level would be the silver zone where some basic cleaning and preparation of data would be applied. And in the final gold zone, you would have the clean data ready for consumption by your analytics team or machine learning models. With this kind of setup, problems that would occur before in data lake are much easily solvable. For reprocessing, you simply delete tables from the zone you want to reprocess and restart the stream. And since there is already the data ready in the previous zone, you don’t have to go through the entire process of loading data. Delta Lake supports standard DML (data manipulation language) which makes it easier for doing any kind of updates, deletes, inserts and even merges.
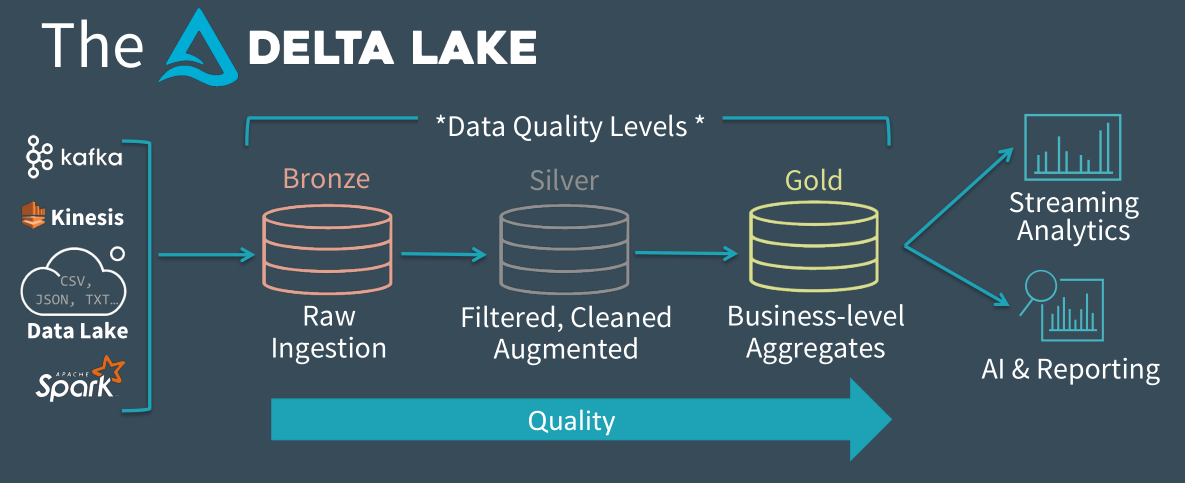
Figure 2. Data quality zones with Delta Lake, Source: Databricks [1]
Now you are probably thinking; this is all great but I still need to have validation jobs between zones to check whether the schema of data hasn’t changed. Again you are in luck with this solution. Alongside having already mentioned ACID capabilities, Delta Lake gives other great features: schema enforcement and schema evolution. Schema enforcement allows you to specify the schema and enforce it. This helps ensure that the data types are correct and required columns are present, preventing bad data from causing data corruption. Or you can specify schema evolution, which is a feature that changes a table’s current schema to accommodate data that is changing over time.
Audit history and time travel are also very useful features. Delta Lake transaction log records details about every change made to data providing a full audit trail of the changes. And with time traveling, you can easily revert to an earlier version of data for any kind of reason. Maybe you want to do some auditing, or you found some error and want to rollback to the uncorrupted version of data, or you just want to do simple experiments. You are free to do it.
Delta Lake provides great features and solves some of the biggest issues that come with a data lake. On top of all, it is easy to use and can be implemented with existing pipelines with minimal changes. Since Delta Lake is still work in progress, there are many new features you can expect.
We at CROZ are excited to see what future brings with Delta Lake and are hopeful that it will make data lake projects more fun for us and our customers.
Reference
[1] Armbrust M., Making Apache Spark™ Better With Delta Lake [Webinar]. Databricks.

