

Every IT manager and software engineer knows about the costs and risks of outdated tech. These lines of outdated code often contribute to a company’s crippling technical debt, stifling innovation and slowing down change. Both computer science and the industry’s best practices are advancing all the time, developers often leave behind code that they wrote when they leave the company, and new recruits can be slow or unwilling to fully adopt the IT landscape that is already obsolete.
However, legacy code often has huge business value. This code represents years of accumulated knowledge, experience, and business rules that are critical to the company’s operations. That’s why we can’t just throw away the legacy code. Instead, we need to modernize the code while preserving its business value, ensuring that we leverage the strengths of the existing system while integrating new technologies and practices.
Modernization levels
When we are discussing modernization, we are usually talking about one or more levels of intervention:
- Refactoring involves improving the quality of the internal organization of the existing code without changing its external behaviour. The main goals are reducing technical debt on a smaller scale, and enhancing readability of programming code, navigability, and maintainability of software codebases.
- Rearchitecting involves making fundamental changes to the system’s architecture. This may include breaking a monolithic system into smaller services or adopting more scalable architecture. The main goals of rearchitecting are improved scalability and better alignment with modern deployment practices.
- Reengineering is a complete technological overhaul of the system. The primary goal of reengineering is to transform existing systems to meet modern standards significantly.
Each of these brings its own risks and rewards. Refactoring is done in smaller increments and is less risky compared to rearchitecting and reengineering.
Mainframe Code Modernization
Mainframe modernization is a broad and multifaceted subject that extends far beyond merely updating code. It addresses multiple areas, including updates to infrastructure and database design, development of new integration layers, and improvements in code management, development tools, and DevOps practices.
Additionally, modernization can include integrating mainframes into hybrid-cloud environments and implementing modern software concepts like containerization.
Mainframe source code is typically written in languages such as COBOL or PL/I, with a significant amount of assembler code also in use. A common misconception is that the primary challenge lies in mastering the COBOL language itself. However, this is not the case in most instances. COBOL, as a programming language, is straightforward and can be learned relatively quickly by anyone with a programming background.
Typically, mainframe customers want to keep COBOL (or PL/I) but aim to refactor, rearchitect, or reengineer existing code. (I will not discuss the not-so-rare cases where the source code is lost or unavailable.) The first real challenge often lies in understanding the existing codebase, data, and program execution flow in complex mainframe environments that often include CICS or batch processing, multiple data sources, and intricate integrations.
This is where advanced technologies like knowledge graphs and artificial intelligence (AI) can play a crucial role. These tools can help decipher complex code structures and provide insights that facilitate the modernization process. By leveraging AI and knowledge graphs, organizations can overcome the hurdles of code comprehension and move forward with their modernization efforts more effectively.
Modernization challenges
Typical pitfalls of modernization efforts include:
- As with any interventions in code, these changes can introduce new defects, function drift, or loss of function, especially for codebases that have poor test coverage.
- Warping the original intent of the system while keeping the bulk of functionality intact. This might lead to subtle changes of function in edge cases, causing logical errors in further inference.
- Shallow transformations can have the effect of keeping the same old code behind a fresh facade. The goal of modernization is not just to change the syntax or to use the functions from another library. Transformation must take care to match the target paradigm, and conventions, and to use appropriate language idioms so that the new codebase matches the expectations and skillset of that community.
Building a Knowledge Graph of a Legacy System
What is a knowledge graph?
A knowledge graph is a single data structure that is generic and flexible and can hold all information relevant to understanding an IT system. Rather than scattering multi-level information across disparate documents, source code files, and databases, a knowledge graph brings them together under a single paradigm.
Knowledge graphs have nodes that represent concepts and edges that describe relationships between those concepts. Concepts can range from abstract to concrete, business to technical, and coarse to fine-grained. A node can stand for a specific class in an object-oriented programming language, a specific table in a relational database, or a specific variable in code. Also, another node can represent the business concept that is embodied in these technical constructs. Connections between nodes can also be applied to different tiers of relationships.
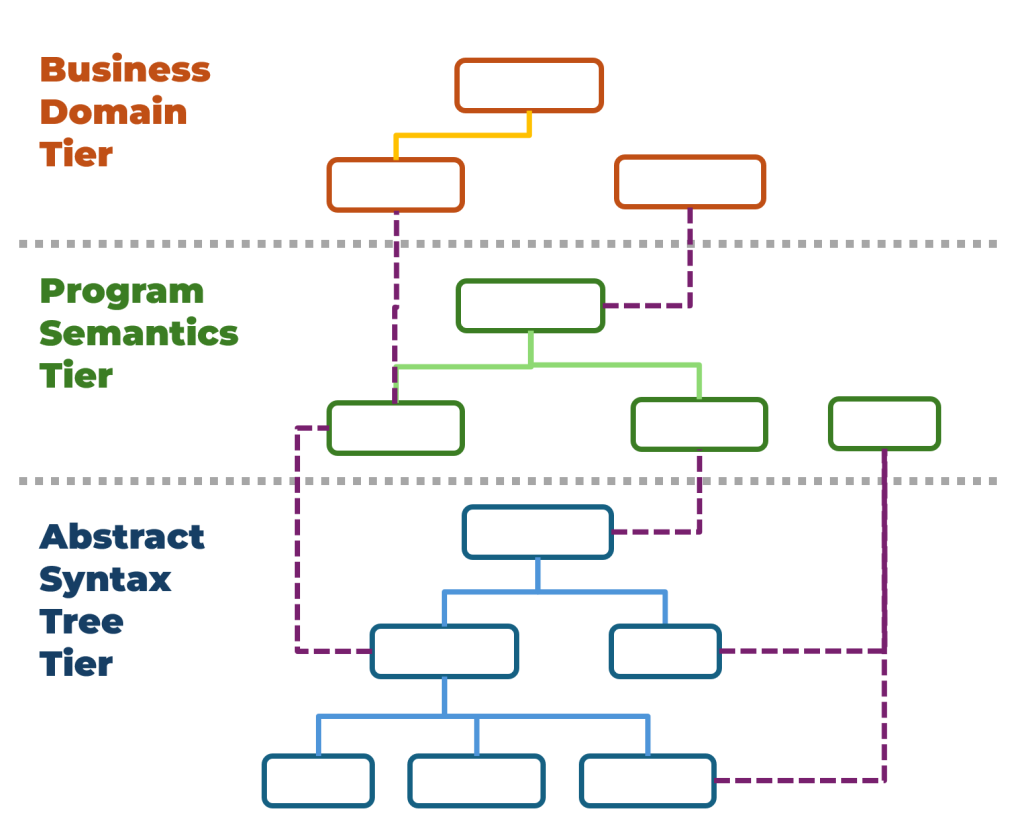
The knowledge graph doesn’t need to be perfect, in the sense that it covers all relevant information in the minds of people involved, organized in the exact way things are organized in the business environment. The information captured can be just enough to enable the completion of specific tasks — and it should be continuously improved as it proves to be lacking in some aspects.
Sources of knowledge
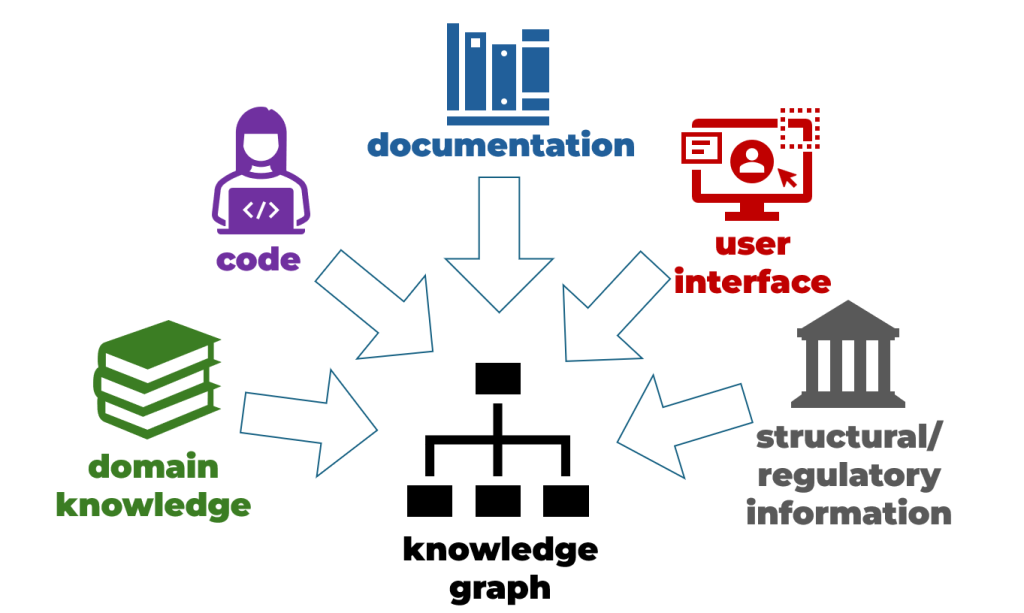
From where do we extract the knowledge to put in our graph? Here are some typical sources:
- The most important part is the source code. We need to ingest all our existing programming code to capture core logic and technical workflows. This also includes resources that aren’t written in a programming language, like configuration files. These can be broken down into lower-level constructions by parsing the text into abstract syntax trees (ASTs).
- Project documentation, ranging from technical specifications to user manuals, provides essential context for the source code.
- Renders of user interface: the visual structure of the part of the application that is oriented towards human users. When documentation is lacking, these images can reveal relevant details that are apparent to the people most involved in its operation.
- Application domain knowledge: Insights from subject-matter experts that reveal the wider, giving insight into the terminology that is used and relevant business functions. These might include books and whitepapers, educational courses, and Wikipedia articles.
- Structural and regulatory documents: This can be key for compliance-heavy industries where systems must adhere to strict standards. Corporation-level rules are also applicable here.
Workflow for a knowledge graph
In general, the workflow looks like this:
- Ingestion of all source information into the graph.
- Developing ontologies and required meta-models of the knowledge graph.
- Inferring new concepts and relationships from the existing parts of the graph expands the knowledge.
- Querying the knowledge graph using explicit or semantic search techniques.
Information obtained in such a way is useful in many applications. In the following section, we will investigate how it’s relevant to code modernization.
Building a graph
An Essential task when building a graph is finding an information-preserving mapping between the legacy conceptual framework and the graph and another between the knowledge graph and the target concepts. As the knowledge graph is semi-structured by nature, it should be easier to mold so that it fits the needs of both mappings.
The graph is built semi-automatically, using both procedural and AI tools for ingestion and structuring, as well as by hand-crafting or rearranging parts of the graph.
Technologies from the realm of artificial intelligence that play an important role in such are mostly ML models ranging from smaller embedding models to very large multimodal generative models. Embedding models can be used to gauge semantic similarity between snippets of text or other content, and relations between them. Multimodal generative ML models, primarily those with state-of-the-art language capabilities, bring additional functionality:
- Automatic text processing, on some level even “understanding” of text in natural languages.
- Extracting information from diagrams, UI renderings, and other graphic media.
- Text generation, especially the generation of documents in formal languages and explicit logical constructs.
- Reasoning capabilities allow for logical inferences and a degree of problem-solving.
How the knowledge graph helps with the code modernization
We can use the built knowledge graph to help software engineers convert legacy code into a form that’s at least closer to our target technology. The questions we seek help with:
- What was the intent of the systems architect, component designer or programmer behind a particular decision?
- What is the function of this component or code segment, described both in terms of the problem domain and the implementation?
- How can the codebase be structured and organized? What information needs to flow between those segments?
Answers to these questions are in line with the following goals:
Mapping relationships: Use the knowledge graph to reveal and map relations within the legacy code, such as shared data structures, functions, and workflows.
Supporting software engineering: The graph helps software development teams understand which parts of the system are associated with other concepts at different levels of abstraction.
Guiding the re-architecture efforts: Identify where architectural changes will provide the greatest value, for instance, in shifting to microservices or modular architecture.
Retrieval-augmented generation based on knowledge graphs
An essential part of reaching those goals in AI-enhanced knowledge management is the Retrieval-Augmented Generation (RAG) approach. The graph database version of this augmentation is predominantly done using two techniques:
- Finding the most relevant nodes in the graph using semantic search. This uses embedding models and LLMs.
- Growing the subgraph from the anchor nodes by following a fan-out strategy based on the plan given by the reasoning model.
This information is then served to the machine learning model that can formulate the answers in natural language, or a predetermined information structure based on its training data, given context from the knowledge graph, and the question itself. This approach variant is often called “Graph RAG”.
Use cases of code modernization
Knowledge graphs can be used in refactoring/reengineering tasks in a myriad of ways. Here there are just a couple of use cases.
Discovering unused code. This is simple: just find parts of the graph that have no dependency relations coming from active code.
Improving modularity. Finding a subgraph that shows high interconnectivity between internal nodes of the subgraph and low connectivity with outside nodes, especially with no cyclical dependency relations leaving the subgraph.
Reducing repetition and redundancy. Finding a pattern in the graph that repeats in whole or in part with corresponding constructs in different sections of the codebase.
Determining the relative importance of components. This can be calculated from relations between technical-level nodes and the business-level nodes that represent important business concepts, as well as dependency relations.
Generating additional documentation. As we have used all available information to try and construct the knowledge about the working system, we might now have enough to infer and generate some human-readable documentation on parts of the system that were
Generating tests. Knowledge about the structure, function, and interaction of all components can allow for easier generation of test scenarios and acceptance tests.
Challenges in implementing this approach
While the approach described here is powerful, its implementation is not without its challenges. Common issues/pain points include:
- Obtaining all the source code, documentation, UI artifacts, and standards can be difficult from an organizational and technical point of view.
- Data ingestion from sources that contain content other than linear text can be a daunting task.
- Incompatibility between different sources of information, as well as using different languages, inconsistent terminology, and contradictory statements.
- Outdated documentation and similar issues with source material quality. Non-executable accompanying information tends to be neglected in the later phases of the project, especially during maintenance.
- Constructing metamodels on the core information in the graph requires human experience, expertise and the willingness to make opinionated decisions. As a result, the result might differ based on arbitrary choices.
- The more we use the knowledge graph to detect patterns, redundancies, and discrepancies, the more we need to “fill up the holes” in it. For sparsely documented codebase this can require a lot of effort.
A path forward
Knowledge graphs provide a ground-up approach to legacy system modernization, enabling systems transformation safely, efficiently, and in alignment with the core goals of preserving function and reducing technical debt. By embedding these insights into ongoing development and governance practices, organizations can foster a culture of continuous improvement and ensure their technology remains resilient and adaptable in a rapidly evolving digital landscape.



